今天遇到了一个前同事挖的坑,刷新缓存中商品信息时先让key过期,然后从数据库里取最新数据然后再放到缓存中,他是这样写的
redisTemplate.expire(CacheConst.GOOGS_PREFIX,1,TimeUnit.MILLISECONDS);
设置key过期为一毫秒,导致缓存中有时没有商品信息,因为在这一毫秒内有可能已经从数据库中取到了最新数据,并且又放到了缓存中,一毫秒过后key过期了,缓存中就没了商品信息。
正确的应该这样写redisTemplate.expire(CacheConst.GOOGS_PREFIX,-1,TimeUnit.MILLISECONDS)立马让key过期。
redis中对于有设置过期的key有三种处理方式
- 被动删除:这个key下一次被访问到的时候才会删除。
- 主动删除:Redis会定期主动淘汰一批已过期的key
- 当前已用内存超过maxmemory限定时,触发主动清理策略
直接删除大key是有风险的,key过大,直接删除时会导致Redis阻塞,不同类型的大key有不同的删除方式,
Large Hash Key 可使用hscan命令,每次获取500个字段,再用hdel命令,每次删除1个字段。
Large Set Key 可使用sscan命令,每次扫描集合中500个元素,再用srem命令每次删除一个键。
Large List Key可通过ltrim命令每次删除少量元素
Large Sorted Set Key使用sortedset自带的zremrangebyrank命令,每次删除top 100个元素
目录
redis主从遇到的两个坑 过期key的处理... 1
Redis从节点和主节点中key的数量不同是为什么... 2
主从复制原理图... 3
Redis复制机制的缺陷... 3
注意事项... 4
Python标准库系列之Redis模块... 5
Redis常用命令... 5
1)连接操作命令... 5
2)持久化... 5
3)远程服务控制... 5
4)对value操作的命令... 5
5)String. 6
6)List. 6
7)Set. 7
8)Hash. 7
Redis高级应用... 8
1、安全性... 8
2、主从复制... 8
3、事务处理... 8
4、持久化机制... 9
redis主从遇到的两个坑 过期key的处理
最近在使用redis主从的时候做了下面两件事情:
1 希望redis主从从操作上分析,所有写操作都在master上写,所有读操作都在从上读。
2 由于redis的从是放在本地的,所以有的key的读写操作就直接放在从上操作了。
但是出现了下面的几个问题:
1 在主上setex的key即使过期后在从上也始终get的到。
重现:
主: setex abc 20 test
从:
get abc >> test
ttl abc >> 18
...
ttl abc >> -1
get abc >> test (这里竟然还有~!)
主:get abc >> nil
从:get abc >> nil
所以如果只在从上获取一个key需要根据get+ttl来判断一个key是否已经过期
查了下,也有人吐槽这个问题:http://code.google.com/p/redis/issues/detail?id=519
2 在从上进行读写操作,过期时间不生效
重现:
redis 127.0.0.1:6379> get abctest
(nil)
redis 127.0.0.1:6379> setex abctest 20 test
OK
redis 127.0.0.1:6379> get abctest
"test"
redis 127.0.0.1:6379> ttl abctest
(integer) 10
redis 127.0.0.1:6379> ttl abctest
(integer) -1
redis 127.0.0.1:6379> get abctest
"test" (这里竟然还取得出来。。)
分析
这个现象就是像说从从来不负责删除key,删除key只是主负责的。而由于redis自身删除key的机制是
1 随机选取一定比例的过期key
2 get触发过期删除。
这个函数的意图已经有说明:删一点点过期key,如果过期key较少,那也只用一点点cpu。25行随机取一个key,38行删key成功的概率较低就退出。这个函数被放在一个cron里,每毫秒被调用一次。这个算法保证每次会删除一定比例的key,但是如果key总量很大,而这个比例控制的太大,就需要更多次的循环,浪费cpu,控制的太小,过期的key就会变多,浪费内存——这就是时空权衡了。
以上3种删除过期key的途径,第二种定期删除一定比例的key是主要的删除途径,第一种“读时删除”保证过期key不会被访问到,第三种是一个当内存超出设定时的暴力手段。由此也能看出redis设计的巧妙之处。
这下知道为啥从从redis中能访问到过期的key了,虽然从redis知道key过期,但没有权限删除
所以导致在master上设置了过期的key如果不在master上触发上面两个条件,在从中就永远会被取到。。。
这真是个很容易踩到的坑啊。。。
Redis从节点和主节点中key的数量不同是为什么
原文地址:http://Redis.io/topics/faq
My slave claims to have a different number of keys compared to its master, why?
