前言
E站爬虫在网上已经有很多了,但多数都只能以图片为单位下载,且偶尔会遇到图片加载失败的情况;熟悉E站的朋友们应该知道,E站许多资源都是有提供BT种子的,而且通常打包的是比默认看图模式更高清的文件;但如果只下载种子,又会遇到某些资源未放种/种子已死的情况。本文将编写一个能自动检测最优下载来源并储存到本地的E站爬虫,该爬虫以数据库作为缓冲区,支持以后台服务方式运行,可以轻易进行分布式扩展,并对于网络错误有良好的鲁棒性。
环境要求
Python3,MySQL,安装了Aria2并开启PRC远程访问
Aria2是一个强大的命令行下载工具,并支持web界面管理,可以运行在window和Linux下。介绍及安装使用可参见
基础配置
在MySQL中按如下格式建表
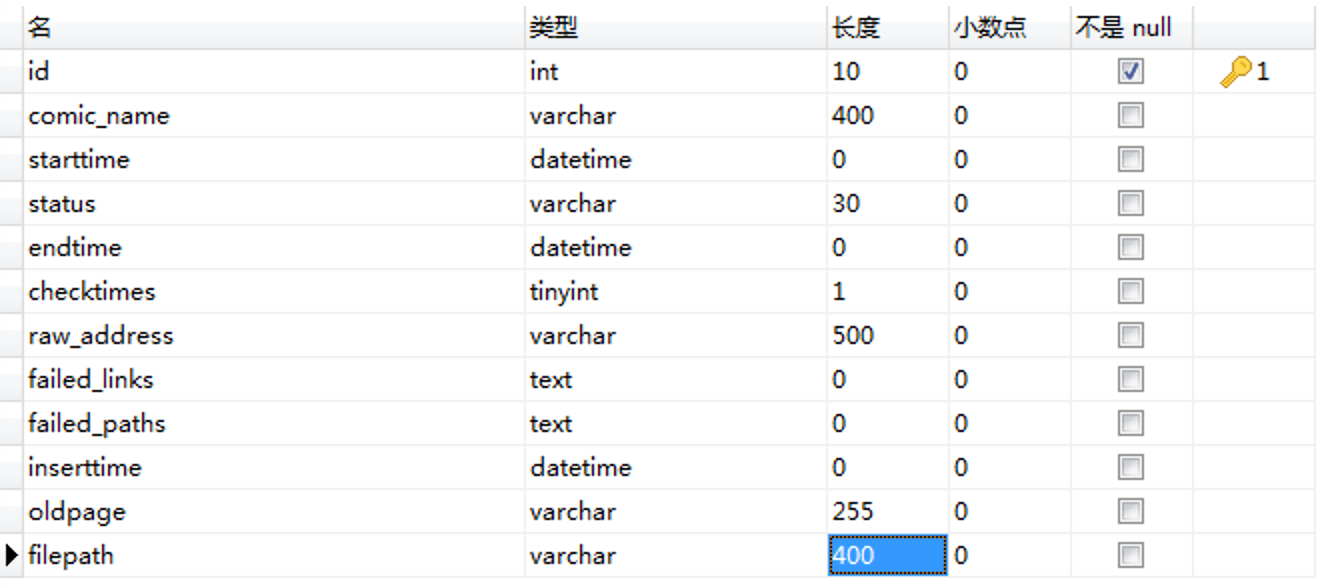
| 字段名称 | 字段意义 |
| id | id主键 |
| comic_name | 本子名称 |
| starttime | 开始下载的时间 |
| endtime | 下载结束的时间 |
| status | 当前下载状态 |
| checktimes | 遇错重试次数 |
| raw_address | e-hentai页面地址 |
| failed_links | 记录由于网络波动暂时访问失败的页面地址 |
| failed_paths | 记录失败页面地址对应的图片本地路径 |
| inserttime | 记录地址进入到数据库的时间 |
| oldpage | 存放Aria2条目的gid |
| filepath | bt下载路径 |
本文之后假设MySQL数据库名为comics_local,表名为comic_urls
aria2配置为后台服务,假设RPC地址为:127.0.0.1:6800,token为12345678
需要安装pymysql, requests, filetype, zipfile, wget等Python包
pip install pymysql requests filetype zipfile wget
项目代码
工作流程
整个爬虫服务的工作流程如下:用户将待抓取的E站链接(形式如 https://e-hentai.org/g/xxxxxxx/yyyyyyyyyy/ )放入数据表的raw_address字段,设置状态字段为待爬取;爬取服务可以在后台轮询或回调触发,提取出数据库中待爬取的链接后访问页面,判断页面里是否提供了bt种子下载,如有则下载种子并传给Aria2下载,如无则直接下载图片(图片优先下载高清版)。
在图片下载模式下,如果一切正常,则结束后置状态字段为已完成;如出现了问题,则置字段为相应异常状态,在下次轮询/调用时进行处理。
在bt下载模式下,另开一个后台进程定时询问Aria2的下载状态,在Aria2返回下载完成报告后解压目标文件,并置状态字段为已完成;如出现了种子已死等问题,则删除Aria2任务并切换到图片下载模式。
数据库操作模块
该模块包装了一些MySQL的操作接口,遵照此逻辑,MySQL可以换成其他数据库,如Redis,进而支持分布式部署。


1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 """ 4 filename: sql_module.py 5 6 Created on Sun Sep 22 23:24:39 2019 7 8 @author: qjfoidnh 9 """ 10 11 import pymysql 12 from pymysql.err import IntegrityError 13 14 class MySQLconn_url(object): 15 def __init__(self): 16 17 self.conn = pymysql.connect( 18 host='127.0.0.1', 19 port=3306, 20 user='username', 21 passwd='password', 22 db='comics_local' 23 ) 24 self.conn.autocommit(True) #开启自动提交,生产环境不建议数据库DBA这样做 25 self.cursor = self.conn.cursor(cursor=pymysql.cursors.DictCursor) 26 #让MySQL以字典形式返回数据 27 28 29 def __del__(self): 30 31 self.conn.close() 32 33 #功能:取指定状态的一条数据 34 def fetchoneurl(self, mode="pending", tabname='comic_urls'): 35 36 sql = "SELECT * FROM %s 37 WHERE status = '%s'" %(tabname, mode) 38 self.conn.ping(True) #mysql长连接防止timeut自动断开 39 try: 40 self.cursor.execute(sql) 41 except Exception as e: 42 return e 43 else: 44 item = self.cursor.fetchone() 45 if not item: 46 return None 47 if mode=="pending" or mode=='aria2': 48 if item['checktimes']<3: 49 sql = "UPDATE %s SET starttime = now(), status = 'ongoing' 50 WHERE id = %d" %(tabname, item['id']) 51 else: 52 sql = "UPDATE %s SET status = 'error' 53 WHERE id = %d" %(tabname, item['id']) 54 if mode=='aria2': 55 sql = "UPDATE %s SET status = 'pending', checktimes = 0, raw_address=CONCAT('chmode',raw_address) 56 WHERE id = %d" %(tabname, item['id']) 57 self.cursor.execute(sql) 58 return 'toomany' 59 elif mode=="except": 60 sql = "UPDATE %s SET status = 'ongoing' 61 WHERE id = %d" %(tabname, item['id']) 62 try: 63 self.cursor.execute(sql) 64 except Exception as e: 65 self.conn.rollback() 66 return e 67 else: 68 return item 69 70 #功能:更新指定id条目的状态字段 71 def updateurl(self, itemid, status='finished', tabname='comic_urls'): 72 sql = "UPDATE %s SET endtime = now(),status = '%s' WHERE id = %d" %(tabname, status, itemid) 73 self.conn.ping(True) 74 try: 75 self.cursor.execute(sql) 76 except Exception as e: 77 self.conn.rollback() 78 return e 79 else: 80 return itemid 81 82 #功能:更新指定id条目状态及重试次数字段 83 def reseturl(self, itemid, mode, count=0, tabname='comic_urls'): 84 85 sql = "UPDATE %s SET status = '%s', checktimes=checktimes+%d WHERE id = %d" %(tabname, mode, count, itemid) 86 self.conn.ping(True) 87 try: 88 self.cursor.execute(sql) 89 except Exception as e: 90 print(e) 91 self.conn.rollback() 92 return e 93 else: 94 return itemid 95 96 #功能:将未下载完成图片的网址列表写入数据库, 97 def fixunfinish(self, itemid, img_urls, filepaths, tabname='comic_urls'): 98 99 img_urls = "Š".join(img_urls) #用不常见拉丁字母做分隔符,避免真实地址中有分隔符导致错误分割 100 filepaths = "Š".join(filepaths) 101 sql = "UPDATE %s SET failed_links = '%s', failed_paths = '%s', status='except' WHERE id = %d" %(tabname, img_urls, filepaths, itemid) 102 self.conn.ping(True) 103 try: 104 self.cursor.execute(sql) 105 except Exception as e: 106 self.conn.rollback() 107 return e 108 else: 109 return 0 110 111 #功能:在尝试完一次未完成补全后,更新未完成列表 112 def resetunfinish(self, itemid, img_urls, filepaths, tabname='comic_urls'): 113 failed_num = len(img_urls) 114 if failed_num==0: 115 sql = "UPDATE %s SET failed_links = null, failed_paths = null, status = 'finished', endtime = now() WHERE id = %d" %(tabname, itemid) 116 else: 117 img_urls = "Š".join(img_urls) #用拉丁字母做分隔符,避免真实地址中有分隔符导致错误分割 118 filepaths = "Š".join(filepaths) 119 sql = "UPDATE %s SET failed_links = '%s', failed_paths = '%s', status = 'except' WHERE id = %d" %(tabname, img_urls, filepaths, itemid) 120 self.conn.ping(True) 121 try: 122 self.cursor.execute(sql) 123 except Exception as e: 124 self.conn.rollback() 125 return e 126 else: 127 return failed_num 128 129 #功能:为条目补上资源名称 130 def addcomicname(self, address, title, tabname='comic_urls'): 131 sql = "UPDATE %s SET comic_name = '%s' WHERE raw_address = '%s'" %(tabname, title, address) #由于调用地点处没有id值,所以这里用address定位。也是本项目中唯二处用address定位的 132 self.conn.ping(True) 133 try: 134 self.cursor.execute(sql) 135 except IntegrityError: 136 self.conn.rollback() 137 sql_sk = "UPDATE %s SET status = 'skipped' 138 WHERE raw_address = '%s'" %(tabname, address) 139 self.cursor.execute(sql_sk) 140 return Exception(title+" Already downloaded!") 141 except Exception as e: 142 self.conn.rollback() 143 return e 144 else: 145 return 0 146 147 #功能:通过网址查询标识Aria2里对应的gid 148 def fetchonegid(self, address, tabname='comic_urls'): 149 sql = "SELECT * FROM %s 150 WHERE raw_address = '%s'" %(tabname, address) 151 self.conn.ping(True) 152 try: 153 self.cursor.execute(sql) 154 except Exception as e: 155 return e 156 else: 157 item = self.cursor.fetchone() 158 if not item: 159 return None 160 else: 161 return item.get('oldpage') 162 163 mq = MySQLconn_url()
初级处理模块
该模块对E站链接进行初步处理,包括获取资源名称,指定下载类型,以及调用次级处理模块,并返回给主函数表示处理结果的状态量。
1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 """ 4 filename: init_process.py 5 6 Created on Sun Sep 22 21:20:54 2019 7 8 @author: qjfoidnh 9 """ 10 11 from settings import * 12 from tools import Get_page, Download_img 13 from second_process import Ehentai 14 from checkdalive import removetask 15 from sql_module import mq 16 import time 17 import os 18 19 20 #功能:尝试下载未完成列表里的图片到指定路径 21 def fixexcepts(itemid, img_urls, filepaths): 22 img_urls_new = list() 23 filepaths_new = list() 24 img_urls = img_urls.split("Š") #从字符串还原回列表 25 filepaths = filepaths.split("Š") 26 for (imglink,path) in zip(img_urls,filepaths): 27 try: 28 content = Get_page(imglink, cookie=cookie_ehentai(imglink)) 29 if not content: 30 img_urls_new.append(imglink) 31 filepaths_new.append(path) 32 continue 33 time.sleep(10) 34 try: 35 img_src = content.select_one("#i7 > a").get('href') #高质量图 36 except AttributeError: #如果高质量图没提供资源 37 img_src = content.select_one("img[id='img']").get("src") #一般质量图 38 src_name = content.select_one("#i2 > div:nth-of-type(2)").text.split("::")[0].strip() #图文件名 39 raw_path = path 40 if os.path.exists(raw_path+'/'+src_name): 41 continue 42 http_code = Download_img(img_src, raw_path+'/'+src_name, cookie=cookie_ehentai(imglink)) 43 if http_code!=200: 44 raise Exception("Network error!") 45 except Exception: 46 img_urls_new.append(imglink) 47 filepaths_new.append(path) 48 result = mq.resetunfinish(itemid, img_urls_new, filepaths_new) 49 return result 50 51 52 class DownEngine: 53 def __init__(self): 54 pass 55 56 #功能:根据传入地址,选择优先下载模式。获取资源标题,写入数据库,并调用次级处理模块 57 def engineEhentai(self, address): 58 if 'chmode' in address: 59 mode='normal' 60 removetask(address=address) 61 else: 62 mode='bt' 63 address = address.replace('chmode', '') 64 content = Get_page(address, cookie=cookie_ehentai(address)) 65 if not content: 66 return 2 67 warning = content.find('h1', text="Content Warning") 68 #e站对部分敏感内容有二次确认 69 if warning: 70 address += '?nw=session' 71 content = Get_page(address, cookie=cookie_ehentai(address)) 72 if not content: 73 return 2 74 title = content.select_one("h1[id='gj']").text 75 if not len(title): #有些资源没有日文名,则取英文名 76 title = content.select_one("h1[id='gn']").text 77 if not len(title): 78 return 2 79 80 title = title.replace("'",'''"''') #含有单引号的标题会令sql语句中断 81 title_st = mq.addcomicname(address, title) 82 if type(title_st)==Exception: 83 return title_st 84 85 ehentai = Ehentai(address, title, mode=mode) 86 result = ehentai.getOthers() 87 return result
次级处理模块
该模块由初级处理模块调用,其通过预设规则寻找给定资源对应的bt种子/所有图片页面,然后进行下载。bt下载模式直接将种子文件和下载元信息传给Aria2,图片下载模式按顺序下载资源里的每一张图片。
并未引入grequests等多协程库来进行请求是因为E站会封禁短时间内过频访问的IP;事实上,我们甚至还需要设置下载间隔时间,如果有更高的效率要求,可考虑缩短下载间隔以及开启多个使用不同代理的进程。
1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 """ 4 filename: second_process.py 5 6 Created on Mon Sep 23 20:35:48 2019 7 8 @author: qjfoidnh 9 """ 10 11 import time 12 import datetime 13 import requests 14 from tools import Get_page, Download_img, postorrent 15 from checkdalive import getinfos 16 from settings import proxies 17 from settings import * 18 import re 19 import os 20 from logger_module import logger 21 22 formatted_today=lambda:datetime.date.today().strftime('%Y-%m-%d')+'/' #返回当前日期的字符串,建立文件夹用 23 24 25 #功能:处理资源标题里一些可能引起转义问题的特殊字符 26 def legalpath(path): 27 path = list(path) 28 path_raw = path[:] 29 for i in range(len(path_raw)): 30 if path_raw[i] in [' ','[',']','(',')','/','\']: 31 path[i] = '\'+ path[i] 32 elif path_raw[i]==":": 33 path[i] = '-' 34 return ''.join(path) 35 36 class Ehentai(object): 37 def __init__(self, address, comic_name, mode='normal'): 38 self.head = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 39 'accept-encoding': 'gzip, deflate, br', 40 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8', 41 'upgrade-insecure-requests': '1', 42 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' 43 } 44 self.address = address 45 self.mode = mode 46 self.gid = address.split('/')[4] 47 self.tid = address.split('/')[5] 48 self.content = Get_page(address, cookie=cookie_ehentai(address)) 49 self.comic_name = legalpath(comic_name) 50 self.raw_name = comic_name.replace("/"," ") 51 self.raw_name = self.raw_name.replace(":","-") 52 self.src_list = [] 53 self.path_list = [] 54 55 #功能:下载的主功能函数 56 def getOthers(self): 57 if not self.content: 58 return 2 59 today = formatted_today() 60 logger.info("E-hentai: %s start!" %self.raw_name) 61 complete_flag = True 62 pre_addr = re.search(r'(e.+org)', self.address).group(1) 63 if self.mode=='bt': #bt种子模式 64 content = Get_page("https://%s/gallerytorrents.php?gid=%s&t=%s"%(pre_addr,self.gid,self.tid), cookie=cookie_ehentai(self.address)) 65 torrents = content.find_all(text="Seeds:") 66 if not torrents: 67 self.mode = 'normal' #图片下载模式 68 else: 69 torrents_num = [int(tag.next_element) for tag in torrents] 70 target_index = torrents_num.index(max(torrents_num)) 71 torrent_link = content.select('a')[target_index].get('href') 72 torrent_name = content.select('a')[target_index].text.replace('/',' ') 73 74 #e-hentai与exhentai有细微差别 75 if 'ehtracker' in torrent_link: 76 req = requests.get(torrent_link, proxy=proxies) 77 if req.status_code==200: 78 with open(abs_path+'bttemp/'+torrent_name+'.torrent', 'wb') as ft: 79 ft.write(req.content) 80 id = postorrent(abs_path+'bttemp/'+torrent_name+'.torrent', dir=abs_path+today) 81 if id: 82 filepath = getinfos().get(id).get('filepath') 83 return {'taskid':id, 'filepath':filepath} 84 else: self.mode = 'normal' 85 86 #e-hentai与exhentai有细微差别 87 elif 'exhentai' in torrent_link: 88 89 req = requests.get(torrent_link, headers={'Host': 'exhentai.org', 90 'Referer': "https://%s/gallerytorrents.php?gid=%s&t=%s"%(pre_addr,self.gid,self.tid), 91 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'}, 92 cookies=cookie_ehentai(self.address), proxies=proxies) 93 if req.status_code==200: 94 with open(abs_path+'bttemp/'+torrent_name+'.torrent', 'wb') as ft: 95 ft.write(req.content) 96 id = postorrent(abs_path+'bttemp/'+torrent_name+'.torrent', dir=abs_path+today) 97 if id: 98 filepath = getinfos().get(id).get('filepath') 99 return {'taskid':id, 'filepath':filepath} 100 else: 101 self.mode = 'normal' 102 else: 103 self.mode = 'normal' 104 105 page_tag1 = self.content.select_one(".ptds") 106 page_tags = self.content.select("td[onclick='document.location=this.firstChild.href']") 107 indexslen = len(page_tags)//2-1 108 if indexslen <=0: 109 indexslen = 0 110 pagetags = page_tags[0:indexslen] 111 pagetags.insert(0, page_tag1) 112 113 #有些页面图片超过8页,页面直接链接可能获取不全,采用按规则生成链接方法 114 last_page = pagetags[-1] 115 last_link = last_page.a.get('href') 116 page_links = [pagetag.a.get('href') for pagetag in pagetags] 117 try: 118 last_number = int(re.findall(r'?p=([0-9]+)',last_link)[0]) 119 except IndexError: 120 pass #说明本子较短,只有一页,不需做特别处理 121 else: 122 if last_number>=8: 123 templete_link = re.findall(r'(.+?p=)[0-9]+',last_link)[0] 124 page_links = [templete_link+str(page+1) for page in range(last_number)] 125 page_links.insert(0, page_tag1.a.get('href')) 126 127 for page_link in page_links: 128 content = Get_page(page_link, cookie=cookie_ehentai(self.address)) 129 if not content: 130 return 2 131 imgpage_links = content.select("div[class='gdtm']") #一种定位标签 132 if not imgpage_links: 133 imgpage_links = content.select("div[class='gdtl']") #有时是另一种标签 134 for img_page in imgpage_links: 135 try: 136 imglink = img_page.div.a.get('href') #对应第一种 137 except: 138 imglink = img_page.a.get('href') #对应第二种 139 content = Get_page(imglink, cookie=cookie_ehentai(self.address)) 140 if not content: 141 complete_flag = False 142 self.src_list.append(imglink) 143 self.path_list.append(abs_path+today+self.raw_name) 144 continue 145 try: 146 img_src = content.select_one("#i7 > a").get('href') #高质量图 147 except AttributeError: 148 img_src = content.select_one("img[id='img']").get("src") #小图 149 src_name = content.select_one("#i2 > div:nth-of-type(2)").text.split("::")[0].strip() #图文件名 150 raw_path = abs_path+today+self.raw_name 151 try: 152 os.makedirs(raw_path) 153 except FileExistsError: 154 pass 155 if os.path.exists(raw_path+'/'+src_name): 156 continue 157 http_code = Download_img(img_src, raw_path+'/'+src_name, cookie=cookie_ehentai(self.address)) 158 if http_code!=200: 159 time.sleep(10) 160 complete_flag = False 161 self.src_list.append(imglink) 162 self.path_list.append(raw_path) 163 continue 164 else: 165 time.sleep(10) 166 if not complete_flag: 167 logger.warning("E-hentai: %s ONLY PARTLY finished downloading!" %self.raw_name) 168 return (self.src_list, self.path_list) 169 170 else: 171 logger.info("E-hentai: %s has COMPLETELY finished downloading!" %self.raw_name) 172 return 1
下载状态查询模块
该模块定时向Aria2查询那些使用了bt下载策略的条目的完成情况,当发现完成时即解压zip文件,然后将数据库中状态字段改为完成;如果连续三次发现下载进度都是0,则认为种子死亡,为条目添加策略切换信号,令初级处理模块在下次处理时按图片下载模式处理。
1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 """ 4 filename: checkdalive.py 5 6 Created on Mon Sep 23 21:20:09 2019 7 8 @author: qjfoidnh 9 """ 10 11 import os 12 from settings import current_path 13 os.chdir(current_path) 14 from sql_module import mq 15 import requests 16 from settings import aria2url, aria2token 17 import time 18 import json 19 import base64 20 import zipfile 21 import filetype 22 23 # 功能:向Aria2发送查询请求 24 def getinfos(): 25 id_str = "AriaNg_%s_0.043716476479668254"%str(int(time.time())) #随机生成即可,不用遵循一定格式 26 id = str(base64.b64encode(id_str.encode('utf-8')), 'utf-8') 27 id_str2 = "AriaNg_%s_0.053716476479668254"%str(int(time.time())) 28 id2 = str(base64.b64encode(id_str2.encode('utf-8')), 'utf-8') 29 data = json.dumps({"jsonrpc":"2.0","method":"aria2.tellActive","id":id,"params":["token:%s"%aria2token,["gid","totalLength","completedLength","uploadSpeed","downloadSpeed","connections","numSeeders","seeder","status","errorCode","verifiedLength","verifyIntegrityPending","files","bittorrent","infoHash"]]}) 30 data2 = json.dumps({"jsonrpc":"2.0","method":"aria2.tellWaiting","id":id2,"params":["token:%s"%aria2token,0,1000,["gid","totalLength","completedLength","uploadSpeed","downloadSpeed","connections","numSeeders","seeder","status","errorCode","verifiedLength","verifyIntegrityPending","files","bittorrent","infoHash"]]}) 31 req = requests.post(aria2url, data) 32 req2 = requests.post(aria2url, data2) 33 if req.status_code!=200: 34 return 35 else: 36 status_dict = dict() 37 results = req.json().get('result') 38 results2 = req2.json().get('result') 39 results.extend(results2) 40 for res in results: 41 status = res.get('status') 42 completelen = int(res.get('completedLength')) 43 totallen = int(res.get('totalLength')) 44 filepath = res.get('files')[0].get('path').replace('//','/').replace("'","\'") 45 if completelen==totallen and completelen!