内核优化:
它是内存分配策略,可选值:0、1、2。 0, 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否 则,内存申请失败,并把错误返回给应用进程。 1, 表示内核允许分配所有的物理内存,而不管当前的内存状态如何。 2, 表示内核允许分配超过所有物理内存和交换空间总和的内存。
什么是Overcommit和OOM
Linux对大部分申请内存的请求都回复"yes",以便能跑更多更大的程序。因为申请内存后,并不会马上使用内存,这种技术叫做Overcommit。当linux发现内存不足时,会发生OOM killer(OOM=out-of-memory)。它会选择杀死一些进程(用户态进程,不是内核线程),以便释放内存。 当oom-killer发生时,linux会选择杀死哪些进程?选择进程的函数是oom_badness函数(在mm/oom_kill.c中),该函数会计算每个进程的点数(0~1000),点数越高,这个进程越有可能被杀死。每个进程的点数跟oom_score_adj有关,而且oom_score_adj可以被设置(-1000最低,1000最高)。
解决方法:
将vm.overcommit_memory 设为1即可,有三种方式修改内核参数,但要有root权限:
(1)编辑/etc/sysctl.conf ,加入vm.overcommit_memory = 1,然后sysctl -p使配置文件生效
(2)sysctl vm.overcommit_memory = 1
(3)echo 1 > /proc/sys/vm/overcommit_memory
默认值为:0
0:当用户空间请求更多的的内存时,内核尝试估算出剩余可用的内存。
1:当设这个参数值为1时,内核允许超量使用内存直到用完为止,主要用于科学计算
2:当设这个参数值为2时,内核会使用一个决不过量使用内存的算法,即系统整个内存地址空间不能超过swap+50%的RAM值,50%参数的设定是在overcommit_ratio中设定。
(2)vm.overcommit_ratio
默认值为:50
这个参数值只有在vm.overcommit_memory=2的情况下,这个参数才会生效。
Overcommit和OOM
在Unix中,当一个用户进程使用malloc()函数申请内存时,假如返回值是NULL,则这个进程知道当前没有可用内存空间,就会做相应的处理工作。许多进程会打印错误信息并退出。
Linux使用另外一种处理方式,它对大部分申请内存的请求都回复"yes",以便能跑更多更大的程序。因为申请内存后,并不会马上使用内存。这种技术叫做Overcommit。
当内存不足时,会发生OOM killer(OOM=out-of-memory)。它会选择杀死一些进程(用户态进程,不是内核线程),以便释放内
存。
也就是说这里存在一种情况, malloc的时候返回了yes,但是正真用的时候确发现获取不了memory,所以就OOM了,解决的办法是在/etc/sysctl.conf文件中加入下面2行, 然后执行sysctl -p 即可
vm.overcommit_memory = 2
vm.overcommit_ratio = 8
1 环境介绍:
codis-proxy:19000 是入口:redis-cli -h 10.5.2.11 -p 19000
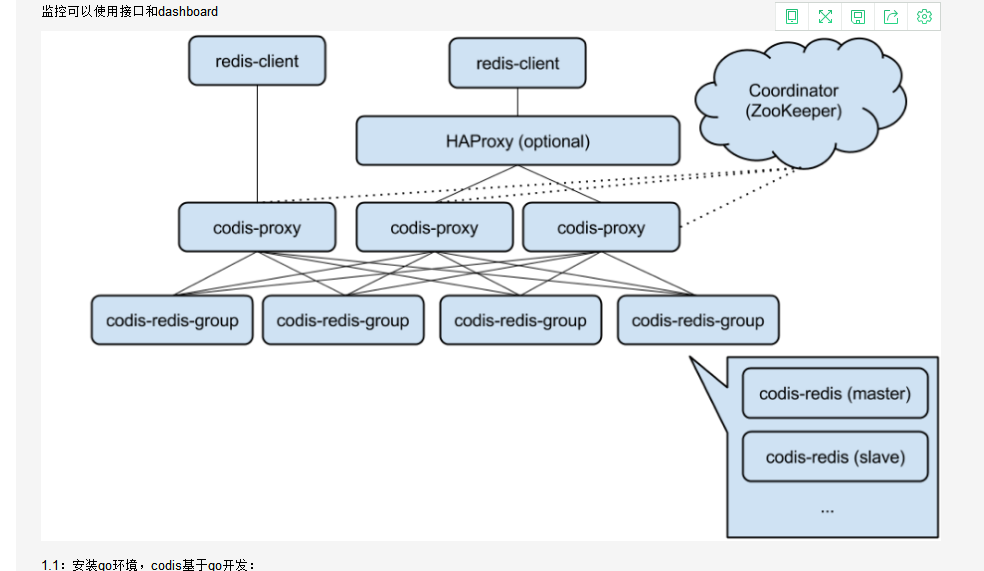
10.5.2.10 zk10: zookeeper codis-dashboard:18080(config) codis-fe:18090(web界面) codis-ha codis-server:6379 codis-server:6378
10.5.2.11 zk11: zookeeper codis-proxy:19000 codis-server:6379 codis-server:6378
10.5.2.12 zk12: zookeeper codis-proxy:19000 codis-server:6379 codis-server:6378
2 安装依赖:
2.1 所以主机安装:
yum install -y gcc glibc gcc-c++ make git autoconf automake libtool
2.2 安装 java:
rpm -e java-1.7.0-openjdk
rpm -e java-1.6.0-openjdk
rpm -e java-1.5.0-gcj --nodeps
vim /etc/profile
JAVA_HOME=/usr/local/jdk1.8.0_144
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
export JAVA_HOME CLASSPATH PATH
source /etc/profile
2.3 安装go
wget https://golangtc.com/static/go/1.8.4/go1.8.4.linux-amd64.tar.gz
tar zxvf go1.8.4.linux-amd64.tar.gz -C /usr/local/
mkdir /usr/local/go/work
vim /root/.bash_profile
export PATH
export PATH=$PATH:/usr/local/go/bin
export GOROOT=/usr/local/go
export GOPATH=/usr/local/go/work
path=$PATH:$HOME/bin:$GOROOT/bin:$GOPATH/bin
source /root/.bash_profile
mkdir -p $GOPATH/src/github.com/CodisLabs
cd /usr/local/go/work/src/github.com/CodisLabs
git clone https://github.com/CodisLabs/codis.git -b release3.2
cd /usr/local/go/work/src/github.com/CodisLabs/codis
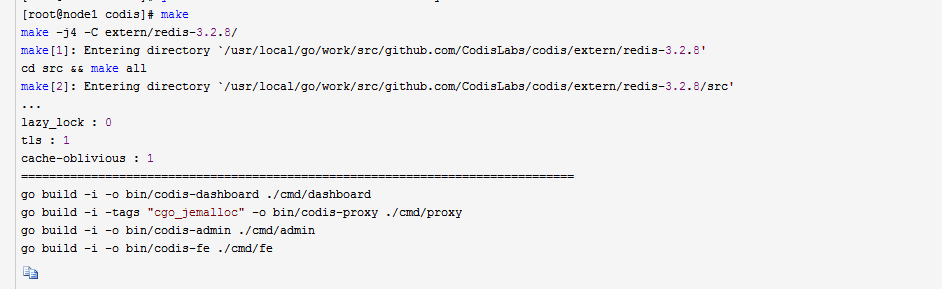
make
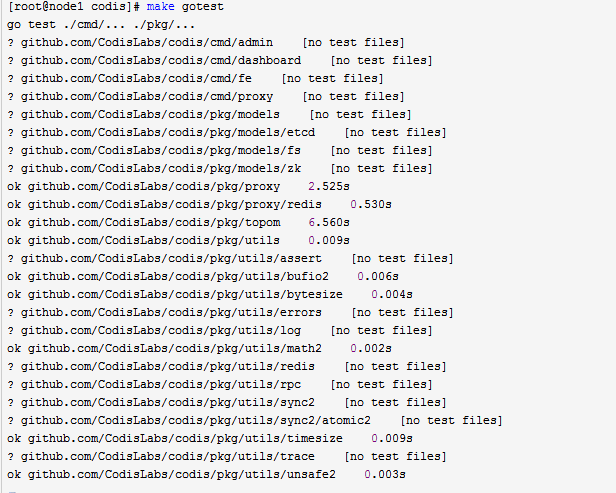
make gotest
2.4 安装 codis-dashboard:18080(config)
