day13 - day 15
1. 日志相关项:
1> 在代码中添加日志,然后输出到文件中;
2> 用于记录代码逻辑执行过程,当报错异常时用于分析问题;
3> 定义日志收集器:要从代码当中按照要求,收集对应的日志,并输出到渠道当中;
a> 要收集哪些级别以上的日志?
b> 日志以什么样的格式显示?
c> 日志要输出到哪里去?
4> 日志级别(Level): debug 调试 - info 基本信息 - warning 警告 - error 报错 - critical(FATA) 严重错误
5> 日志显示的格式(Formatter):时间,日志级别,代码文件,第几行,信息
6> 日志输出渠道(Handle):文件(FileHandle)、控制台(StreamHandle)
2. logging模块:
1> 有一个默认的日志收集器:root,可以自己设定
2> 收集的是warning及warning以上级别的日志
3> 日志格式:日志级别 收集器的名字 输出的内容
4> 输出渠道:控制台/文件


1 import logging 2 3 4 class Student: 5 6 identify = "student" 7 8 def __init__(self,name,age,sex,cn_score,math_score,en_score): 9 self.name = name 10 self.age = age 11 self.sex = sex 12 self.cn_score = cn_score 13 self.math_score = math_score 14 self.en_score = en_score 15 logging.info("hello,logging!!!") 16 17 def get_sum_of_score(self): 18 sum = self.cn_score + self.math_score + self.en_score 19 logging.debug("{} 的语数外总分为:{}".format(self.name, sum)) 20 return sum 21 22 def get_avg_of_score(self): 23 avg = self.get_sum_of_score()/3 24 logging.warning("{} 的语数外平均分为:{}".format(self.name, avg)) 25 26 def print_stu_info(self): 27 logging.warning("我的名字叫{},年龄:{},性别:{}".format(self.name,self.age,self.sex)) 28 29 bing = Student("冰",20,"男",80, 88, 77) 30 bing.get_sum_of_score() 31 bing.get_avg_of_score()
3. 定制输出日志
1> 设置日志收集对象: logger = logging.getLogger(日志名字)
2> 设置日志级别: logger.setLevel(日志级别),一般为INFO
3> 设置日志格式:
a> 自定义日志格式:fmt_str = "%(asctime)s %(name)s %(levelname)s %(filename)s [%(lineno)d] %(message)s"
b> 实例化一个日志格式类:formatter = logging.Formatter(fmt_str)
4> 指定日志输出渠道 - 控制台:
a> 输出到控制台(渠道):stream_handle = logging.StreamHandler()
b> 设置渠道当中的日志显示格式:stream_handle.setFormatter(formatter)
5> 指定日志输出到文件:stream_handle = logging.StreamHandler() file_handle = logging.FileHandler(文件名)
a> 输出到文件(渠道):file_handle = logging.FileHandler(文件名)
b> 设置渠道当中的日志显示格式:file_handle .setFormatter(formatter)
c> 设置从收集的日志中获取错误日志到文件中:
file_handle2 = logging.FileHandler('mylog_eeor.txt',encoding='utf-8')
file_handle2.setFormatter(formatter)
file_handle2.setLevel('ERROR') # 指定输入到mylog_error.txt文件中的日志级别为ERROR以上级别
6> 将渠道与日志收集器绑定起来:logger.addHandler(stream_handle ) 或 logger.addHandler(file_handle ) 或 logger.addHandler(file_handle2)
1 import logging 2 3 # 第一步: 设置日志收集器 4 logger = logging.getLogger('自动化') 5 6 # 第二步:设置日志级别 7 logger.setLevel('INFO') # 设置能收集的日志级别 8 9 # 第三步:设置日志格式 10 fmt_str = "%(asctime)s %(name)s %(levelname)s %(filename)s [%(lineno)d] %(message)s" 11 formatter = logging.Formatter(fmt_str) 12 13 # 第四步 第1种:指定日志渠道 - 控制台 14 stream_handle = logging.StreamHandler() 15 stream_handle.setFormatter(formatter) 16 # 第四步 第2种:指定日志渠道 - 文件 17 file_handle = logging.FileHandler('mylog.txt',encoding='utf-8') 18 file_handle.setFormatter(formatter) 19 20 # 设置专门收集错误日志 21 file_handle2 = logging.FileHandler('mylog_eeor.txt',encoding='utf-8') 22 file_handle2.setFormatter(formatter) 23 file_handle2.setLevel('ERROR') # 指定输入到mylog_error.txt文件中的日志级别为ERROR以上级别 24 25 # 第五步 第1种: 渠道与日志收集器绑定 26 logger.addHandler(stream_handle) 27 # 第五步 第2种: 渠道与日志收集器绑定 28 logger.addHandler(file_handle) 29 logger.addHandler(file_handle2) 30 31 # 第六步: 定制的日志应用于输出日志信息 32 if __name__ == "__main__": 33 34 logger.info('这是自己定制的基本日志信息') 35 logger.warning('这是一条警告信息') 36 logger.error('这是一条错误信息') 37 logger.critical('这是一条严重错误的信息')
运行结果中mylog_error.txt的日志如下

4. 滚动输出日志:日志文件按大小或时长定时生成几个日志文件存放日志 (from logging import handlers)
1> handlers.RotatingFileHandler('my_rotate_log',maxBytes=1,backupCount=10,encoding="utf-8")
a> maxBytes:设置每个日志文件大小为1byte,按日志文件大小控制文件的生成;
