
JVM偏理论,主要靠背 面试题
JVM的位置
JVM在操作系统之上,和其他的应用软件层级并列,在之上可以跑java程序
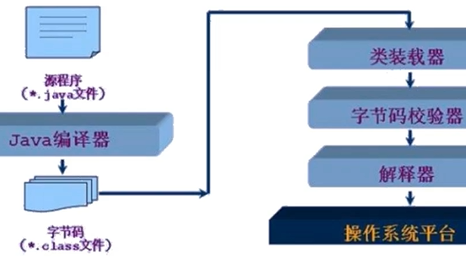
.java => class文件 => 类加载器 Class Loader =>运行时数据区
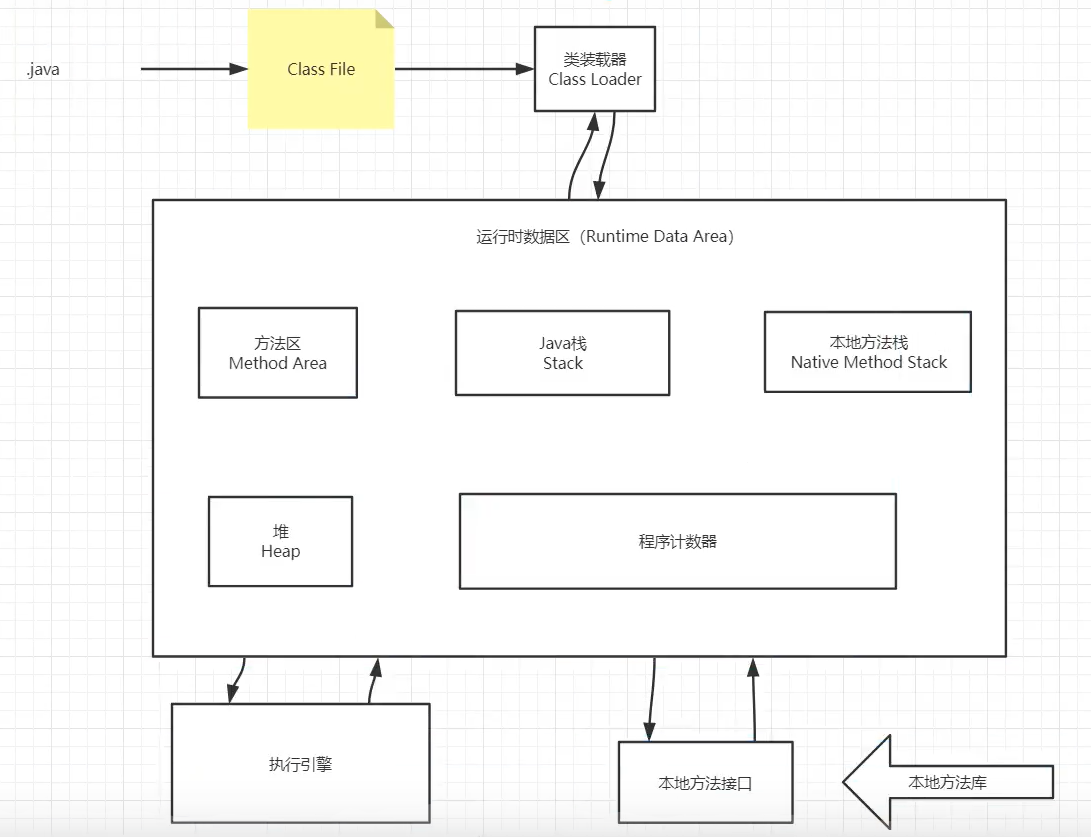
JVM 架构图
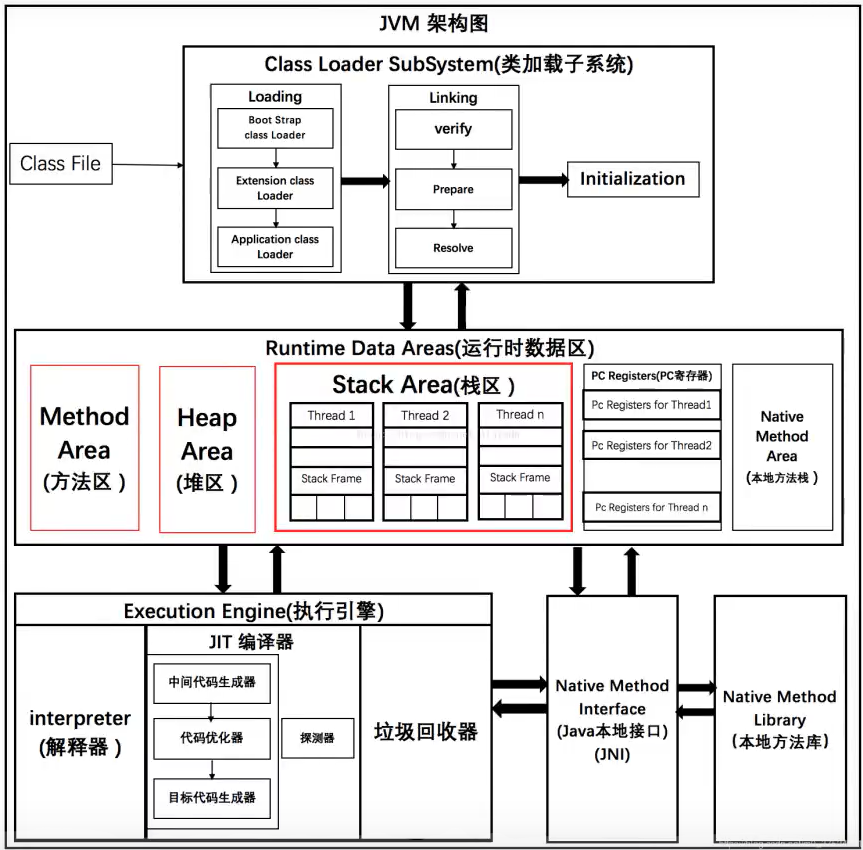
类加载器 ClassLoader
类加载器细分:
1. bootStrap - 根 类加载器(jre/ lib/ rt.jar)
2. ext - 扩展加载器 (jre/ lib/ ext/ ...)
3. app - 应用程序(系统类) 加载器,最常用
双亲委派机制
选择类加载器的顺序:
bootStrap->ext->app->custom。先找boot,再找ext、app,最后找costom也就是自己写的。都找不到就报错Class Not Found

好处:
防止用户乱定义类:比如自定义一个String类,这时会先从BootStrap找,所以不会轮到自定义的String类
沙箱安全机制
Java安全模型的核心是 沙箱 sandbox
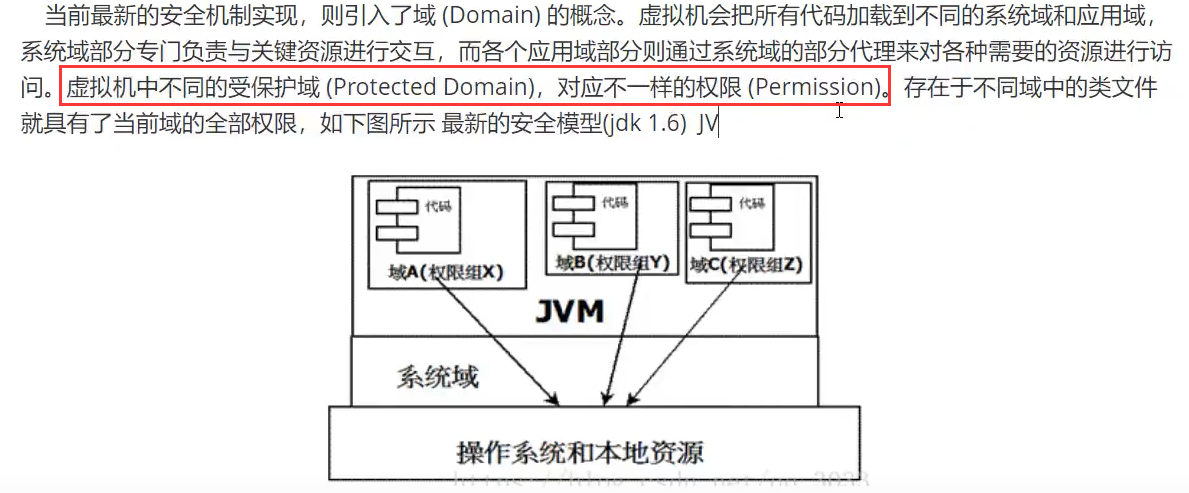
组成沙箱的基本组件:
字节码校验器(bytecode verifier): 确保遵循java语言规范,帮助实现内存保护;核心类不参与校验;
类加载器:双亲委派机制 + 将代码归入保护域
Native
例子:
private native void start0(); //java的范围达不到了,要调用C++的库了 //会进入本地方法栈,然后调用本地方法接口JNI(Java Native Interface)
进入本地方法栈,然后调用本地方法接口JNI(Java Native Interface)