cd /usr/local/go/work/src/github.com/CodisLabs/codis/config
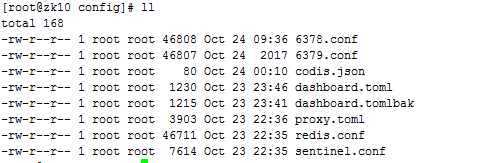
vim dashboard.toml
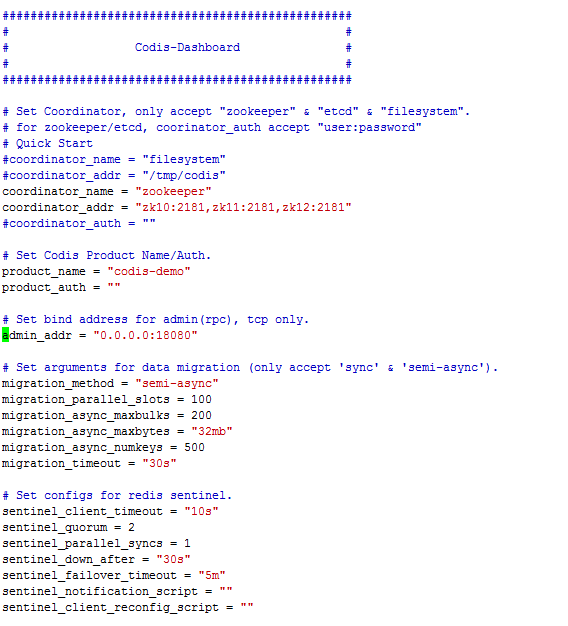
启动 bin/codis-dashboard --ncpu=4 --config=/usr/local/go/work/src/github.com/CodisLabs/codis/config/dashboard.toml --log=dashboard.log --log-level=WARN &
关闭 bin/codis-admin --dashboard=10.5.2.10:18080 --shutdown
2.5 codis-fe:18090(web界面)
生成配置文件: ../bin/codis-admin --dashboard-list --zookeeper=zk11:2181,zk10:2181,zk12:2181 |tee codis.json
启动web: bin/codis-fe --ncpu=4 --log=fe.log --log-level=WARN --dashboard-list=codis.json --listen=0.0.0.0:18090 &
2.6 安装 codis-ha
bin/codis-ha --log=ha.log --log-level=WARN --dashboard=10.5.2.10:18080&
l 默认以 5s为周期,codis-ha会从codis-dashboard中拉取集群状态,并进行主从切换;
codis-ha 在以下状态下会退出:
从 codis-dashboard 获取集群状态失败时;
向codis-dashboard发送主从切换指令失败时。
codis-ha在以下状态下不会进行主从切换:
存在proxy状态异常:因为提升主从需要得到所有proxy的确认,因此必须确保操作时所有proxy都能正常响应操作指令;
网络原因造成的master异常:若存在slave满足slave.master_link_status == up,通常可以认为master并没有真的退出,而是由于网络原因或者响应延迟造成的master状态获取失败,此时codis-ha不会对该group进行操作;
没有满足条件的slave时。提升过程会选择满足slave.master_link_status == down,并且slave.master_link_down_since_seconds最小的进行操作。这就要求被选择的slave至少在过去一段时间内与master是成功同步状态,这个时间间隔是2d+5,其中d是codis-ha检查周期默认5秒。
注意:应用codis-ha时还需要结合对codis-proxy和codis-server的可用性监控,否则codis-ha无法保证可靠性。