b> backupCount:设置最多备份保留最新的日志文件个数;
2> handlers.TimedRotatingFileHandler('my_rotate_time_log.txt',when='S',backupCount=2,encoding="utf-8")
a> when:设置日志文件按时长生成,默认按 h 小时生成,可以设置的值有S,M,H,D,W{0-6}
b> backupCount:设置最多备份保留最新的日志文件个数;
1 import logging 2 import time 3 from logging import handlers 4 5 # 第一步: 设置日志收集器 6 logger = logging.getLogger('自动化') 7 8 # 第二步:设置日志级别 9 logger.setLevel('INFO') 10 11 # 第三步:设置日志格式 12 fmt_str = "%(asctime)s %(name)s %(levelname)s %(filename)s [%(lineno)d] %(message)s" 13 formatter = logging.Formatter(fmt_str) 14 15 # # 第四步 第1种:指定日志渠道 - 控制台 16 stream_handle = logging.StreamHandler() 17 stream_handle.setFormatter(formatter) 18 19 # 第四步:指定日志渠道 - 文件 20 # file_handle = logging.FileHandler('mylog.txt',encoding='utf-8') 21 # file_handle = handlers.RotatingFileHandler('my_rotate_log.txt',maxBytes=2,backupCount=3,encoding="utf-8") 22 file_handle = handlers.TimedRotatingFileHandler('my_rotate_time_log.txt',when='S',backupCount=2,encoding="utf-8") 23 file_handle.setFormatter(formatter) 24 25 # # 第五步 第1种: 渠道与日志收集器绑定 26 logger.addHandler(stream_handle) 27 # 第五步 第2种: 渠道与日志收集器绑定 28 logger.addHandler(file_handle) 29 30 # 第六步: 定制的日志应用于输出日志信息 31 logger.info('11') 32 time.sleep(2) 33 logger.warning('22') 34 logger.error('33') 35 logger.error('44') 36 logger.error('55')
5. 封装日志类
1> 封装日志类后,在业务代码逻辑中增加日志记录代码执行过程,以及报错时根据日志分析问题;
2> 继承Logger类,不用自己再实现 info() debug() error() warning() critical()方法;
3> 封装的日志类,应用于实际业务场景;
1 import logging 2 from logging import Logger 3 4 class MyLoger(Logger): # 继承Logger类,不用自己实现 info() debug() error()等方法 5 6 def __init__(self,name,level=logging.INFO,filename = None): 7 # 1. 设置日志收集者名字,日志级别 8 super().__init__(name,level) 9 # 2. 设置日志输出渠道 (控制台和文件) 10 fmt_str = "%(asctime)s %(name)s %(levelname)s %(filename)s [%(lineno)d] %(message)s" 11 formatter = logging.Formatter(fmt_str) 12 13 stream_handle = logging.StreamHandler() 14 stream_handle.setFormatter(formatter) 15 self.addHandler(stream_handle) # 绑定日志收集器 16 if filename: 17 file_handle = logging.FileHandler(filename, encoding='utf-8') 18 file_handle.setFormatter(formatter) 19 self.addHandler(file_handle) # 绑定日志收集器
1 """ 2 第4题 :定义类并实例化对象 3 定义一个登录的测试用例类LoginCase。每一个实例对象都是一个登陆测试用例。 4 属性:用例名称 预期结果 实际结果(初始化时不确定值哦) 5 方法: 6 1) 运行用例 7 说明:有2个参数:用户名和密码。 能够登录成功的用户名:py37, 密码:666666。 8 通过用户名和密码正确与否来判断,是否登录成功。并返回实际结果。 9 ps: 可以在用例内部考虑处理不符合的情况哦:密码长度不是6位/密码不正确/用户名不正确等。。 10 2) 获取用例比对结果(比对预期结果和实际结果是否相等,并输出成功or失败) 11 实例化2个测试用例 ,并运行用例(调用方法) ,呈现用例结果(调用方法) 12 """ 13 from python基本语法.day15_封装日志模块.mylogger import MyLoger 14 loger = MyLoger('py37',filename='auto.log') # 实例化 15 16 17 class LoginCase: 18 19 def __init__(self,case_name,case_expected): 20 loger.info('创建一条测试用例,用例名称为:{}'.format(case_name)) 21 self.case_name = case_name 22 self.case_expected = case_expected 23 self.case_actual = None 24 25 def run_case(self,user,passwd): 26 loger.info('用例数据为:用户名 {},密码 {}'.format(user,passwd)) 27 if len(passwd) != 6: 28 self.case_actual = "密码长度不等于6" 29 return 30 if user != "py37": 31 self.case_actual = "用户名错误" 32 return 33 if passwd != "666666": 34 self.case_actual = "密码错误" 35 return 36 if user == "py37" and passwd == "666666": 37 self.case_actual = "登陆成功" 38 loger.info('用例运行完成,运行结果为:{}'.format(self.case_actual)) 39 40 def case_res(self): 41 loger.info('开始结果比对') 42 loger.info("实际结果为:{}".format(self.case_actual)) 43 loger.info("预期结果为:{}".format(self.case_expected)) 44 if self.case_actual != self.case_expected: 45 # print("实际结果与预期结果不相等,用例不通过!") 46 loger.error('实际结果与预期结果不相等,用例不通过!') 47 else: 48 # print("恭喜,实际结果与预期结果相等,用例通过!") 49 loger.info('恭喜,实际结果与预期结果相等,用例通过!') 50 51 login_suc = LoginCase("登陆成功","登陆成功") 52 login_suc.run_case("py37","666668") 53 login_suc.case_res() 54 55 login_failed = LoginCase("登陆失败","密码错误") 56 login_failed.run_case("py37","666688") 57 login_failed.case_res()