JNI的作用:扩展Java的使用,一般用于驱动硬件
三种JVM
Sun公司:HotSpot、OpenJDK
其他:JRockit、J9VM
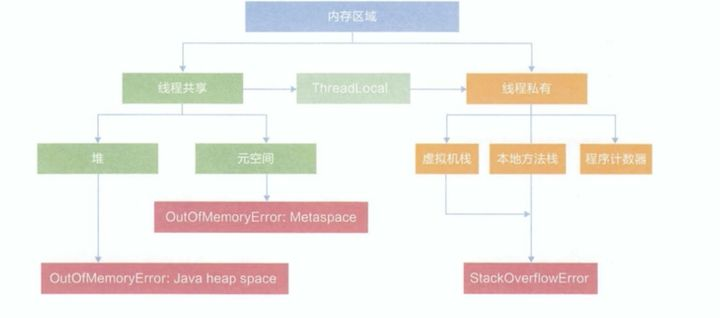
程序计数器PC
每一个线程私有的,指向下一条指令的地址
PC寄存器:仅存一个指针,占用空间非常小
方法区(内含常量池)
方法区被所有线程共享,
方法区含有:静态变量static、常量final、类信息(构造方法、接口定义)、运行时的常量池
=> static + final + Class + 常量池
(堆:实例变量)
栈
 每一个方法内部结构 =》
每一个方法内部结构 =》 栈帧
栈帧
栈内存的生命周期 和线程同步
线程结束,栈内存就释放了;所以对于栈来说,不存在GC垃圾回收
栈的内容:8大基本类型 + 对象引用 + 实例的方法
栈溢出:StackOverflowError 是比较严重的错误
堆
Heap,一个JVM只有一个堆内存,
堆内存的大小是可以调节的
 =》
=》 这两个用于调参
这两个用于调参
堆中的内容:
实例对象中的 方法、常量、变量
堆内存细分为3个区域:
新生区 young
老年区 old
永久区 perm

新生区-伊甸园 ,经过轻GC,到幸存区,再经过重GC,到老年区;
层层筛选后,等老年区也满了,就会OOM内存溢出
经验:99%的对象都是临时对象。
新生区
老年区
永久区(元空间)
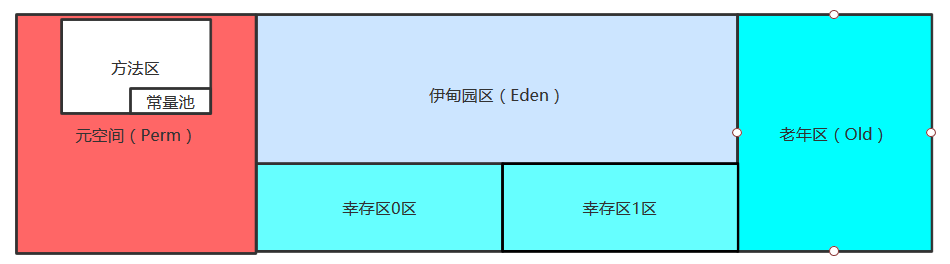 ==》元空间在逻辑上存在,但是在物理上是不存在的
==》元空间在逻辑上存在,但是在物理上是不存在的
元空间,常驻内存。关闭JVM会释放这个区域的内存。
用来存放JDK自身携带的Class对象,被所有的线程、对象共享;
Interface元数据,存储的是Java运行时的一些环境or类信息,这个区域不存在垃圾回收
永久区OOM:
当一个启动类,加载了大量的第三方jar包;
Tomcat部署了太多的应用;
