1. sed会逐行从文件中读取数据, 再对数据处理后显示到屏幕, 再进行下一行的处理.
sed '4d' file.txt # 删除文件中第4行
sed '2,6d' file.txt # 删除文件中的2-6行
sed '5,$d' file.txt # 从第5行删除到最后一行
sed '/root/d' file.txt # 删除含root字符的行
sed '/root/,5d' file.txt # 前5行中有root则从root行删到第5行, 注意第5行会保留
sed '/root/,+3d' file.txt # 删掉有root行, 并向后删3行.
sed '/root/!d' file.txt # 取反删除, 留下root行
sed '1~2d' file.txt # 删除奇数行, 从1开始, 每隔2行删除
sed '0~2d' file.txt # 删除偶数行, 从0开始, 每隔2行删除
2. sed中的正则使用:
sed同grep命令一样, 默认不支持扩展元字符, 解决办法:
1. 将扩展元字符加对应斜线变为基本元字符.
2. sed -r 加入-r参数, 使其支持扩展元字符.
3. sed的查找替换使用:
替换的使用:
1. sed -r 's/xx/XX/' # 替换xx为XX, 只替换每行的第一个
2. sed -r 's/xx/XX/g' # 替换整行中的所有xx为XX
3. sed -r 's/xx/XX/gi' # 忽略行中内容的大小写进行匹配替换
查找的使用:
1. sed -r '/xx/d' # 查找时不要使用s, 查找xx并删除
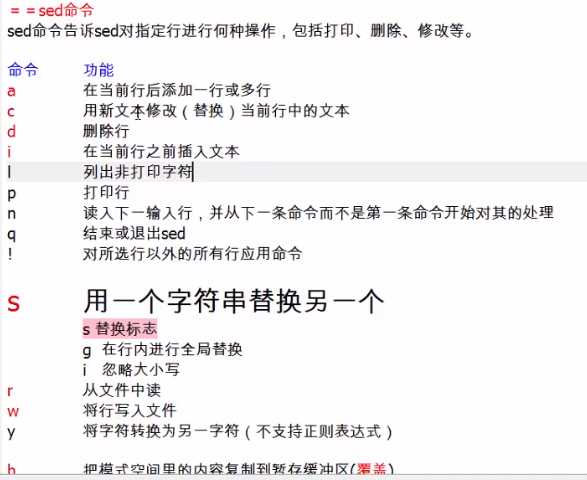
4. sed的命令选项 (注意是命令, 在引号中使用的, 注意要和-后的参数区分):
5. sed的功能选项( 即-后的参数值, ):

6. &符合的作用, 就是代表, 代指, 代替的作用
如在vim中需要给3-5行内容注释掉的写法如下:
:3,5 s/(.*)/#1/ # 解释, vi中模式识别基本正则元字符, 括号中.*代表整行, 括号两边使用给转义了, 这正是shell中正则基本元字符的形式
:3,5 s/.*/#&/ # 作用同上, &符合就代替了前面.*, 即整行内容
:% s/.*/#&/ # %表示作用到每一行, &符合就代替了前面.*, 即整行内容
注意&号代表的是前面正则匹配到的内容, 如果匹配到的是行中的一个字符, 则就是在这个字符前加#, 注意区分正则匹配到的到底是什么
:3,5 s/^/#/ # 3-5行加注释, 解读: 把3-5行的开始符号替换为#号.
以上在vi中的写法, 在sed命令中用法一模一样, 如下:
sed '3,5s/(.*)/#1/' file.txt # 如果使用-r参数, 则括号两边的转义可去掉, 因为-r参数识别的就是扩展元字符
sed '/root/s///' file.txt # sed也有这种用法, s前面的内容可理解为替换的作用范围, 3,5或者/root/都是, 规定作用行数,或包含root的行