6. 单例模式:整个运行过程中,只有一个实例化对象,如上面的日志类使用单例模式更好
1 import logging 2 from logging import Logger 3 4 class MyLoger(Logger): # 继承Logger类,不用自己实现 info() debug() error()等方法 5 6 def __init__(self,name,level=logging.INFO,filename = None): 7 # 1. 设置日志收集者名字,日志级别 8 super().__init__(name,level) 9 # 2. 设置日志输出渠道 (控制台和文件) 10 fmt_str = "%(asctime)s %(name)s %(levelname)s %(filename)s [%(lineno)d] %(message)s" 11 formatter = logging.Formatter(fmt_str) 12 13 stream_handle = logging.StreamHandler() 14 stream_handle.setFormatter(formatter) 15 self.addHandler(stream_handle) # 绑定日志收集器 16 if filename: 17 file_handle = logging.FileHandler(filename, encoding='utf-8') 18 file_handle.setFormatter(formatter) 19 self.addHandler(file_handle) # 绑定日志收集器 20 21 loger = MyLoger('py37',filename='auto.log') # 实例化一个日志对象,该模块被导入后,直接使用logger调用方法
1 # from python基本语法.day15_封装日志模块.mylogger import MyLoger 2 # loger = MyLoger('py37',filename='auto.log') # 实例化 3 4 # 更好的方法,因为在mylogger模块统一实例化 5 from python基本语法.day15_封装日志模块.mylogger import loger 6 7 class LoginCase: 8 9 def __init__(self,case_name,case_expected): 10 loger.info('创建一条测试用例,用例名称为:{}'.format(case_name)) 11 self.case_name = case_name 12 self.case_expected = case_expected 13 self.case_actual = None 14 15 def run_case(self,user,passwd): 16 loger.info('用例数据为:用户名 {},密码 {}'.format(user,passwd)) 17 if len(passwd) != 6: 18 self.case_actual = "密码长度不等于6" 19 return 20 if user != "py37": 21 self.case_actual = "用户名错误" 22 return 23 if passwd != "666666": 24 self.case_actual = "密码错误" 25 return 26 if user == "py37" and passwd == "666666": 27 self.case_actual = "登陆成功" 28 loger.info('用例运行完成,运行结果为:{}'.format(self.case_actual)) 29 30 def case_res(self): 31 loger.info('开始结果比对') 32 loger.info("实际结果为:{}".format(self.case_actual)) 33 loger.info("预期结果为:{}".format(self.case_expected)) 34 if self.case_actual != self.case_expected: 35 # print("实际结果与预期结果不相等,用例不通过!") 36 loger.error('实际结果与预期结果不相等,用例不通过!') 37 else: 38 # print("恭喜,实际结果与预期结果相等,用例通过!") 39 loger.info('恭喜,实际结果与预期结果相等,用例通过!') 40 41 login_suc = LoginCase("登陆成功","登陆成功") 42 login_suc.run_case("py37","666668") 43 login_suc.case_res() 44 45 login_failed = LoginCase("登陆失败","密码错误") 46 login_failed.run_case("py37","666688") 47 login_failed.case_res()
7. 配置文件的读取 (ConfigParser类 -- .ini,PyYaml模块 -- .yaml)
1> 创建一个.ini的配置文件:[section] option=value,文件中可以用 # 或 ; 来增加注释信息
2> python读取.ini配置文件数据
a> 导入ConfigParser类
b> 实例化ConfigParser类,:conf = ConfigParser()
c> 调用read()方法,读取整个配置文件的内容到内存中:conf.read(filename,encoding="utf-8")
e> 读取配置文件中指定的section的option,读取出来默认是字符串:name = conf.get('log','name')
f> 支持读取出来为 bool int float: conf.getboolean(section,option) conf.getint(section,option) conf.getfloat(section,option)
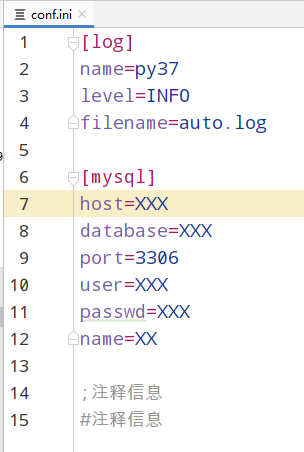
conf.ini配置文件内容如下:
[log]
name=py37
level=INFO
filename=auto.log
[mysql]
host=XXX
database=XXX
port=3306
user=XXX
passwd=XXX
name=XX
;注释信息
#注释信息
from configparser import ConfigParser conf = ConfigParser() # 读取整个配置文件的内容到内存中 conf.read('conf.ini',encoding='utf-8') # 读取配置文件中指定的section的option,读取出来默认为字符串 name = conf.get('log','name') # print(name) # 读取出来为int,port需要是整数。还有getboolean() getfloat() port = conf.getint('mysql','port') # print(port)