需要注意:codis-ha将其中一个slave升级为master时,该组内其他slave是不会自动改变状态的,这些slave仍将试图从旧的master上同步数据,因而会导致组内新的master和其他slave之间的数据不一致。因为redis的slaveof命令切换master时会丢弃slave上的全部数据,从新master完整同步,会消耗资源。因此,当出现主从切换时,需要管理员手动创建新的sync action来完成新master与slave之间的数据同步。
2.7 安装 codis-proxy:19000 在两个 机器上边
product_name 和 dashboard.toml 里边的 相同:
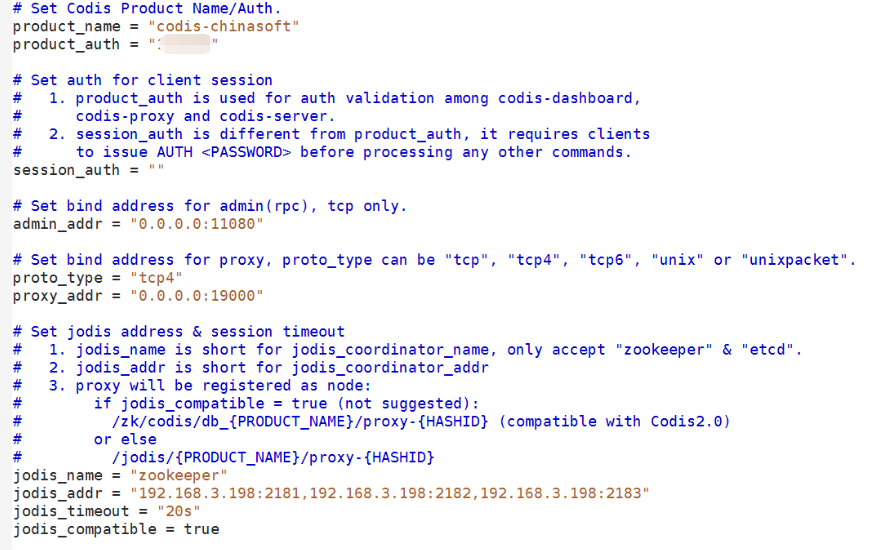
启动 bin/codis-proxy --ncpu=4 --config=/usr/local/go/work/src/github.com/CodisLabs/codis/config/proxy.toml --log=proxy.log --log-level=WARN &
关闭 ./codis-admin --proxy=10.5.2.10:11080 --auth="xxxxx"(有就加,没有就不加) --shutdown
2.8 安装 codis-server
[root@zk11 config]# grep ^[a-Z] /usr/local/go/work/src/github.com/CodisLabs/codis/config/6379.conf
bind 10.5.2.11
protected-mode yes
port 6379
tcp-backlog 511
timeout 0
tcp-keepalive 300
daemonize yes###########################
supervised no
pidfile "/tmp/redis_6379.pid"#######################
loglevel notice
logfile "/var/log/redis/6379.log"##################
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename "dump6379.rdb"#########################
dir "/usr/local/go/work/src/github.com/CodisLabs/codis/config"#######################
slave-serve-stale-data yes
slave-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
slave-priority 100
appendonly no
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes
启动:
/usr/local/go/work/src/github.com/CodisLabs/codis/bin//codis-server /usr/local/go/work/src/github.com/CodisLabs/codis/config/6379.conf &