If you use keys with limited time to live (redis expires) this is normal behavior. This is what happens:
The master generates an RDB file on the first synchronization with the slave.
The RDB file will not include keys already expired in the master, but that are still in memory.
However these keys are still in the memory of the Redis master, even if logically expired. They'll not be considered as existing, but the memory will be reclaimed later, both incrementally and explicitly on access. However while these keys are not logical part of the dataset, they are advertised in INFO output and by the DBSIZE command.
When the slave reads the RDB file generated by the master, this set of keys will not be loaded.
As a result of this, it is common for users with many keys with an expire set to see less keys in the slaves, because of this artifact, but there is no actual logical difference in the instances content.
主从复制原理图
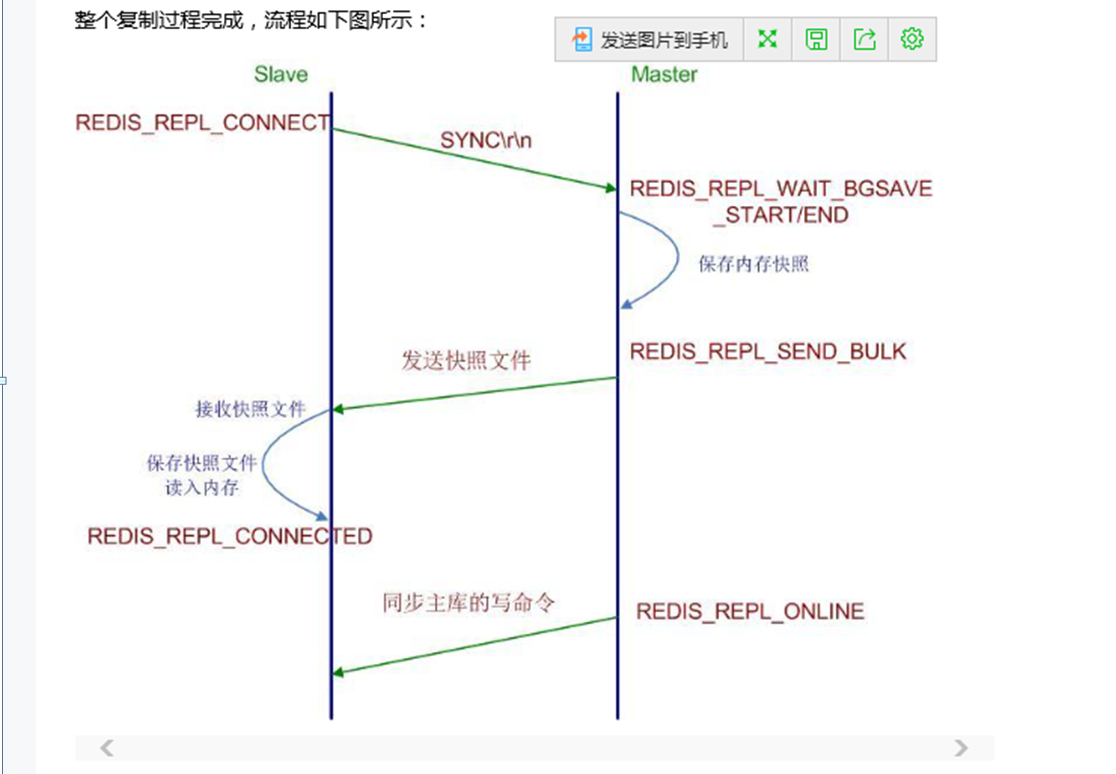
Redis复制机制的缺陷
从上面的流程可以看出,Slave从库在连接Master主库时,Master会进行内存快照,然后把整个快照文件发给Slave,也就是没有象MySQL那样有复制位置的概念,即无增量复制,这会给整个集群搭建带来非常多的问题。
比如一台线上正在运行的Master主库配置了一台从库进行简单读写分离,这时Slave由于网络或者其它原因与Master断开了连接,那么当Slave进行重新连接时,需要重新获取整个Master的内存快照,Slave所有数据跟着全部清除,然后重新建立整个内存表,一方面Slave恢复的时间会非常慢,另一方面也会给主库带来压力。
所以基于上述原因,如果你的Redis集群需要主从复制,那么最好事先配置好所有的从库,避免中途再去增加从库。
Redis复制机制的缺陷
从上面的流程可以看出,Slave从库在连接Master主库时,Master会进行内存快照,然后把整个快照文件发给Slave,也就是没有象MySQL那样有复制位置的概念,即无增量复制,这会给整个集群搭建带来非常多的问题。
比如一台线上正在运行的Master主库配置了一台从库进行简单读写分离,这时Slave由于网络或者其它原因与Master断开了连接,那么当Slave进行重新连接时,需要重新获取整个Master的内存快照,Slave所有数据跟着全部清除,然后重新建立整个内存表,一方面Slave恢复的时间会非常慢,另一方面也会给主库带来压力。
所以基于上述原因,如果你的Redis集群需要主从复制,那么最好事先配置好所有的从库,避免中途再去增加从库。
Cache还是Storage
在我们分析过了Redis的复制与持久化功能后,我们不难得出一个结论,实际上Redis目前发布的版本还都是一个单机版的思路,主要的问题集中在,持久化方式不够成熟,复制机制存在比较大的缺陷,这时我们又开始重新思考Redis的定位:Cache还是Storage?
如果作为Cache的话,似乎除了有些非常特殊的业务场景,必须要使用Redis的某种数据结构之外,我们使用Memcached可能更合适,毕竟Memcached无论客户端包和服务器本身更久经考验。
如果是作为存储Storage的话,我们面临的最大的问题是无论是持久化还是复制都没有办法解决Redis单点问题,即一台Redis挂掉了,没有太好的办法能够快速的恢复,通常几十G的持久化数据,Redis重启加载需要几个小时的时间,而复制又有缺陷,如何解决呢?
Redis可扩展集群搭建
1. 主动复制避开Redis复制缺陷。
既然Redis的复制功能有缺陷,那么我们不妨放弃Redis本身提供的复制功能,我们可以采用主动复制的方式来搭建我们的集群环境。