3> 封装ConfigParser类,用于其他模块可以读取配置文件,如上面日志类的实例化时,日志收集者的名字,日志级别和日志文件都写死了,怎么实现配置化呢?
1 from configparser import ConfigParser 2 3 class MyConf(ConfigParser): 4 5 def __init__(self,filename): 6 super().__init__() 7 self.read(filename, encoding="utf-8") # 一定要先读取配置文件后,才能再使用myconf.get()读取具体option的值
1 import logging 2 from logging import Logger 3 4 from python基本语法.day15_封装日志模块.myconfig import MyConf 5 6 class MyLoger(Logger): # 继承Logger类,不用自己实现 info() debug() error()等方法 7 8 # def __init__(self,name,level=logging.INFO,filename = None): 9 def __init__(self): 10 # 让日志的收集者名字,日志级别和日志文件名可配置 11 myconf = MyConf('conf.ini') # 实例化配置类 12 13 name = myconf.get('log', 'name') 14 level = myconf.get('log', 'level') 15 filename = myconf.get('log', 'filename') 16 17 # 1. 设置日志收集者名字,日志级别 18 super().__init__(name,level) 19 # 2. 设置日志输出渠道 (控制台和文件) 20 fmt_str = "%(asctime)s %(name)s %(levelname)s %(filename)s [%(lineno)d] %(message)s" 21 formatter = logging.Formatter(fmt_str) 22 23 stream_handle = logging.StreamHandler() 24 stream_handle.setFormatter(formatter) 25 self.addHandler(stream_handle) # 绑定日志收集器 26 if filename: 27 file_handle = logging.FileHandler(filename, encoding='utf-8') 28 file_handle.setFormatter(formatter) 29 self.addHandler(file_handle) # 绑定日志收集器 30 31 32 # loger = MyLoger('py37',filename='auto.log') # 实例化一个日志对象,该模块被导入后,直接使用loger调用方法 33 34 loger = MyLoger() #日志相关参数配置在.ini文件中了,故不需要传参数了
配置类 --> 日志类 --> 业务代码:配置类给到了日志类使用,日志类给到了业务代码使用;
PS: 一定要先读取配置文件后,才能再使用myconf.get()读取具体option的值
8. ConfigParser类的写入:set/write
1> 在已有section下添加/修改option的value: conf.set(section,option,value)
2> 若要新增section:conf.add_section(section)
3> 将1>和2>中的变更写入到配置文件当中:conf.write(open(文件, 'w', encoding='utf-8'))
from configparser import ConfigParser conf = ConfigParser() # 给log下写入test=001 conf.set('log','test','001') # 新增section -- dev conf.add_section('dev') # 最后将变更写入配置文件中 conf.write(open('conf.ini','w'))
9. Yaml文件的特点
1> 以数据为中心,使用空白,缩进,分行组织数据,从而使得数据更加简洁易懂;
2> 大小写敏感;
3> 使用缩进表示层级关系 - ;
4> 禁止使用tab缩进,只能使用空格键;
5> 缩进长度没有限制,只要元素对齐就表示这些元素属于一个层级;
6> 使用#表示注释;
7> 字符串可以不用引号标注;
10. yaml文件的3种数据结构:
1> 字典:使用冒号(:)表示键值对,注意冒号后面有一个空格;
2> 列表:使用连字符(-)表示,注意连字符后面有一个空格;
3> 纯量scalar:字符串,数字,布尔值,不可变数据类型;

11. 操作yaml文件
1> 第三方库:pyyaml模块 pip install pyyaml
2> 从yaml中读取数据
a> 导入yaml: import yaml
b> 打开yaml文件:open(yaml文件路径, encoding='utf-8')
c> 加载文件:s = yaml.load(fs,yaml.FullLoader)
import yaml with open('conf.yaml',encoding='utf-8') as fs: s = yaml.load(fs,yaml.FullLoader) print(s)
13. unittest的基本用法
1> TestCase:编写测试用例类时需要继承该类,用于编辑测试用例;
2> setUp:用于实现每条测试用例的前置条件;
3> tearDown:用于实现每条测试用例的后置条件;
4> setUpClass:通过@classmethod装饰成类方法,用于实现每个测试类中所有测试用例的前置条件;
5> tearDownClass:通过@classmethod装饰成类方法,用于实现每个测试类中所有测试用例的后置条件;
1 import unittest 2 3 class TestDemo(unittest.TestCase): 4 @classmethod 5 def setUpClass(cls) -> None: 6 print("***这是该测试类中所有用例执行前的前置条件***") 7 def setUp(self) -> None: 8 print("---这是每条测试用例的前置条件---") 9 10 def test_01_login(self): 11 print("用例1:这是一条登录测试用例") 12 13 def test_01_register(self): 14 print("用例2:这是一条注册测试用例") 15 16 def tearDown(self) -> None: 17 print("###这是每条测试用例的后置条件###") 18 19 @classmethod 20 def tearDownClass(cls) -> None: 21 print("***这是该测试类中所有用例执行后的后置条件***")
14. unittest加载用例
1> 通知测试类加载用例 loadTestsFromTestCase():通过一个一个的用例类名,将用例加载到测试套件中;