/usr/local/go/work/src/github.com/CodisLabs/codis/bin//codis-server /usr/local/go/work/src/github.com/CodisLabs/codis/config/6378.conf &
3 web 界面配置http://10.5.2.10:18090:
3.1 添加组:
3.2 添加 实例:
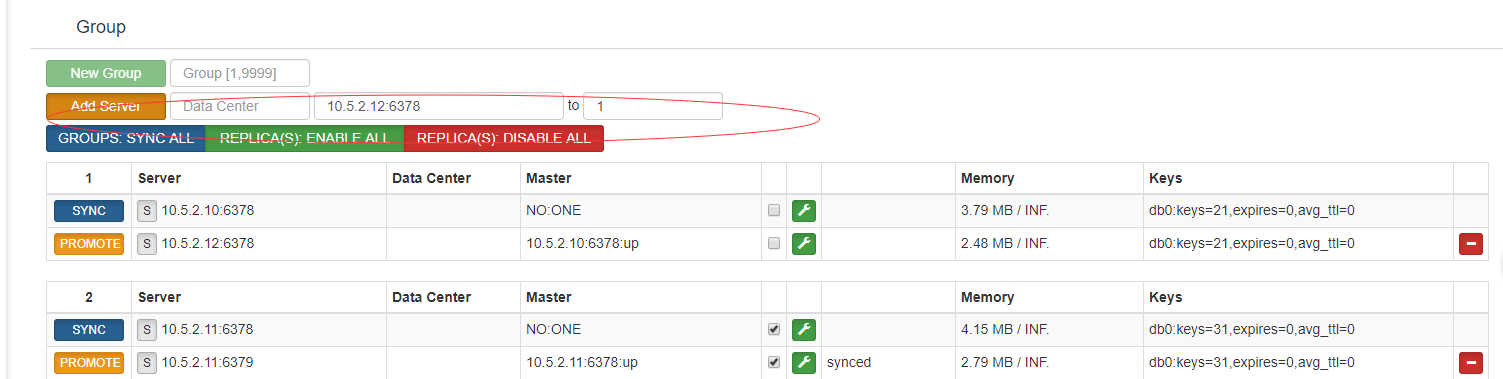
3.3 添加分片soler
3.4 添加 codis-proxy: codis-proxy 上端可以增加lvs, 也可以用keepalive

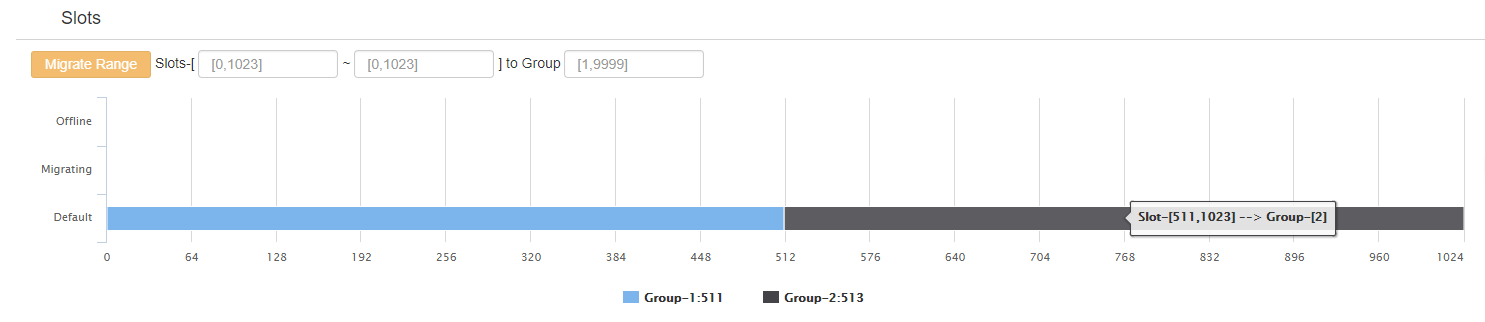
3.5 迁移 soler:

4 备注:
4.1 codis-dashboard 异常退出的修复
当 codis-dashboard 启动时,会在外部存储上存放一条数据,用于存储 dashboard 信息,同时作为 LOCK 存在。当 codis-dashboard 安全退出时,会主动删除该数据。当 codis-dashboard 异常退出时,由于之前 LOCK 未安全删除,重启往往会失败。因此 codis-admin 提供了强制删除工具:
确认 codis-dashboard 进程已经退出(很重要);
运行 codis-admin 删除 LOCK:
$ ./codis-admin --remove-lock --product=codis-demo --zookeeper=10.5.2.11:2181
4.2 codis-proxy 异常退出的修复
通常 codis-proxy 都是通过 codis-dashboard 进行移除,移除过程中 codis-dashboard 为了安全会向 codis-proxy 发送 offline 指令,成功后才会将 proxy 信息从外部存储中移除。如果 codis-proxy 异常退出,该操作会失败。此时可以使用 codis-admin 工具进行移除:
确认 codis-proxy 进程已经退出(很重要);
运行 codis-admin 删除 proxy:
$ ./bin/codis-admin --dashboard=10.5.2.10:18080 --remove-proxy --addr=10.5.2.11:19000 --force
启动 bin/codis-proxy --ncpu=4 --config=/usr/local/go/work/src/github.com/CodisLabs/codis/config/proxy.toml --log=proxy.log --log-level=WARN &
选项 --force 表示,无论 offline 操作是否成功,都从外部存储中将该节点删除。所以操作前,一定要确认该 codis-proxy 进程已经退出。
增加 一个从:
首先在里边设置从 SLAVEOF 10.5.2.10 6378(主), 然后在web添加。
扩展文档如下:
http://blog.csdn.net/liaoyoujinb/article/details/70740485
http://www.cnblogs.com/reblue520/p/6874925.html