这次作业我负责的部分是把爬取完的聊天记录经行数据挖掘以及经行各种普通过滤高级过滤等。
运行截图如下:
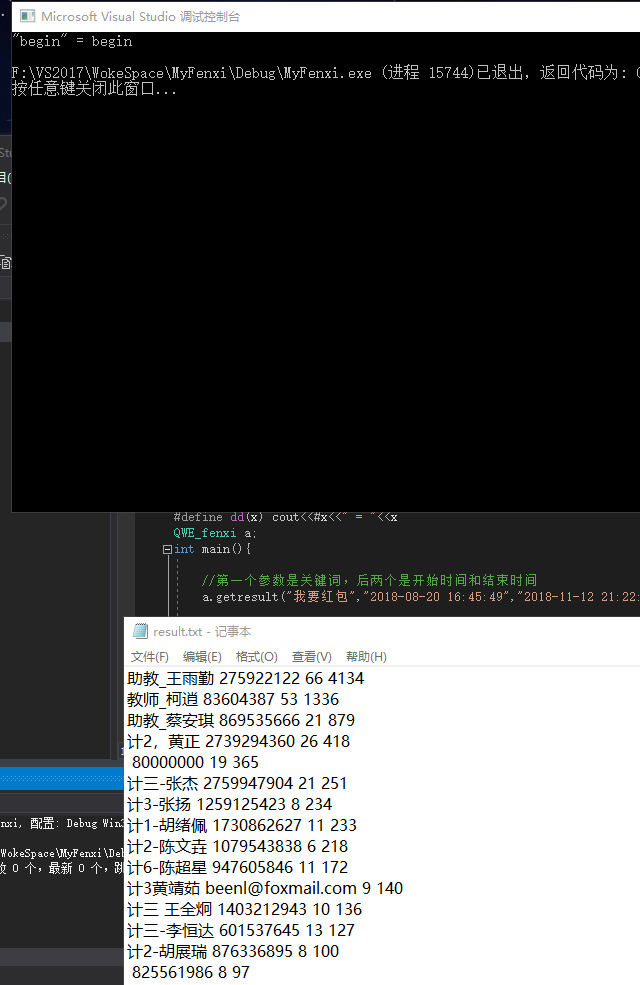
数据分为四部分:账户名、qq/邮箱、包含关键词的发言次数、包含关键词的发言字数。
遇到的困难及解决方法:
困难1: 遇到最烦的就是当时读取record文件当中的汉字会产生乱码,以前没有遇到过这种情况,还以为是因为读取的方式错了,弄了一个上午。
解决方法1: 当时百度了好久,用了很多方法都没用,最后灵机一动,发现可能是txt编码错了,果然,把utf-8改成ANSI就不会出现乱码了。
困难2:作业提供的record文件里面关于聊天记录的爬取很令人不满,人发的内容爬取的时候并没有压缩成一行,很乱。
解决方法2:自己的事情自己做。
马后炮:
要不是作业提供的文件编码格式不对,内容格式不整齐,那就不用花费怎么多时间浪费在这里了,还能多做一些其他东西,晦气。