1 import unittest 2 from python基本语法.day15_unittest.test_01demo import TestDemo 3 from python基本语法.day15_unittest.test_02demo import TestDemo2 4 5 # 创建一个测试套件 6 suite = unittest.TestSuite() 7 # 创建一个用例加载器 8 loader = unittest.TestLoader() 9 # 将用例加载到测试套件 10 # loader加载用例的方法如下: 11 # 方式1:通过用例类名(loadTestsFromTestCase()) 12 suite.addTest(loader.loadTestsFromTestCase(TestDemo)) 13 suite.addTest(loader.loadTestsFromTestCase(TestDemo2))
缺点:用例类要一个一个的导入,之后再一个一个的加载到测试套件中,非常麻烦
2> 通过用例模块加载用例 loadTestsFromModule():通过一个一个的用例模块名,将用例加载到测试套件中;
1 from python基本语法.day15_unittest import test_01demo,test_02demo 2 # 创建一个测试套件 3 suite = unittest.TestSuite() 4 # 创建一个用例加载器 5 loader = unittest.TestLoader() 6 # 方式2:通过用例模块名loadTestsFromModule() 7 suite.addTest(loader.loadTestsFromModule(test_01demo)) 8 suite.addTest(loader.loadTestsFromModule(test_02demo))
3> 通过用例文件所在路径加载用例 (loader.discover(路径,pattern='test*.py')):提供用例所在路径,结合匹配模式在该路径下查找满足条件的测试用例文件来加载用例;
pattern指定匹配模式,如'test*.py'代表查找文件名以test开关,以.py结束的文件
1 import unittest 2 3 # 创建一个测试套件 4 suite = unittest.TestSuite() 5 # 创建一个用例加载器 6 loader = unittest.TestLoader() 7 # 方式3:通过用例文件所在路径(discover()) 8 suite.addTest(loader.discover(r'D:python_lemon37python基本语法day15_unittest',pattern='test*.py')) 9 10 # 查看套件中的用例数量 11 print(suite.countTestCases())
15. unittest用例运行
1> 执行用例时,不能直接使用unittest.TestRunner,因为它不是一个对外开放的API
# 用例运行 runer = unittest.TestRunner() runer.run(suite) #报错,因为TestRunner类不是一个直接对外开放的API,不能直接使用
2> 执行用例时,是使用 unittest.TextTestRunner() 类
a> stream:用例执行结果输出到文件中
b> verbosity:默认为1,还可以为0和2,为2时详情输出了用例执行结果是否成功,为0时输出的信息最少;
# 用例运行 with open('result.txt','a',encoding='utf-8') as fs: runer = unittest.TextTestRunner(stream=fs,verbosity=2) runer.run(suite)
3> 前面加载用例时,要需经过三步(1. 创建测试套件 2. 创建用例加载器 3. 将用例加载到测试套件中 ),其实unittest提供了一个更简单的加载用例方法
import unittest # 一步完成用例加载 suite = unittest.defaultTestLoader.discover(r'D:python_lemon37python基本语法day15_unittest',pattern='test*.py') # 查看套件中的用例数量 print(suite.countTestCases()) # 用例运行 with open('result.txt','a',encoding='utf-8') as fs: runer = unittest.TextTestRunner(stream=fs,verbosity=2) runer.run(suite)
4> 生成 BeautifulReport 测试报告
a> 下载安装包BeautifulReport-master.zip,解压后将文件名修改为BeautifulReport
b> 将整个包放到本地python的/Lib/site-packages目录下
c> 运行用例,生成BeautifulReport报告
# 一步完成用例加载 from BeautifulReport import BeautifulReport suite = unittest.defaultTestLoader.discover(r'D:python_lemon37python基本语法day15_unittest',pattern='test*.py') # 运行用例生成BeautifulReport runer = BeautifulReport(suites=suite) runer.report(description='测试用例演示')
5> 生成 HtmlTestRunner 报告
a> 安装HtmlTestRunner:pip install html-testRunner
b> 生成报告: runer = HTMLTestRunner()
c> 生成一个文件夹reports,里面是按用例模块生成html报告的;
from HtmlTestRunner import HTMLTestRunner suite = unittest.defaultTestLoader.discover(r'D:python_lemon37python基本语法day15_unittest',pattern='test*.py') # 运用用例生成报告 runer = HTMLTestRunner() runer.run(suite)

6> 生成HTMLTestRunnerNew报告:
1> 安装HTMLTestRunnerNew:在python第三方库管理平台官网 https://pypi.org/project/pip/
2> 生成报告:runer = HTMLTestRunner(stream=fs)
# 运行用例生成报告 from HTMLTestRunnerNew import HtmlTestRunner with open('result.html','wb') as fs: runer = HTMLTestRunner(stream=fs) runer.run(suite)
16. unittest源码初认 leetcode
1> python中文说明文档:https://docs.python.org/zh-cn/3/library/index.html
2> unittest源码说明文档:https://docs.python.org/zh-cn/3/library/unittest.html
17. unittestreport:核心的类 TestRunner 和 TestResult
1> 安装:pip install unittestreport
2> 特性:
a> HTML测试报告;
b> 测试用例失败重运行;
c> 发送测试结果及报告到邮箱
d> unittest数据驱动;
e> 测试结果钉钉通知;
f> 多线程执行用例;
3> 核心源码查看地址: https://github.com/musen123/UnitTestReport/tree/master/unittestreport/core
18. unittestreport生成报告:默认报告名为 report.html,可以传参修改报告相关的字段 filename report_dir title tester desc templates