大量动态生成的反射类
JVM调优
常用JVM调优参数
堆内存调优
public class Test { public static void main(String[] args) { long max = Runtime.getRuntime().maxMemory(); System.out.println("max = " + max/1024/1024 + "MB"); long total = Runtime.getRuntime().totalMemory(); System.out.println("total = " + total/1024/1024 + "MB"); //默认max=1/4的总内存; total=1/64的总内存 } }
![]() 这台电脑的内存为32GB
这台电脑的内存为32GB
Configuration里面的VM Options设置为:
-Xms1024m -Xmx1024m -XX:+PrintGCDetails
 jvm参数非常非常多,可以到网上去查到
jvm参数非常非常多,可以到网上去查到
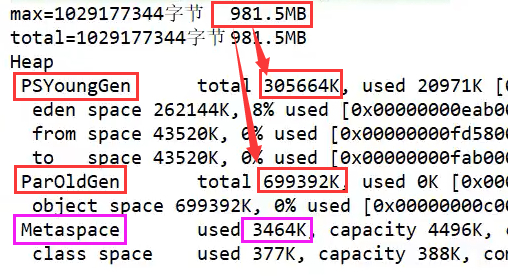 这里的总空间=新生区+老年区,不包括逻辑上的元空间
这里的总空间=新生区+老年区,不包括逻辑上的元空间
制造OOM:
-Xms2m -Xmx2m -XX:+PrintGCDetails ##设置堆的大小为2m
public class Test { public static void main(String[] args) { long max = Runtime.getRuntime().maxMemory(); System.out.println("max = " + max/(double)1024/1024 + "MB"); long total = Runtime.getRuntime().totalMemory(); System.out.println("total = " + total/(double)1024/1024 + "MB"); //默认max=1/4的总内存; total=1/64的总内存 String str = "123"; while(true){ str+="111"; } } }
解决OOM:
1)扩大堆内存,试下能不能解决
2)内存快照分析工具
Jprofiler 作用:
- 分析Dump内存文件,快速定位内存泄漏
- 获得堆中的数据
- 获得大的对象
 插件
插件
设置dump导出错误信息:
-Xms1m -Xmx10m -XX:+HeapDumpOnOutOfMemoryError
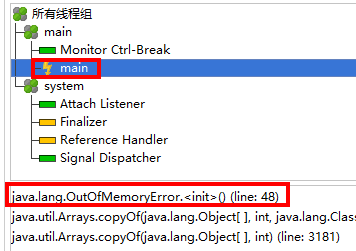
public class Test { public static void main(String[] args) { long max = Runtime.getRuntime().maxMemory(); System.out.println("max = " + max/(double)1024/1024 + "MB"); long total = Runtime.getRuntime().totalMemory(); System.out.println("total = " + total/(double)1024/1024 + "MB"); //默认max=1/4的总内存; total=1/64的总内存 byte[] array = new byte[1*1024*1024]; //1M ArrayList<Test>list = new ArrayList<Test>(); int count = 0; try { while(true){ list.add(new Test()); //问题所在 count++; } } catch (Error e) { System.out.println("count = " + count); e.printStackTrace(); } } }