所谓主动复制是指由业务端或者通过代理中间件对Redis存储的数据进行双写或多写,通过数据的多份存储来达到与复制相同的目的,主动复制不仅限于用在Redis集群上,目前很多公司采用主动复制的技术来解决MySQL主从之间复制的延迟问题,比如Twitter还专门开发了用于复制和分区的中间件gizzard(https://github.com/twitter/gizzard) 。
主动复制虽然解决了被动复制的延迟问题,但也带来了新的问题,就是数据的一致性问题,数据写2次或多次,如何保证多份数据的一致性呢?如果你的应用对数据一致性要求不高,允许最终一致性的话,那么通常简单的解决方案是可以通过时间戳或者vector clock等方式,让客户端同时取到多份数据并进行校验,如果你的应用对数据一致性要求非常高,那么就需要引入一些复杂的一致性算法比如Paxos来保证数据的一致性,但是写入性能也会相应下降很多。
通过主动复制,数据多份存储我们也就不再担心Redis单点故障的问题了,如果一组Redis集群挂掉,我们可以让业务快速切换到另一组Redis上,降低业务风险。
注意事项
http://www.infoq.com/cn/articles/tq-redis-copy-build-scalable-cluster
Redis的复制功能没有增量复制,每次重连都会把主库整个内存快照发给从库,所以需要避免向在线服务的压力较大的主库上增加从库。
Redis的复制由于会使用快照持久化方式,所以如果你的Redis持久化方式选择的是日志追加方式(aof),那么系统有可能在同一时刻既做aof日志文件的同步刷写磁盘,又做快照写磁盘操作,这个时候Redis的响应能力会受到影响。所以如果选用aof持久化,则加从库需要更加谨慎。
可以使用主动复制和presharding方法进行Redis集群搭建与在线扩容。
Python标准库系列之Redis模块
http://python.jobbole.com/87305/
Redis常用命令
1) 连接操作命令
quit:关闭连接(connection)
auth:简单密码认证
help cmd: 查看cmd帮助,例如:help quit
http://www.jb51.net/article/61793.htm
2)持久化
save:将数据同步保存到磁盘
bgsave:将数据异步保存到磁盘
lastsave:返回上次成功将数据保存到磁盘的Unix时戳
shundown:将数据同步保存到磁盘,然后关闭服务
3)远程服务控制
info:提供服务器的信息和统计
monitor:实时转储收到的请求
slaveof:改变复制策略设置
config:在运行时配置Redis服务器
4)对value操作的命令
exists(key):确认一个key是否存在
del(key):删除一个key
type(key):返回值的类型
keys(pattern):返回满足给定pattern的所有key
randomkey:随机返回key空间的一个
keyrename(oldname, newname):重命名key
dbsize:返回当前数据库中key的数目
expire:设定一个key的活动时间(s)
ttl:获得一个key的活动时间
select(index):按索引查询
move(key, dbindex):移动当前数据库中的key到dbindex数据库
flushdb:删除当前选择数据库中的所有key
flushall:删除所有数据库中的所有key
5)String
set(key, value):给数据库中名称为key的string赋予值value
get(key):返回数据库中名称为key的string的value
getset(key, value):给名称为key的string赋予上一次的value
mget(key1, key2,…, key N):返回库中多个string的value
setnx(key, value):添加string,名称为key,值为value
setex(key, time, value):向库中添加string,设定过期时间time
mset(key N, value N):批量设置多个string的值
msetnx(key N, value N):如果所有名称为key i的string都不存在
incr(key):名称为key的string增1操作
incrby(key, integer):名称为key的string增加integer
decr(key):名称为key的string减1操作
decrby(key, integer):名称为key的string减少integer
append(key, value):名称为key的string的值附加value
substr(key, start, end):返回名称为key的string的value的子串
6)List
rpush(key, value):在名称为key的list尾添加一个值为value的元素
lpush(key, value):在名称为key的list头添加一个值为value的 元素
llen(key):返回名称为key的list的长度
lrange(key, start, end):返回名称为key的list中start至end之间的元素
ltrim(key, start, end):截取名称为key的list
lindex(key, index):返回名称为key的list中index位置的元素
lset(key, index, value):给名称为key的list中index位置的元素赋值
lrem(key, count, value):删除count个key的list中值为value的元素
lpop(key):返回并删除名称为key的list中的首元素
rpop(key):返回并删除名称为key的list中的尾元素
blpop(key1, key2,… key N, timeout):lpop命令的block版本。
brpop(key1, key2,… key N, timeout):rpop的block版本。
rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
7)Set
sadd(key, member):向名称为key的set中添加元素member
srem(key, member) :删除名称为key的set中的元素member
spop(key) :随机返回并删除名称为key的set中一个元素
smove(srckey, dstkey, member) :移到集合元素
scard(key) :返回名称为key的set的基数
sismember(key, member) :member是否是名称为key的set的元素
sinter(key1, key2,…key N) :求交集
sinterstore(dstkey, (keys)) :求交集并将交集保存到dstkey的集合
sunion(key1, (keys)) :求并集
sunionstore(dstkey, (keys)) :求并集并将并集保存到dstkey的集合
sdiff(key1, (keys)) :求差集
sdiffstore(dstkey, (keys)) :求差集并将差集保存到dstkey的集合
smembers(key) :返回名称为key的set的所有元素
srandmember(key) :随机返回名称为key的set的一个元素
8)Hash
hset(key, field, value):向名称为key的hash中添加元素field
hget(key, field):返回名称为key的hash中field对应的value
hmget(key, (fields)):返回名称为key的hash中field i对应的value
hmset(key, (fields)):向名称为key的hash中添加元素field
hincrby(key, field, integer):将名称为key的hash中field的value增加integer
hexists(key, field):名称为key的hash中是否存在键为field的域
hdel(key, field):删除名称为key的hash中键为field的域
hlen(key):返回名称为key的hash中元素个数
hkeys(key):返回名称为key的hash中所有键
hvals(key):返回名称为key的hash中所有键对应的value
hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
Redis高级应用
1、安全性
设置客户端连接后进行任何操作指定前需要密码,一个外部用户可以再一秒钟进行150W次访问,具体操作密码修改设置redis.conf里面的requirepass属性给予密码,当然我这里给的是primos
之后如果想操作可以采用登陆的时候就授权使用:
sudo /opt/java/redis/bin/redis-cli -a primos
或者是进入以后auth primos然后就可以随意操作了
2、主从复制
做这个操作的时候我准备了两个虚拟机,ip分别是192.168.15.128和192.168.15.133
通过主从复制可以允许多个slave server拥有和master server相同的数据库副本
具体配置是在slave上面配置slave
slaveof 192.168.15.128 6379
masterauth primos
如果没有主从同步那么就检查一下是不是防火墙的问题,我用的是ufw,设置一下sudo ufw allow 6379就可以了
这个时候可以通过info查看具体的情况
3、事务处理
redis对事务的支持还比较简单,redis只能保证一个client发起的事务中的命令可以连续执行,而中间不会插入其他client的命令。当一个client在一个连接中发出multi命令时,这个连接会进入一个事务的上下文,连接后续命令不会立即执行,而是先放到一个队列中,当执行exec命令时,redis会顺序的执行队列中的所有命令。
比如我下面的一个例子
set age 100
multi
set age 10
set age 20
exec
get age --这个内容就应该是20
multi
set age 20
set age 10
exec
get age --这个时候的内容就成了10,充分体现了一下按照队列顺序执行的方式
discard 取消所有事务,也就是事务回滚
不过在redis事务执行有个别错误的时候,事务不会回滚,会把不错误的内容执行,错误的内容直接放弃,目前最新的是2.6.7也有这个问题的
乐观锁
watch key如果没watch的key有改动那么outdate的事务是不能执行的
4、持久化机制
redis是一个支持持久化的内存数据库
snapshotting快照方式,默认的存储方式,默认写入dump.rdb的二进制文件中,可以配置redis在n秒内如果超过m个key被修改过就自动做快照
append-only file aof方式,使用aof时候redis会将每一次的函数都追加到文件中,当redis重启时会重新执行文件中的保存的写命令在内存中。
5、发布订阅消息 sbusribe publish操作,其实就类似linux下面的消息发布
订阅命令:
SUBSCRIBE redisChat
发布命令:
PUBLISH redisChat "Redis is a great caching technique"
6、虚拟内存的使用
可以配置vm功能,保存路径,最大内存上线,页面多少,页面大小,最大工作线程
临时修改ip地址ifconfig eth0 192.168.15.129
Redis-cli参数
Usage: redis-cli [OPTIONS] [cmd [arg [arg ...]]]
-h <hostname> Server hostname (default:
127.0.0.1)
-p <port> Server port
(default: 6379)
-s <socket> Server socket (overrides
hostname and port)
-a <password> Password to use when connecting to
the server
-r <repeat> Execute specified
command N times
-i <interval> When -r is used, waits
<interval> seconds per command.
It is possible to specify sub-second times like -i 0.1
-n <db>
Database number
-x
Read last argument from STDIN
-d <delimiter> Multi-bulk delimiter in for raw
formatting (default:
)
-c
Enable cluster mode (follow -ASK and -MOVED redirections)
--raw
Use raw formatting for replies (default when STDOUT is not a tty)
--latency Enter a special mode
continuously sampling latency
--slave Simulate a
slave showing commands received from the master
--pipe
Transfer raw Redis protocol from stdin to server
--bigkeys Sample redis keys
looking for big keys
--eval <file> Send an EVAL command using the Lua
script at <file>
--help
Output this help and exit
--version Output version and
exit
Examples:
cat /etc/passwd | redis-cli -x set mypasswd
redis-cli get mypasswd
redis-cli -r 100 lpush mylist x
redis-cli -r 100 -i 1 info | grep used_memory_human:
redis-cli --eval myscript.lua key1 key2 , arg1 arg2 arg3
(Note: when using --eval the comma separates KEYS[] from ARGV[] items)
常用命令:
1) 查看keys个数
keys * // 查看所有keys
keys prefix_* // 查看前缀为"prefix_"的所有keys
2) 清空数据库
flushdb // 清除当前数据库的所有keys
flushall // 清除所有数据库的所有keys