1> 参数中的 templates 控制测试报告生成的样式,可以为1,2,3
import unittest from unittestreport import TestRunner # 第1步:收集用例 suite = unittest.defaultTestLoader.discover(r'D:python_lemon37python基本语法day15_unittest',pattern='test*.py') # 第2步:运行用例生成报告 runer = TestRunner(suite, filename="auto_report.html", report_dir=".", title='测试演示', tester='天天', desc="理赔项目测试报告", templates=1) runer.run()
19. unittestreport数据驱动 DataDrivenTest:将用例数据和用例逻辑代码进行分离,提高代码的重用率,以及提升代码的可维护性;
1> pytest的数据驱动:用例数据参数化处理(即用例数据和用例逻辑代码是分离的),通过用例数据生成测试用例;
2> 列表数据驱动:测试数据保存在列表中,通过@ddt装饰测试用例类,@list_data()装饰测试用例方法,其中case参数接收每一条用例数据;
a> 简单的测试数据:
import unittest from unittestreport.core.dataDriver import ddt,list_data,yaml_data,json_data test_data = [(11,11),(22,22),(33,33),(44,44)] @ddt class TestDemo(unittest.TestCase): @list_data(test_data) def test_demo(self,case): self.assertEqual(case[0],case[1])
b> list测试数据包含title字段:
import unittest from unittestreport.core.dataDriver import ddt,list_data # 列表数据驱动-title字段为测试报告中每条测试用例的用例描述 test_data = [{'data':('aa','aa'),'title':'用户登录成功'}, {'data':('',22),'title':'账号不能为空'}, {'data':(11,''),'title':'密码不能为空'}, {'data':(11,22),'title':'账号名不规范'}] @ddt class TestDemo(unittest.TestCase): @list_data(test_data) def test_demo(self,case): print(case['data'][0]) self.assertEqual(case['data'][0],case['data'][1])

3> yaml数据驱动:
a> yaml格式的测试数据如下:
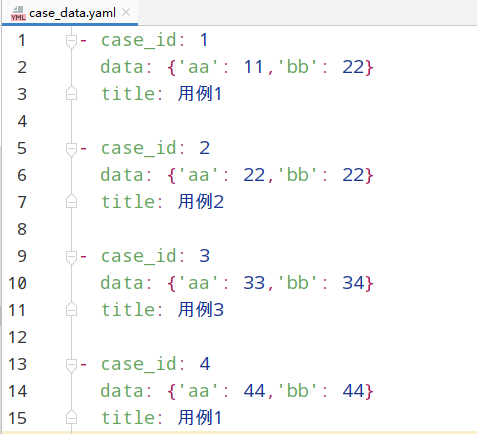
b> 代码如下:
import unittest from unittestreport.core.dataDriver import ddt,yaml_data @ddt class TestDemoYaml(unittest.TestCase): @yaml_data(r'case_data.yaml') def test_yaml(self,case): self.assertEqual(case['data']['aa'],case['data']['bb'])
c> 执行结果多出一些打印内容:
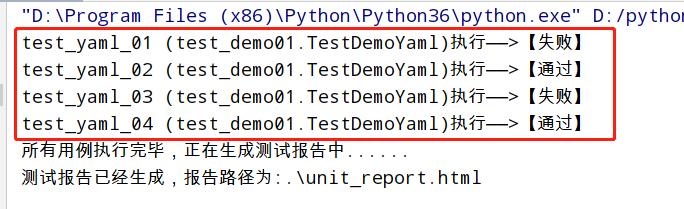
d> yaml文件每条数据的title字段为测试报告中的用例描述

4> json测试数据:
1> json格式的数据如下:
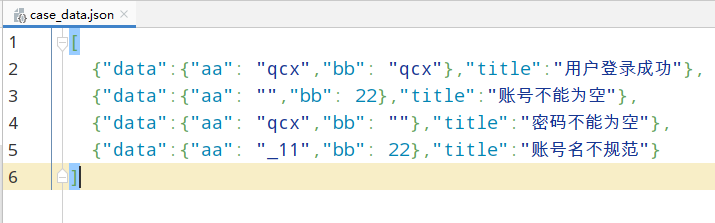
2> 代码如下:
import unittest from unittestreport.core.dataDriver import ddt,json_data # json数据驱动 json文件每条数据的title字段为测试报告中每条测试用例的用例描述 @ddt class TestDemoJson(unittest.TestCase): @json_data(r'case_data.json') def test_json(self,case): self.assertEqual(case['data']['aa'],case['data']['bb'])
3> json 文件每条数据的title字段为测试报告中的用例描述

20. unittestreport重运行机制:
1> @rerun装饰在测试用例方法上用于某个测试方法运行失败时重新运行;
a> 导入unittestreport中的rerun方法,再装饰在需要重运行的测试用例方法上即可 test_demo.py
import unittest from unittestreport import rerun class TestDemo(unittest.TestCase): def test_01(self): # 每条测试用例下面通过"""备注说明的内容,为测试报告中的用例描述 """用户登录成功""" self.assertEqual(11,11) @rerun(3, 1) def test_02(self): """账号不能为空""" self.assertEqual('',22) def test_03(self): """密码错误""" self.assertEqual(33,34) def test_04(self): """账号错误""" self.assertEqual(44,45)
b> 重运行匹配数据驱动ddt使用时,@rerun() 要在测试数据之后装饰 test_demo.py
import unittest from unittestreport import rerun from unittestreport.core.dataDriver import ddt,list_data,yaml_data,json_data # yaml数据驱动 yaml文件每条数据的title字段为测试报告中每条测试用例的用例描述 @ddt class TestDemoYaml(unittest.TestCase): @yaml_data(r'case_data.yaml') @rerun(3, 2) # @rerun要放在@yaml_data之后装饰 def test_yaml(self,case): self.assertEqual(case['data']['aa'],case['data']['bb']) # json数据驱动 json文件每条数据的title字段为测试报告中每条测试用例的用例描述 @ddt class TestDemoJson(unittest.TestCase): @json_data(r'case_data.json') def test_json(self,case): self.assertEqual(case['data']['aa'],case['data']['bb'])
c> 运行结果中 test_yaml测试用例方法 运行失败的用例都会重运行,用例会执行3次,每次间隔为2S,test_json 测试用例方法,运行失败的用例不会重运行;
2> 运行用例调用 rerun_run() 方法,可以让所有测试用例中运行失败的用例重运行 run.py;