执行上述程序,生成:Dumping heap to java_pid3044.hprof
1)双击打开,查看![]()
 就知道哪里导致占用大量内存的问题了
就知道哪里导致占用大量内存的问题了
2)点击 ![]()
GC:
垃圾回收主要针对堆, (少量方法区)
堆空间
主要划分为:新生区、老年区、永久区
新生区分为:伊甸园区、幸存区(两半,0区+1区,轮流倒)8:1:1 (8:1:1比例可以调,留存率高就降低伊甸园区大小)
需要回收:死对象
判断对象生死?两个方法:
1)引用计数器法:
给对象添加一个引用计数器,每当被引用时加 1,失效时减 1,任何时刻计数器为 0 的对象是不可能再被引用的。
问题:如果两个对象循环引用,则计数器永远不为0,无法回收。
2)可达性分析算法:
每个对象,抽象为一个Node节点,
从一系列GC Roots Set 中的根出发,不断遍历,如果没有任何引用相连,则不可达。
(这样可以解决循环引用问题)
Java中4种引用类型:
JDK1.2 之后,将引用分为:强引用、软引用、弱引用、虚引用,强度依次减弱。
总结:强引用只要还在就不会回收,软引用会在溢出前回收,弱引用在下次回收时回收,虚引用仅会在回收时发送通知。
强引用(最常用):
普遍存在,类似 Object obj = new Object(),只要强引用还存在,GC 就无法回收它。
软引用:
描述一些还有用但非必须的对象。系统快发生溢出前,会把这些对象列进回收范围之中进行第二次回收。SoftReference 类来实现。
弱引用:
描述非必须对象,此类对象只能生存到下一次垃圾回收发生之前,无论内存是否够,都会回收。WeakReference 类实现。
虚引用:
唯一目的是能在这个对象被GC时收到一个通知,不会影响对象生存时间也不会获得对象实例。PhantomReference 类实现。
GC 4个常用算法
1)引用计数法:
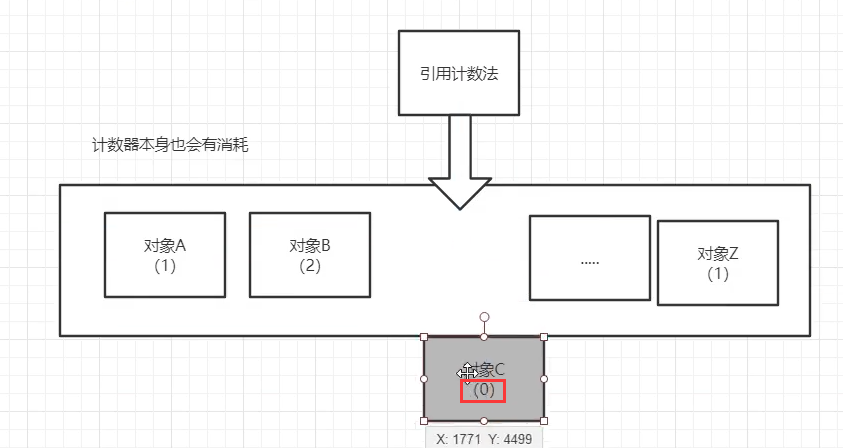
缺点:计数器本身损耗很多性能,效率不高
2)复制算法:
==》适用于复制率较低的 新生区(含:伊甸园区+2个幸存区)
两个幸存区轮流倒,from=>to,谁空谁是to
每次GC后,Eden区、from-幸存区 都是被倒空的
当1个对象经历15次GC,都还没有死,就会荣升 老年区
优点:没有内存的碎片,速度快
缺点: to区永远是空的,浪费了不少内存空间
3)标记-清除法(两轮)
flag标记是否存活,一次扫描是否存活、一次扫描清除死的对象
缺点:两次扫描浪费时间;内存碎片
优点:不需要额外的空间(相对于复制算法)
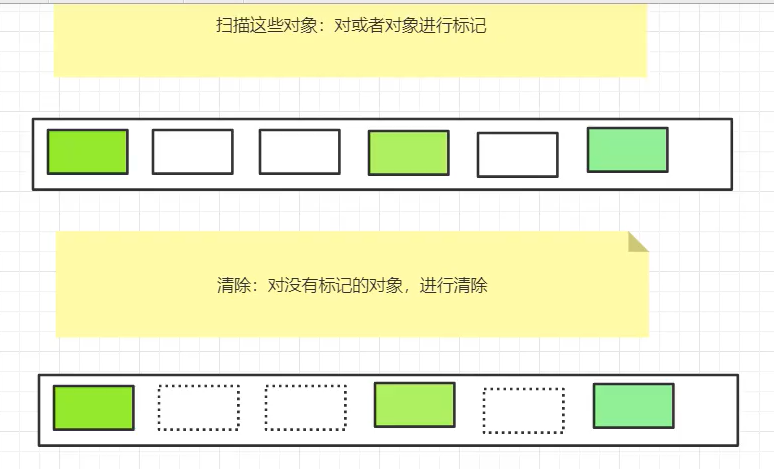
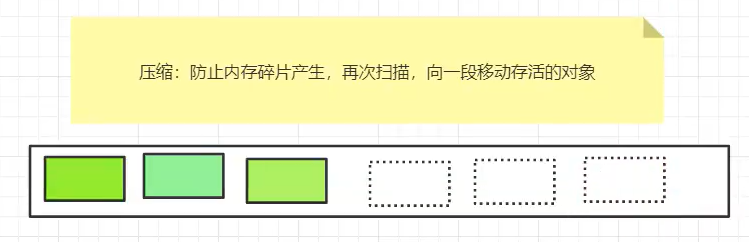
4)标记-整理法(标记+清除+压缩)(三轮)
防止内存碎片:增加一轮扫描,将对象移到一端;
5)分代收集算法
新生代 GC(Minor GC):指发生新生代的的垃圾收集动作,Minor GC 非常频繁,回收速度一般也比较快。
老年代 GC(Major GC/Full GC):指发生在老年代的 GC,出现了 Major GC 经常会伴随至少一次的 Minor GC(并非绝对),Major GC 的速度一般会比 Minor GC 的慢 10 倍以上。
大部分情况对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 Survivor 区,对象年龄加 1,当年龄增加到一定默认 15 岁时,就会被晋升到老年代中。同时,大对象将直接进入老年代。
3维度比较——时间、空间、碎片
(下面均是越左越好)
时间消耗:复制算法 < 标记清除 < 标记压缩
内存碎片:复制算法 = 标记压缩 < 标记清除
内存利用率:标记压缩=标记清除 > 复制算法
GC:分代收集算法
新生代GC(轻GC):(Minor GC)(伊甸园=》幸存区)