=0: 46 status = 'finished' 47 status_dict[res.get('gid')] = {'status':status, 'completelen':completelen, 'filepath':filepath} 48 return status_dict 49 50 # 功能:也是向Aria2发送另一种查询请求 51 def getdownloadings(status_dict): 52 item = mq.fetchoneurl(mode='aria2') 53 checkingidlist = list() 54 while item: 55 if item=='toomany': 56 item = mq.fetchoneurl(mode='aria2') 57 continue 58 gid = item.get('oldpage') 59 gid = gid or 'default' 60 complete = status_dict.get(gid, {'status':'finished'}) 61 if complete.get('status')=='finished': 62 mq.updateurl(item['id']) 63 filepath = item['filepath'] 64 flag = unzipfile(filepath) 65 removetask(taskid=gid) 66 elif complete.get('completelen')==0 and complete.get('status')!='waiting': 67 mq.reseturl(item['id'], 'checking', count=1) 68 checkingidlist.append(item['id']) 69 else: 70 mq.reseturl(item['id'], 'checking') 71 checkingidlist.append(item['id']) 72 item = mq.fetchoneurl(mode='aria2') 73 for id in checkingidlist: 74 mq.reseturl(id, 'aria2') 75 76 # 功能:解压zip文件 77 def unzipfile(filepath): 78 kind = filetype.guess(filepath) 79 if kind.extension!='zip': 80 return None 81 f = zipfile.ZipFile(filepath, 'r') 82 flist = f.namelist() 83 depstruct = [len(file.strip('/').split('/')) for file in flist] 84 if depstruct[0]==1 and depstruct[1]!=1: 85 try: 86 f.extractall(path=os.path.dirname(filepath)) 87 except: 88 return None 89 else: 90 return True 91 else: 92 try: 93 f.extractall(path=os.path.splitext(filepath)[0]) 94 except: 95 return None 96 else: 97 return True 98 99 #功能:把已完成的任务从队列里删除,以免后来的任务被阻塞 100 def removetask(taskid=None, address=None): 101 id_str = "AriaNg_%s_0.043116476479668254"%str(int(time.time())) 102 id = str(base64.b64encode(id_str.encode('utf-8')), 'utf-8') 103 if taskid: 104 data = json.dumps({"jsonrpc":"2.0","method":"aria2.forceRemove","id":id,"params":["token:%s"%aria2token,taskid]}) 105 if address: 106 taskid = mq.fetchonegid(address) 107 if taskid: 108 data = json.dumps({"jsonrpc":"2.0","method":"aria2.forceRemove","id":id,"params":["token:%s"%aria2token,taskid]}) 109 else: 110 data = json.dumps({"jsonrpc":"2.0","method":"aria2.forceRemove","id":id,"params":["token:%s"%aria2token,"default"]}) 111 req = requests.post(aria2url, data) 112 113 114 if __name__=="__main__": 115 res = getinfos() 116 if res: 117 getdownloadings(res)
工具模块
该模块里定义了一些需要多次调用,或者完成某项功能的函数,比如获取网页内容的Get_page()
1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 """ 4 filename: tools.py 5 6 Created on Mon Sep 23 20:57:31 2019 7 8 @author: qjfoidnh 9 """ 10 11 12 import requests 13 import time 14 from bs4 import BeautifulSoup as Bs 15 from settings import head, aria2url, aria2token 16 from settings import proxies 17 import json 18 import base64 19 20 # 功能:对requets.get方法的一个封装,返回Bs对象 21 def Get_page(page_address, headers={}, cookie=None): 22 pic_page = None 23 innerhead = head.copy() 24 innerhead.update(headers) 25 try: 26 pic_page = requests.get(page_address, headers=innerhead, proxies=proxies, cookies=cookie, verify=False) 27 except Exception as e: 28 return None 29 if not pic_page: 30 return None 31 pic_page.encoding = 'utf-8' 32 text_response = pic_page.text 33 content = Bs(text_response, 'lxml') 34 35 return content 36 37 #功能:把种子文件发给Aria2服务,文件以base64编码 38 def postorrent(path, dir): 39 with open(path, 'rb') as f: 40 b64str = str(base64.b64encode(f.read()), 'utf-8') 41 url = aria2url 42 id_str = "AriaNg_%s_0.043716476479668254"%str(int(time.time())) #这个字符串可以随便起,只要能保证每次调用生成时不重复就行 43 id = str(base64.b64encode(id_str.encode('utf-8')), 'utf-8').strip('=') 44 req = requests.post(url, data=json.dumps({"jsonrpc":"2.0","method":"aria2.addTorrent","id":id,"params":["token:"+aria2token, b64str,[],{'dir':dir, 'allow-overwrite':"true"}]})) 45 if req.status_code==200: 46 return req.json().get('result') 47 else: 48 return False 49 50 # 功能:下载图片文件 51 def Download_img(page_address, filepath, cookie=None): 52 53 try: 54 pic_page = requests.get(page_address, headers=head, proxies=proxies, cookies=cookie, timeout=8, verify=False) 55 if pic_page.status_code==200: 56 pic_content = pic_page.content 57 with open(filepath, 'wb') as file: 58 file.write(pic_content) 59 return pic_page.status_code 60 except Exception as e: 61 return e
日志模块
对logging进行了一个简单的包装,输出日志到文件有利于监控服务的运行状况。
1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 """ 4 filename: logger_module.py 5 6 Created on Mon Sep 23 21:18:37 2019 7 8 @author: qjfoidnh 9 """ 10 11 import logging 12 13 14 LOG_FORMAT = "%(asctime)s - %(filename)s -Line: %(lineno)d - %(levelname)s: %(message)s" 15 logging.basicConfig(filename='downloadsys.log', level=logging.INFO, format=LOG_FORMAT, filemode='a') 16 17 logger = logging.getLogger(__name__)
设置信息
该文件里定义了一些信息,比如代理地址,cookies值,下载路径等等。
虽然不需要登录,但不带cookies的访问很容易被E站认为是恶意攻击。在浏览器里打开开发者工具,然后随意访问一个E站链接,从Network标签页里就能读到Cookies字段的值。不想手动添加cookies,可以考虑使用requests中的session方法重构tools.py中的Get_page函数,自动加cookies。
1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 """ 4 filename: settings.py 5 6 Created on Mon Sep 23 21:06:33 2019 7 8 @author: qjfoidnh 9 """ 10 11 abs_path = "/home/user/e-hentai/" 12 #下载文件的目录,此处为Linux下目录格式,Windows需注意反斜杠转义问题。此目录必须事先建好,且最后一个‘/‘不能丢 13 14 current_path = "/home/user/e-hentai/" 15 #此目录代表项目代码的位置,不一定与上一个相同 16 17 #aria2配置 18 aria2url = "http://127.0.0.1:6800/jsonrpc" 19 aria2token = "12345678" 20 21 #浏览器通用头部 22 head = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} 23 24 cookie_raw_ehentai = '''nw=1; __cfduid=xxxxxxxxxxxx; ipb_member_id=xxxxxx; ipb_pass_hash=xxxxx;xxxxxxxx''' 25 #从浏览器里复制来的cookies大概就是这样的格式,exhentai同理 26 27 cookie_raw_exhentai = '''xxxxxxxx''' 28 29 #代理地址,E站需要科kx学访问,此处仅支持http代理。关于代理的获得及设置请自行学习 30 #听说现在不科学也可以了,如果属实,可令proxies = None 31 proxies = {"http": "http://localhost:10808", "https": "http://localhost:10808"} 32 # proxies = None 33 34 35 def cookieToDict(cookie): 36 ''' 37 将从浏览器上Copy来的cookie字符串转化为Dict格式 38 ''' 39 itemDict = {} 40 items = cookie.split(';') 41 for item in items: 42 key = item.split('=')[0].replace(' ', '') 43 value = item.split('=')[1] 44 itemDict[key] = value 45 return itemDict 46 47 def cookie_ehentai(address): 48 if "e-hentai" in address: 49 return cookieToDict(cookie_raw_ehentai) 50 elif "exhentai" in address: 51 return cookieToDict(cookie_raw_exhentai) 52 else: 53 return cookieToDict(cookie_raw_ehentai)
主函数
主函数从数据库里取条目,并根据返回结果对数据库条目进行相应的更新。
1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 """ 4 filename: access.py 5 6 Created on Mon Sep 23 20:18:01 2019 7 8 @author: qjfoidnh 9 """ 10 11 import time 12 from sql_module import mq 13 from init_process import DownEngine, fixexcepts 14 import os 15 from logger_module import logger 16 17 18 if __name__ =="__main__": 19 20 engine = DownEngine() 21 On = True 22 print("%d进程开始运行..." %os.getpid()) 23 while On: 24 25 #先处理下载未完全的异常条目 26 item = mq.fetchoneurl(mode="except") 27 if type(item)==Exception: 28 logger.error(item) 29 elif not item: 30 pass 31 else: 32 img_srcs = item['failed_links']; filepaths = item['failed_paths']; itemid = item['id']; raw_address = item['raw_address'] 33 34 res = fixexcepts(itemid, img_srcs, filepaths) 35 if type(res)!=int: 36 logger.error(res) 37 continue 38 elif res==0: 39 logger.info("%d进程,%d号页面修复完毕. 40 页面地址为%s" %(os.getpid(), itemid, raw_address)) 41 elif res>0: 42 logger.warning("%d进程,%d号页面修复未完,仍余%d. 43 页面地址为%s" %(os.getpid(), itemid, res, raw_address)) 44 45 46 item = mq.fetchoneurl() 47 if item=='toomany': #指取到的条目超过最大重试次数上限 48 continue 49 if type(item)==Exception: 50 logger.error(item) 51 continue 52 elif not item: 53 time.sleep(600) 54 continue 55 else: 56 raw_address = item['raw_address']; itemid = item['id'] 57 logger.info("%d进程,%d号页面开始下载. 58 页面地址为%s" %(os.getpid(), itemid, raw_address)) 59 res = engine.engineSwitch(raw_address) 60 if type(res)==Exception: 61 logger.warning("%d进程,%d号页面引擎出错. 62 出错信息为%s" %(os.getpid(), itemid, str(res))) 63 mq.reseturl(itemid, 'skipped') 64 continue 65 66 if type(res)==tuple and len(res)==2: 67 response = mq.fixunfinish(itemid, res[0], res[1]) 68 if response==0: 69 logger.warning("%d进程,%d号页面下载部分出错,已标志异常下载状态. 70 页面地址为%s" %(os.getpid(), itemid, raw_address)) 71 else: 72 logger.warning("%d进程,%d号页面下载部分出错且标志数据库状态字段时发生错误. 错误为%s, 73 页面地址为%s" %(os.getpid(), itemid, str(response), raw_address)) 74 75 elif type(res)==dict: 76 if 'taskid' in res: 77 response = mq.reseturl(itemid, 'aria2') 78 mq.replaceurl(itemid, res['taskid'], item['raw_address'], filepath=res['filepath']) 79 80 elif res==1: 81 response = mq.updateurl(itemid) 82 if type(response)==int: 83 logger.info("%d进程,%d号页面下载完毕. 84 页面地址为%s" %(os.getpid(), itemid, raw_address)) 85 else: 86 logger.warning("%d进程,%d号页面下载完毕但更新数据库状态字段时发生错误:%s. 87 页面地址为%s" %(os.getpid(), itemid, str(response), raw_address)) 88 elif res==2: 89 response = mq.reseturl(itemid, 'pending', count=1) 90 if type(response)==int: 91 logger.info("%d进程,%d号页面遭遇初始请求失败,已重置下载状态. 92 页面地址为%s" %(os.getpid(), itemid, raw_address)) 93 else: 94 logger.warning("%d进程,%d号页面遭遇初始请求失败,且重置数据库状态字段时发生错误. 95 页面地址为%s" %(os.getpid(), itemid, raw_address)) 96 elif res==9: 97 response = mq.reseturl(itemid, 'aria2') 98 if type(response)==int: 99 logger.info("%d进程,%d号页面送入aria2下载器. 100 页面地址为%s" %(os.getpid(), itemid, raw_address)) 101 else: 102 logger.warning("%d进程,%d号页面送入aria2下载器,但更新状态字段时发生错误. 103 页面地址为%s" %(os.getpid(), itemid, raw_address)) 104 105 time.sleep(10)
使用方法
把所有文件放在同一目录,在设置信息里修改好配置,运行主函数即可。
另把checkdalive.py加入任务计划或crontab,每隔一段时间执行一次(建议半小时或一小时)
接下来只要把待抓取的页面链接写入数据库raw_address字段,status字段写为pending(可以另做一个脚本/插件来进行这个工作,笔者就是开发了一个Chrome扩展来在E站页面一键入库)即可,程序在轮询中会自动开始处理,不一会儿就能在指定目录下看到资源文件了。
后记
这个爬虫是笔者从自己开发的一套更大的系统上拆分下来的子功能,所以整体逻辑显得比较复杂;另外由于开发历时较久,有些冗余或不合理的代码,读者可自行删减不需要的功能,或进行优化。
比如说,如果不追求效率,可以弃用Aria2下载的部分,全部使用图片下载模式;对于失败图片链接的储存,诸如Redis等内存数据库其实比MySQL更适合;可以增加一个检测环节,检测代理失效或IP被封禁的情形,等等。
对于有一定爬虫基础的人来说,该爬虫的代码并不复杂,其精华实则在于设计思想和对各类异常的处理。笔者看过网上其他的一些E站爬虫,自认为在稳定性和扩展性方面,此爬虫可以说是颇具优势的。