import unittest from unittestreport import TestRunner # 一步完成用例加载 suite = unittest.defaultTestLoader.discover(r'D:python_lemon37python基本语法day15_unittestunittestreport_demo', pattern='test*.py') # 生成unittestreport报告 runer = TestRunner(suite, filename="unit_report.html", report_dir=".", title='测试演示', tester='天天', desc="理赔项目测试报告", templates=1) # runer.run() runer.rerun_run(2,1) # 所以测试用例运行失败时,都会重运行
PS:对单个用例设置重运行机制:在用例方法上面直接使用@rerun()来指定重运行的次数和运行的时间间隔;
对所有用例设置重运行机制:直接使用rerun_run()方法来运行用例;
21. unittestreport 多线程运行用例:考虑用例在执行时,上下用例可能存在前后依赖关系,所以该多线程的设计是基于用例测试类之间的并发(不是每个测试用例的多并发),所以用例测试类之前不能存在先后依赖关系,否则多线程执行用例时,就会导致用例执行失败;
1> 测试用例代码: test_thread.py,单线程执行时最少需要30S
1 import time 2 import unittest 3 from unittestreport.core.dataDriver import ddt,list_data 4 5 6 @ddt 7 class TestThread(unittest.TestCase): 8 9 @list_data(range(10)) 10 def test_demo(self,case): 11 time.sleep(1) 12 13 @list_data(range(10)) 14 def test_login(self, case): 15 time.sleep(1) 16 17 @list_data(range(10)) 18 def test_register(self, case): 19 time.sleep(1)
2> 运行用例脚本:run.py,3个线程执行时,时间大概为10S多
1 import unittest 2 from unittestreport import TestRunner 3 4 # 一步完成用例加载 5 suite = unittest.defaultTestLoader.discover(r'D:python_lemon37python基本语法day15_unittestunittestreport_thread', 6 pattern='test*.py') 7 8 # 生成unittestreport报告 9 runer = TestRunner(suite, 10 filename="thread_report.html", 11 report_dir=".", 12 title='测试演示多线程执行用例', 13 tester='小夕', 14 desc="理赔项目测试报告", 15 templates=1) 16 17 # 多线程运行用例 18 runer.run(thread_count=3)
3> 多线程注意事项:
a> 确保每个用例测试类没有先后依赖关系;
b> 确保每个线程任务(用例测试类)在执行的时候不会出现资料竞争(对全局依赖的数据进行修改);
PS:各个用例测试类之间使用多线程并发执行以提高测试用例执行效率,但是每个用例测试类中的用例仍是让其顺序执行的,以保证用例测试类中的用例先后依赖正常执行;
22. unittestreport测试结果发送邮件
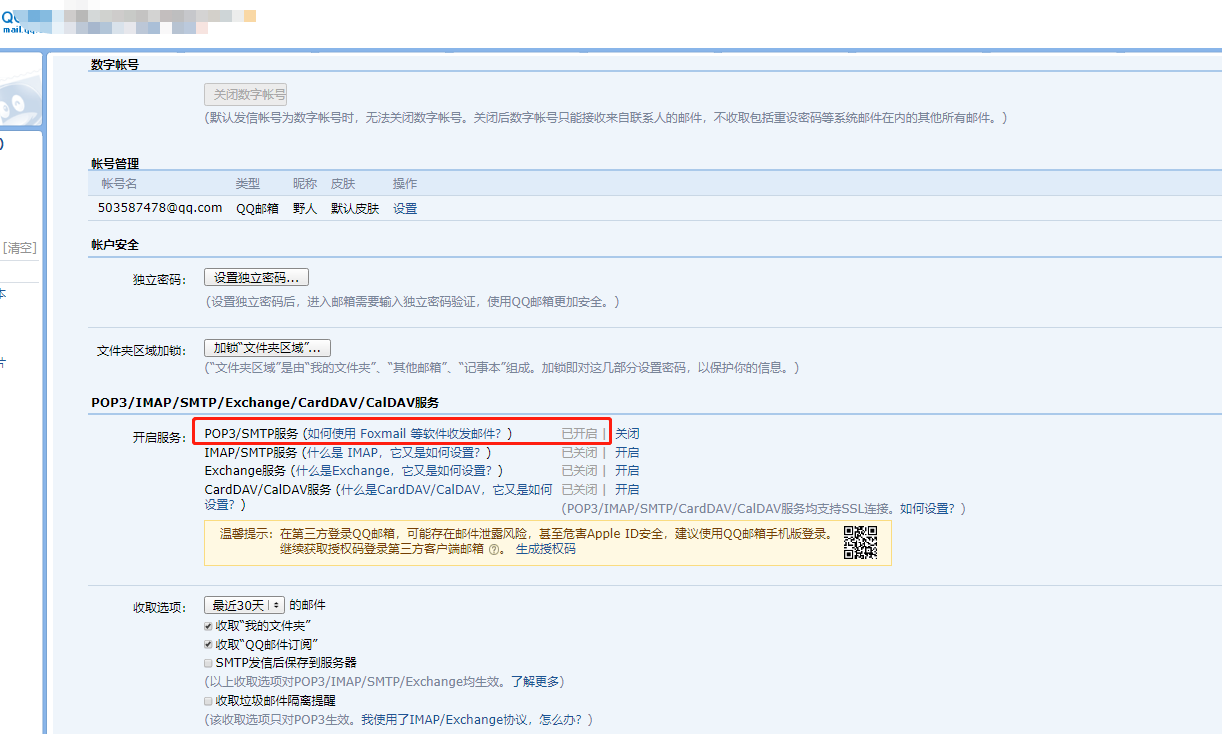
1> 开启qq邮件的SMTP服务,获取到授权码
2> 发送邮件代码如下:run.py
import unittest from unittestreport import TestRunner # 一步完成用例加载 suite = unittest.defaultTestLoader.discover(r'D:python_lemon37python基本语法day15_unittestunittestreport_thread', pattern='test*.py') # 生成unittestreport报告 runer = TestRunner(suite, filename="thread_report.html", report_dir=".", title='测试演示多线程执行用例', tester='小夕', desc="理赔项目测试报告", templates=1) # 多线程运行用例 runer.run(thread_count=3) # 发送邮件 host, port, user, password-授权码, to_addrs runer.send_email(host='smtp.qq.com', port='465', user='503587478@qq.com', password='izxxoylgjlkqbiih', to_addrs=['503587478@qq.com','240911074@qq.com'])
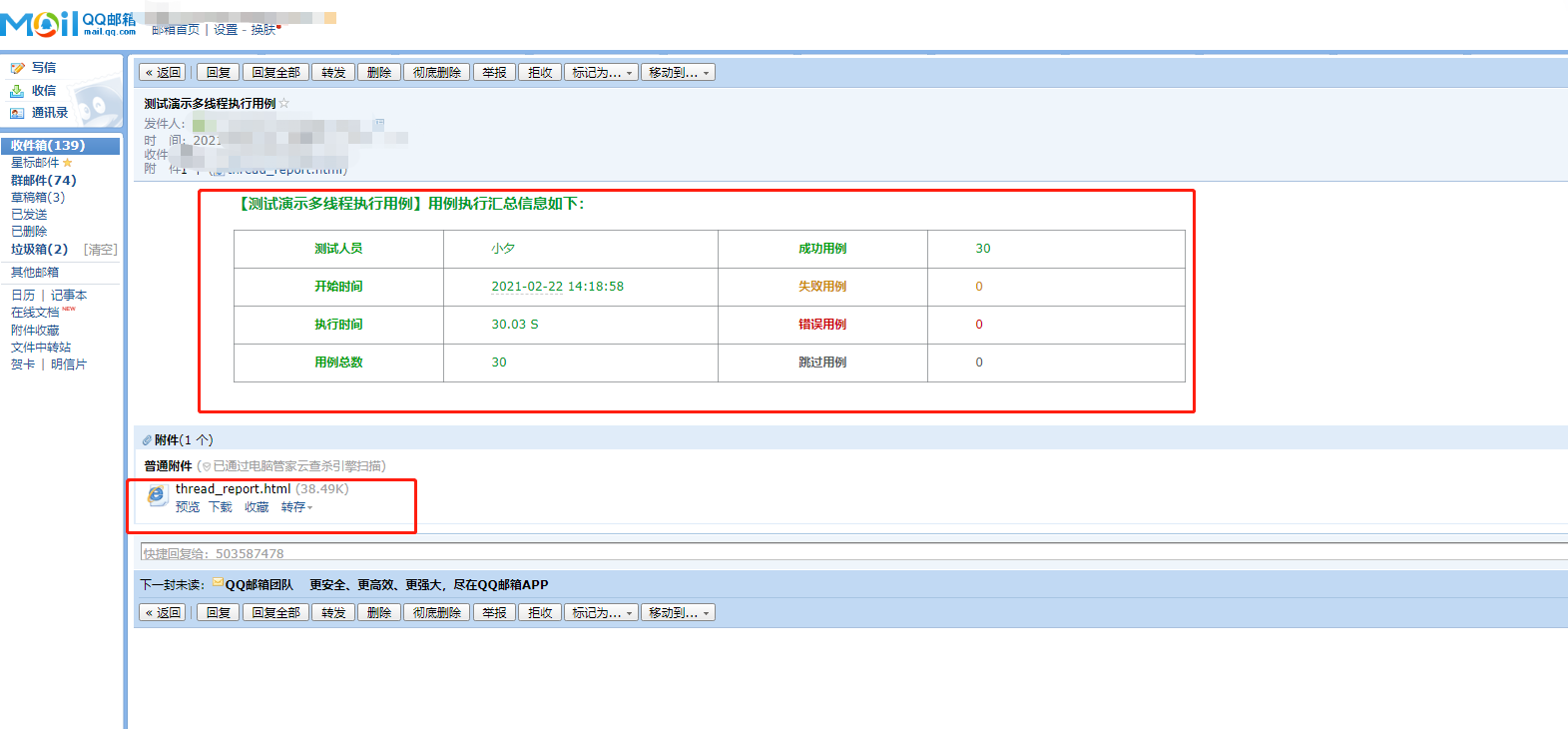
3> 邮件收到内容如下:
23. unittestreport测试结果发送到钉钉群
1> 在钉钉自定义一个机器人,获取到该机器人的webhook地址
2> 调用发送消息给钉钉的方法 runer.dingtalk_notice(url,key='自动化')
a> url:webhook地址;
b> key:自定义机器人时,安全设置中的自定义关键词,如为 自动化;
c> secret:自定义机器人时,安全设置中的加签;
d> atMobiles:发送通知钉钉中要@人的手机号列表;
import unittest from unittestreport import TestRunner # 一步完成用例加载 suite = unittest.defaultTestLoader.discover(r'D:python_lemon37python基本语法day15_unittestunittestreport_demo', pattern='test*.py') # 生成unittestreport报告 runer = TestRunner(suite, filename="unit_report.html", report_dir=".", title='测试演示', tester='天天', desc="理赔项目测试报告", templates=1) runer.run() # 测试结果发送钉钉群 -- 一家人 # 1. 给钉钉群自定义机器人时,安全设置的自定义关键词(key), 加签(SEC668f9f9711694d052c95cd4320ce6e9ab5bb5e0de1c42fe4ca2a371da5afa7a1) secret = 'SEC668f9f9711694d052c95cd4320ce6e9ab5bb5e0de1c42fe4ca2a371da5afa7a1' # 2. 给钉钉群自定义机器人后得到的webhook地址 url='https://oapi.dingtalk.com/robot/send?access_token=7fe2f381892d5c3938bbdcca138342afce05cb0a8ba29cf7e222824104381c7d' # 3. atMobiles: 发送通知钉钉中要@人的手机号列表 # 4. 推荐消息给钉钉 res = runer.dingtalk_notice(url,key='自动化',secret=secret) print(res) # 返回是否发送成功
24. unittestreport测试结果发送到企业微信群
1> 调用发送消息给企业微信的方法 runer.weixin_notice()
a> chatid: 企业微信群ID