存活率低、复制率低;轻GC非常频繁
=> 复制算法(15次没死 进入老年区)
老年代GC(重GC):(Major GC/Full GC)(幸存区=》老年区)
区域大,存活率高;
=> 标记清除+标记压缩,混合实现(几次清除,一次压缩)
(老年区满了OOM)解决:
1)扩大堆内存,试下能不能解决
2)内存快照分析工具Jprofiler
垃圾收集器
主要5种: Serial、ParNew、Parallel Scavenge、CMS、G1
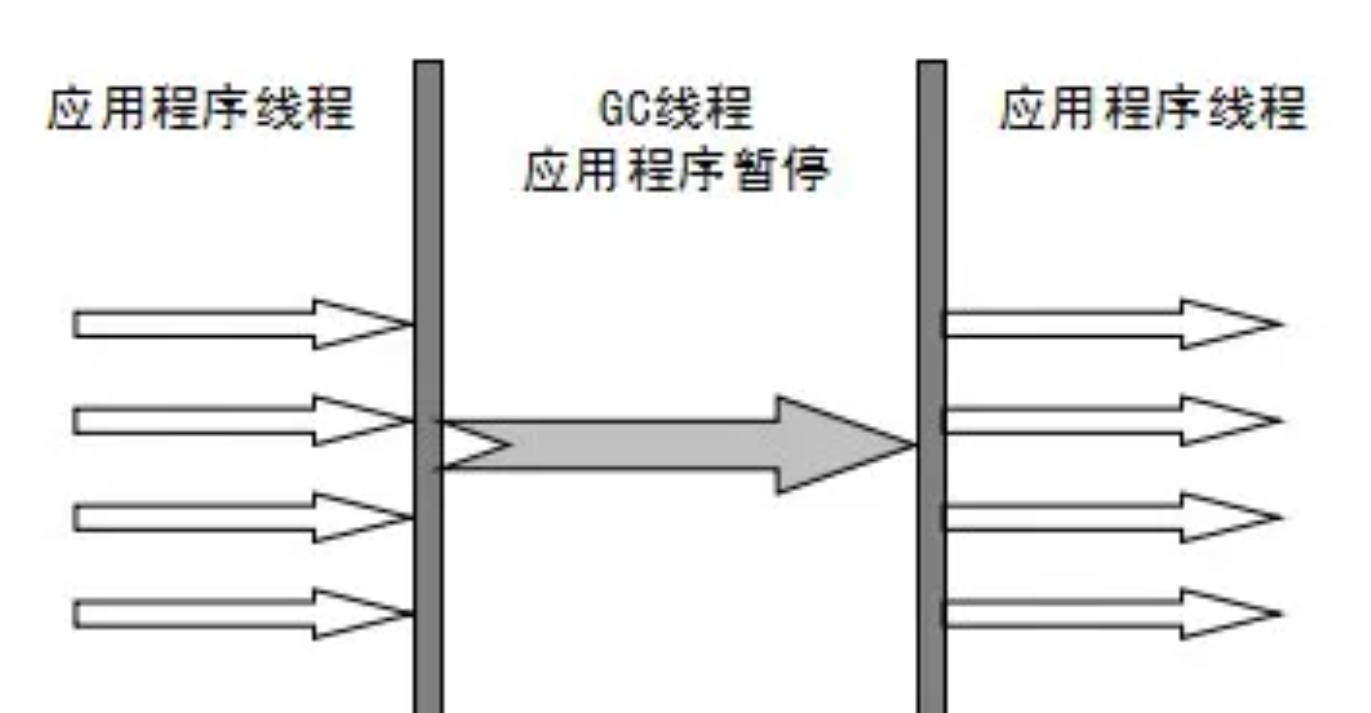
Serial:
单线程;简单而高效(与其他收集器的单线程相比);
新生代采用复制算法,老年代采用标记-整理算法。
ParNew:
ParNew 收集器,其实就是 Serial 的多线程版本。
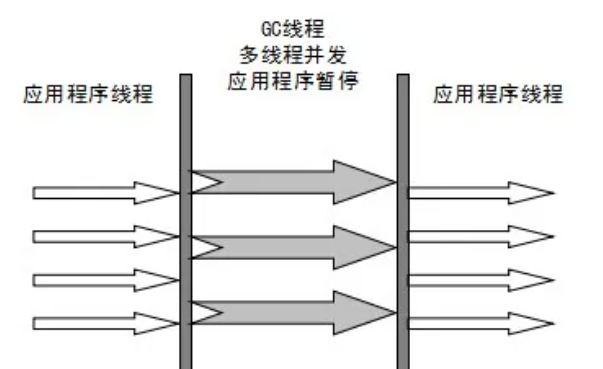
Parallel Scavenge:
几乎和 ParNew 一样,区别是:优化了CPU利用率,吞吐量提高了。
可设置 Parallel 收集器+ 老年代串行/老年代并行。
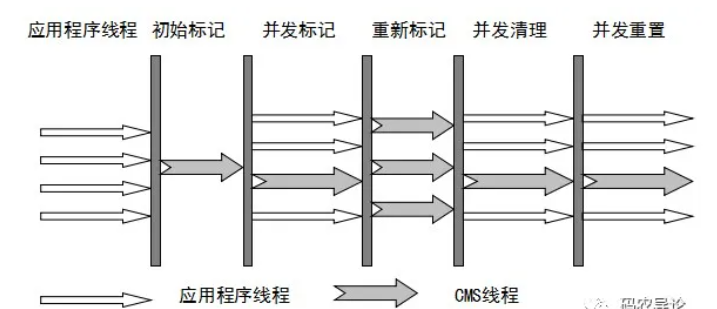
CMS:
是一个很好的收集器。GC的时候,用户线程几乎不停顿。
它是基于“标记-清除”算法。
优点:并发收集、低停顿
缺点:它用了“标记-清除”算法,会导致空间碎片。
4 个步骤:
1.初始标记:暂停其他线程,并记录下直接与 root 相连的对象,速度很快。
2.并发标记: GC 和用户线程,同时开启,记录可达对象。(标记法、可达法)
3.重新标记:暂停其他线程,更新上一阶段变动的。
4.并发清除:开启用户线程,同时 GC清理
G1:(Garbage-First)
基于“标记-整理”算法
优先回收 价值最大 Region
它针对:多处理器、大内存
G1 主要有并行与并发、分代收集、空间整合、可预测的停顿的特点。运作大致分为初始标记、并发标记、最终标记、筛选回收这四个过程。