MySQL数据库
一、基本知识
sql语句
分组查询: select * from table group by + 字段; --合并字段中重复的数据
having:通常与group by连用,对分组的结果集进行再筛选
order by:排序,默认升序ASC ,降序DESC
三范式
1NF:数据库中所有的字段都不可再分解
2NF:在第1NF的基础上,每一列都要和主键有关联,即一张表只能有一种数据
3NF:在第2NF的基础上,可以和另外一张表建立一个外键对应关系
char 和 varchar 的区别
char长度不可变 ---varchar长度可变、存放的字符比char多
内连接、右连接、左连接
内连接:就是普通连接,只显示两张表中有关联的数据【显示交集】
inner join ...on.. 一般用 , where...
左连接:以form左边为主,右表中没有的就显示null
left join ... on
右连接:以form右边为主,左表中没有的就显示null
right join ... on
mysql常用引擎
-
InnoDB存储的文件有两个:表的定义文件 、数据文件
-
MyiSAM存储的文件有三个:表的定义文件、数据文件、索引文件(保存了数据文件的指针)
区别:
- InnoDB支持事务和外键,MyiSAM不支持
- InnoDB是聚集索引,MyiSAM是非聚集索引(数据文件和索引文件分开的),InnoDB
优化sql的步骤
-
查看sql执行频率
- show status like 'Com____'; 查询当前连接的信息
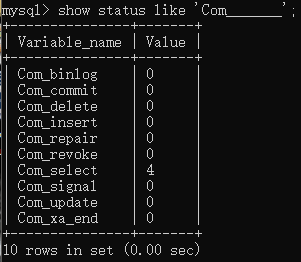
-
show global status like 'Com____'; 查询整个数据库总的连接信息
-
show global status like 'Innodb_row_%'; 查询Innodb
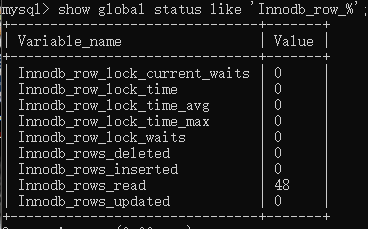
-
定位低效执行的sql
-
分析sql的执行计划
-
explain(解释)分析sql的执行计划
explain + sql语句;
-
mysql5.0.37提供了,show profile(分析)分析sql的执行计划
select @@have_profiling; 查看当前数据库是否支持profile;
set profiling = 1; 设置为1,开启profiling,默认是关闭的;
show profiles;
-

show profile for query 1/2/3...; (可以查看详细的执行结果)
- mysql5.6提供了,trace分析优化器执行计划
set optimizer_trace = 'enable=on', end marks_in_json=on; 设置格式为json
set potimizer_trace_max_mem_size=1000000; 设置trace能够使用的最大内存
执行sql语句
最后检查 information_schema.optimizer_trace就可以知道mysql如何执行sql语句的:
select * from information_schema.optimizer_traceG;
--- 如何定位低效率执行的sql
-
通过慢查询日志定位
-
使用show processlist命令,可以实时查看sql的执行情况

--- explain分析sql的执行计划

| 字段 | 含义 |
|---|---|
| id | 选择标识符,id值越大优先级越高,越先被执行;id如果相同,可以认为是一组,从上往下顺序执行 |
| select_type | (1) SIMPLE(简单SELECT,不使用UNION或子查询等) (2) PRIMARY(子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY) (3) UNION(UNION中的第二个或后面的SELECT语句) (4) DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询) (5) UNION RESULT(UNION的结果,union语句中第二个select开始后面所有select) (6) SUBQUERY(子查询中的第一个SELECT,结果不依赖于外部查询) (7) DEPENDENT SUBQUERY(子查询中的第一个SELECT,依赖于外部查询) (8) DERIVED(派生表的SELECT, FROM子句的子查询) (9) UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行) |
| table | 表名 |
| type | 表的连接类型【ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)】 |
| possible_key | 查询时可能使用到的索引 |
| key | 实际使用到的索引 |
| key_len | 索引字段的长度 |
| ref | 表的连接匹配条件,即哪些列或常量被用于查找索引列上的值 |
| rows | 扫描行的数量 |
| extra | 执行情况的说明和描述 |
二、索引及sql优化策略
1.索引(index)
创建索引:create index 索引名 on 表名(列名)
alter 添加索引:alter table 表名 add index / 普通索引
unique / 唯一索引
fulltext / 索引名(列名) 全文索引
2.添加主键索引:alter table 表名 add primary key(列名)
查看索引:show index from 表名
索引分类:
普通索引:一个索引只包含单个列,一个表可以有多个单列索引
唯一索引:索引列的值唯一,允许有NULL值
主键索引
全文索引
组合索引:一个索引包含多个列
-
优点:索引可以实现高效查询
-
缺点:
- 创建和维护索引要耗费更多的时间,降低了表的更新速度
- 占用物理空间
-
什么时候建立索引:对查询频率高、数据量大的表建立索引
-
对适合的字段创建索引:1.经常查询的列 2.主键的列 3.外键的列 4.经常排序的列 5.使用在where子句中的列
-
索引优化:
- 索引不会包含有空(NULL)值的行列:创建数据库时不要让表的字段默认为空
- 使用短索引:对串列进行索引,如果多数值是唯一的,就不要对整个列进行索引,指定一个长度进行短索引
- like语句操作:like '%xx%'不使用索引,like'xx%'使用索引
- 不要在列上进行运算:会导致索引失效,而进行全表扫描
索引总结:mysql只针对以下操作符才使用索引:<,<=,>,>=,between in,以及某些时候的like。每张表创建的索引最好不要超过6个,最多可以创建16个索引,除非数据量真的非常多
2.B-Tree索引
索引节点都按照平衡树的数据结构来存储,减少定位记录的时间,加快存储速度
B-Tree每个节点包含:
- 关键字和关键字的个数
- 指向父节点的指针、指向子节点的指针
B-Tree特性:
- 关键字集合分布在整棵树中
- 任何关键字只出现在一个节点中
- 搜索可能在非叶子节点结束
- 搜索性能等价于在在关键字全集内做一次二分查找
- 自动实现层次控制,保证深度尽可能小,广度尽可能大
3.全文索引
存储结构是B-Tree,全文索引解决了模糊查询效率低的问题。(全文索引从左往右排序,like ‘xx%’)
4.sql常见的优化策略
-
对查询进行优化、避免全表扫描:在where ,order by涉及的列上建立索引
-
避免在where子句中进行null值的判断,避免在where子句中使用!=,>,<:否则会导致索引失效,进行全表扫描
-
不使用or 来连接条件语句:否则会导致索引失效,进行全表扫描
避免:select id from table where num=10 or num=20
使用:select id from table where num=10
union all
select id from table where num=20
4.避免在条件语句中对字段进行计算:num/2=100 改为:num=100*2;
5.组合索引的使用:使用索引字段作为条件时,如果是复合索引,必须保证使用到该索引中的第一个字段作为条件,并且尽可能的让字段顺序与索引顺序一致。
6.使用exists代替in:
避免:select id from tableA where id in(select id from tableB)
使用:select id from tableA where id exists(select id from tableB where id=tableA.id)
7.不要使用 select * 号 ,用具体的字段列表代替" * ",不要返回用不到的字段,提高查询效率
5.BTree与B+Tree的区别
- B-Tree:每个节点都存储key和data,叶子节点指针为空(NULL)
- B+Tree:只有叶子节点存储了data,叶子节点包含了这棵树所有的键值对,mysql在原B+树的基础上增加了一个指向相邻叶子节点的链表指针,提高了区间的访问性能
三、视图(view)
1.概述
视图:是一种虚拟表,实际不存在。
用途:用来封装多表查询的结果集,简化查询操作
优点:视图相对于普通表的优势
- 简单:封装了多表查询的结果集,查询更简单
- 安全:用户只能访问被允许查询的结果集
- 数据独立:一旦视图的结构确定,原表增加列对视图没有影响;原表修改列名也可以通过
2.创建、查询、修改、删除
创建:create view 视图名 as 跟查询语句
修改:alter view 视图名 as 跟查询语句
查询:show tables
select * from view_name
- 删除:drop view view_name
四、存储过程和函数(procedure)
1.概述
存储过程 (procedure) 和函数 (function) :
存储在数据库中的一段SQL语句的集合,减少数据在数据库和服务器之间的传输,提高了查询效率
存储过程和函数的区别:函数必须有返回值,存储过程没有
存储函数:是一个有返回值的过程
2.存储过程
1.创建:
create procedure procedure_name()
begin
--sql语句
--sql语句
end ;
改变分隔符:delimter $;
2.调用存储过程 :
-- call procedure_name();
3.查询:
1.查询存储过程的状态信息:
-- show procedure status
2.查询一个数据库中的所有存储过程:
select name from mysql.proc where db='database_name';
4.删除
-- drop procedure procedure_name
5.游标/光标
存储查询结果集的数据类型,在存储过程和函数中可以使用游标对结果集进行循环的处理。 游标的使用包括:声明、open、fetch、close
create procedure pro_name()
begin
1. 声明光标:declare cur_name cursor for select 语句 ;
2. open光标:open cur_name ;
3. fetch光标:fetch cur_name into 查询的字段
4. close光标:
end
循环获取游标
create procedure pro_name()
begin
declare e_id int(10);
declare e_name varchar(10);
declare hasdata int default 1;
--声明游标
declare e_city cursor for select id,cityname from city;
固定语法: declare exit handler for not found set hasdata=0;
--打开游标
open e_city;
repeat
fetch e_city into e_id,e_name;
select concat('id=',e_id,'cityname=',e_name);
until hasdata=0
end repeat;
close e_city;
end $
3..储存函数
语法结构:创建存储函数
create function function_name()
returns type
begin
--sql语句
end
查询:select function_name();
删除:drop function function_name;
五、触发器(trigger)
1.概述
触发器是与表有关的数据库对象,指的是在增、删、改之前或之后,触发并且执行SQL语句集合
触发器可以用来协助应用在数据库端确保数据的完整性,日志记录,数据校验等操作。使用别名 NEW 和 OLD 来引用触发器中发生变化的记录内容
MySQL只支持行级触发,不支持语句级触发。
| 触发器类型 | NEW和OLD的使用 |
|---|---|
| INSERT 类型触发器 | NEW表示将要或者已经新增的数据 |
| UPDATE类型触发器 | OLD表示修改前的数据,NEW表示将要或者已经修改后的数据 |
| DELETE类型触发器 | OLD表示将要或者已经删除的数据 |
2.创建触发器
create trigger trigger_name;
before/after insert/update/delete
on table_name
[for each row] --行级触发器
begin
trigger_stmt;
end;