b> access_token: 调用企业微信API接口的凭证
c> corpid: 企业ID
e> corpsecret:应用的凭证密钥
2> 以上相关参数的值获取可以查看连接: https://work.weixin.qq.com/api/doc/90001/90143/90372
3> 测试结果推送到企业微信群,【access_token】和【corpid,corpsecret】至少要传一种
import unittest from unittestreport import TestRunner # 一步完成用例加载 suite = unittest.defaultTestLoader.discover(r'D:python_lemon37python基本语法day15_unittestunittestreport_demo', pattern='test*.py') # 生成unittestreport报告 runer = TestRunner(suite, filename="unit_report.html", report_dir=".", title='测试演示', tester='天天', desc="理赔项目测试报告", templates=1) runer.run() # 测试结果发送企业微信 runer.weixin_notice(chatid='', access_token=None, corpid=None, corpsecret=None)
24. python的RSA加解密
1> pycrypto,pycrytodome和crypto是一个东西,crypto在python上面的名字是pycrypto它是一个第三方库,但是已经停止更新三年了,所以不建议安装这个库;
2> windows下python3.6安装也不会成功!这个时候pycryptodome就来了,它是pycrypto的延伸版本,用法和pycrypto 是一模一样的;
3> 安装pycrytodome: pip install pycryptodome
4> 在使用的时候导包是有问题的,会报错:
解决方案:这个时候只要修改一个文件夹的名称就可以完美解决这个问题
python的安装路径下:Python36Libsite-packages
下面有一个文件夹叫做crypto,将c改成C,对就是改成大写就ok了!!!
25. RSA公私钥加解密: 使用公钥来加密信息,然后使用私钥来解密
1> 基于已有的公钥(字符串) 和 私钥(字符串) 进行RSA加密:
import base64 import json from Crypto.PublicKey import RSA from Crypto.Cipher import PKCS1_v1_5 #lxPubKey 公钥 lxPubKey="MIGfMAfegwggwogewgzCqynB+h7GNADCBiQKBgQDczg7E4gLH5DCBILt5Ooz5G8bRxBL2idtvwkFNZ3wdY2/l9zWUI5yD/x+fH8YF0LkO5S7QCxHcrdIKPrKnJE3I5cz1HykP31etvQ6gD6ohBOy67mfiUDjLFx8e68S+FJvpJdfeogwggew" #lxPriKey 私钥 lxPriKey="MIICdgIBADANBgkqhkiG9w0BAQEFAASCAmAwggJcAgEAAEGWGegosgiwgwggu3k5HEEvaJ22/CQU1nfB1jb+X3NZQjnIP/H58fxgXQuQ7lqcfKQ/fV629DqAPqjPkbxuiEE7LruZ+JQOMsXcrzFkKa3uTtBOa6Xk2R61zBkucEGWGWsgwoegogwbwxTQJBAP0wGenVOq4dCPdhyghkKT6SL2w/SgbrROiJ1mG9MoBq58/0gk85I91R7nuvOYTKTUkhWdPYITpDarmPJzesCQGRBmOMgHCHH0NfHV3Gn5rz+61ebIoyD4uar4P7RrRvQg5mFZFDafVHapceh4CsWCiyAfzhj9229sTecvdbr68Lb0zphO3I5EMfqPbTSq2oZq8thvGlyFyI7SNNuvAHjRFoPP6WoVoxp5LhWHT2l/DqqWakImXA0eZYNny0vETQJAVHsQUZaLOzexEKcujo1/YH6A0dSEbTkxHr3aJh8IVh3SzT5ejdYutVrdi1c8+R9Zg==" data_dict={"creditApplyNo": "O201806108205659"} data_str=json.dumps(data_dict) print(data_str) def rsa_encrpyt(encryptstr, publickey): encryptstr = bytes(encryptstr, encoding='utf-8') publickey = base64.b64decode(publickey) rsakey = RSA.importKey(publickey) cipher = PKCS1_v1_5.new(rsakey) pkcs1_padding_text = cipher.encrypt(encryptstr) cipher_text = base64.b64encode(pkcs1_padding_text) return str(cipher_text, encoding='utf-8') print(rsa_encrpyt(data_str,lxPubKey))
2> 基于标准的 .pem文件进行rsa加解密:
import rsa import base64 # 1.先生成一对密钥,然后保存.pem格式文件 (pubkey, privkey) = rsa.newkeys(1024) pub = pubkey.save_pkcs1() pubfile = open('public.pem','wb+') pubfile.write(pub) pubfile.close() pri = privkey.save_pkcs1() prifile = open('private.pem','wb+') prifile.write(pri) prifile.close() # 2.load rsa公钥和rsa密钥 message = 'lovesoo.org' print("原信息:",message) with open('public.pem','rb') as publickfile: p = publickfile.read() pubkey = rsa.PublicKey.load_pkcs1(p) with open('private.pem','rb') as privatefile: p = privatefile.read() privkey = rsa.PrivateKey.load_pkcs1(p) # 3.用公钥加密、再用私钥解密 message_byte = message.encode('utf-8') crypto_byte = rsa.encrypt(message_byte, pubkey) #加密出来的字节 cryp_msg = base64.b64encode(crypto_byte).decode("utf-8") # base64编码 print("加密后的信息:",cryp_msg) decry_msg = rsa.decrypt(crypto_byte, privkey) message_str = decry_msg.decode('utf-8') print("解密后的信息:",message_str) # 4.sign 用私钥签名认证、再用公钥验证签名 signature = rsa.sign(decry_msg, privkey, 'SHA-1') rsa.verify(b'lovesoo.org', signature, pubkey)
运行脚本后,生成的.pem文件如下: