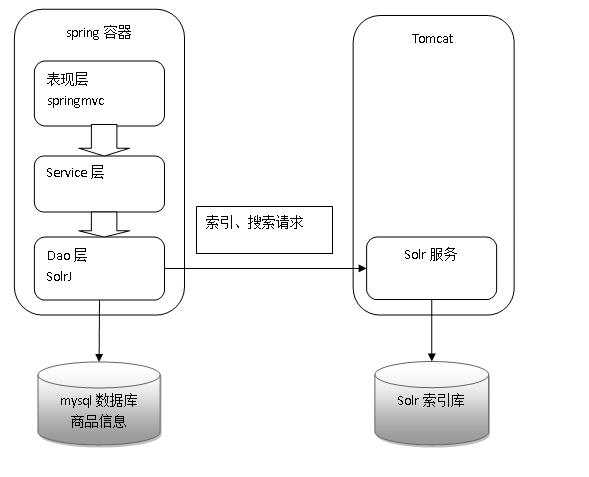
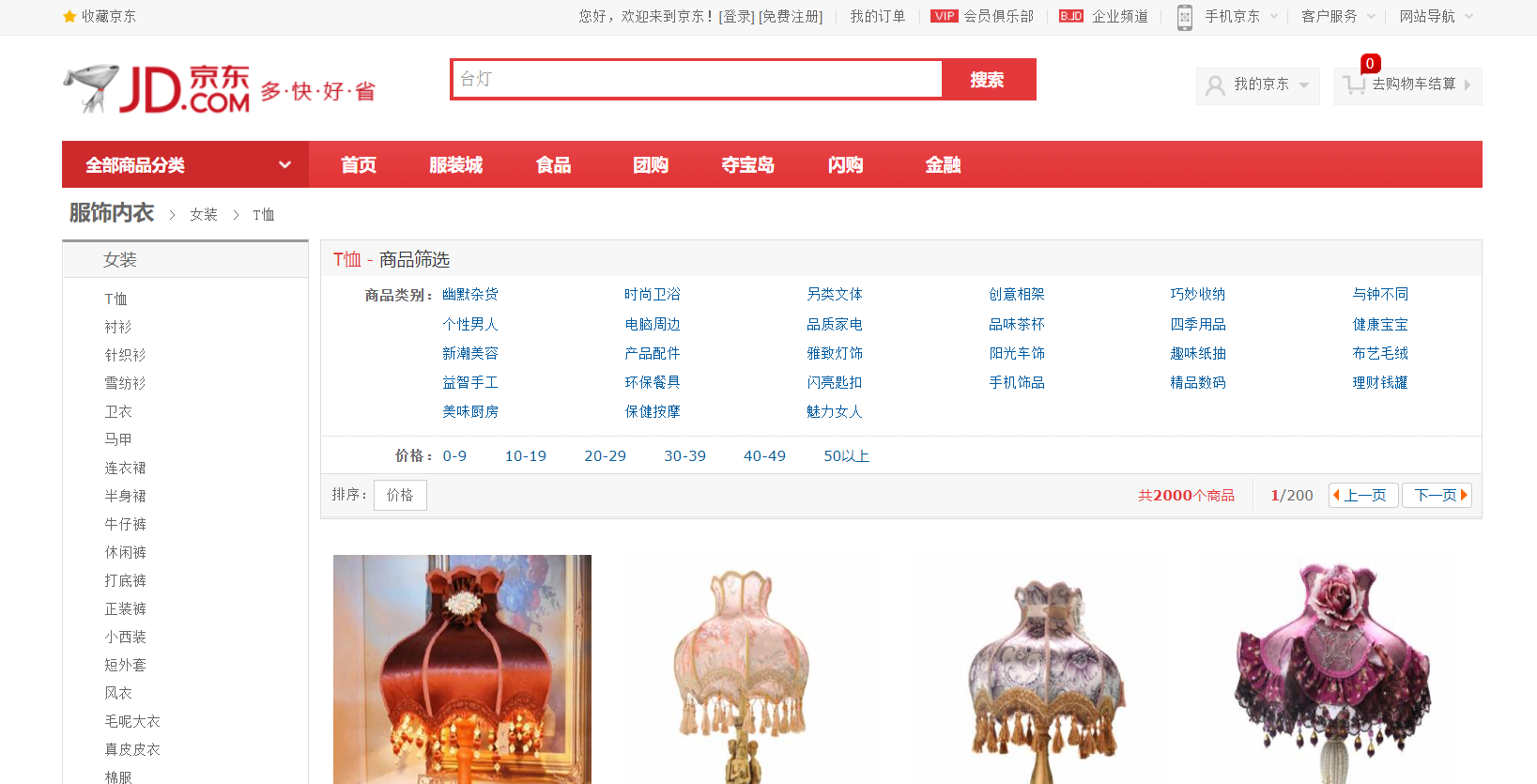
全文检索
应用-->站内搜索
lucene是基础,solr是框架
全文检索的过程:①创建索引,②对索引进行搜索
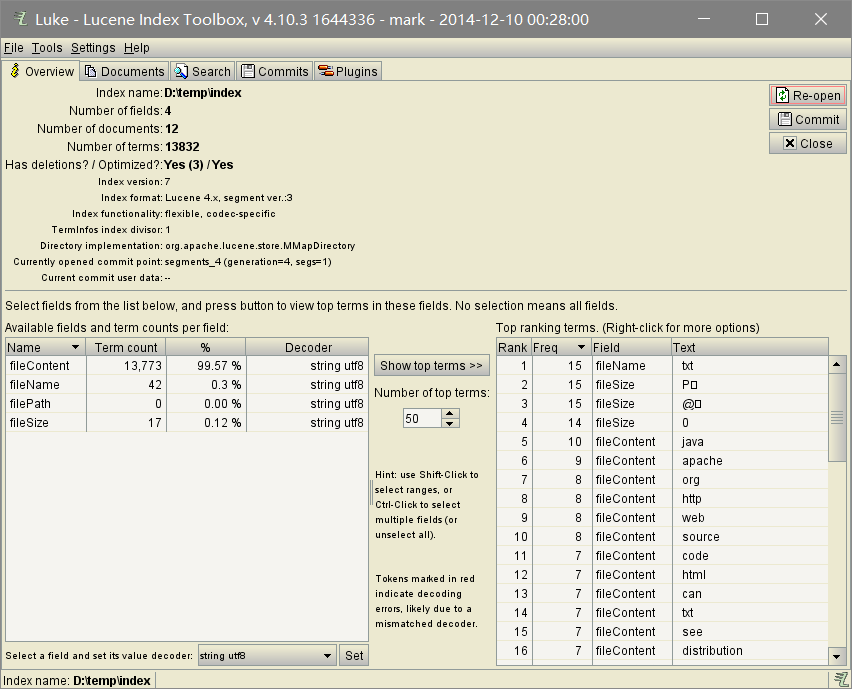
要针对其进行检索的源文件
创建完的索引文件
检索的效果
图示
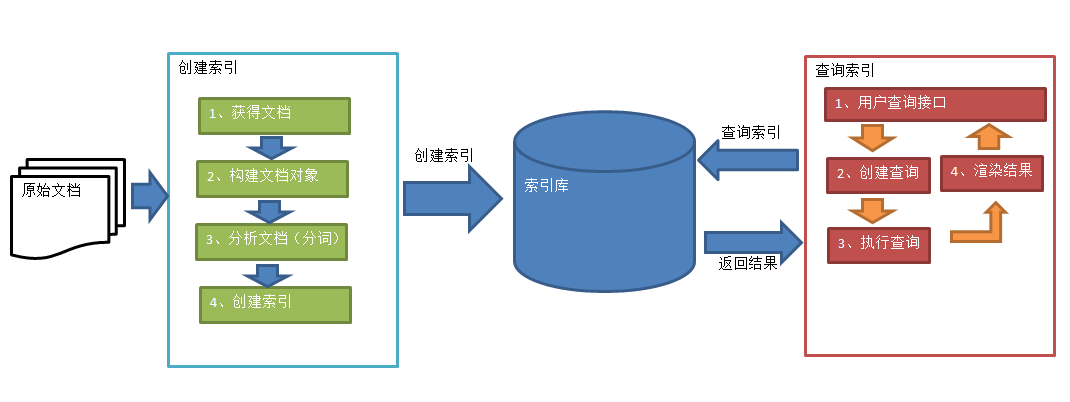
索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容-->采集文档-->创建文档-->分析文档-->索引文档
搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面-->创建查询-->执行搜索,从索引库搜索-->渲染搜索结果


import static org.junit.Assert.*; import java.io.File; import org.apache.commons.io.FileUtils; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.TokenStream; import org.apache.lucene.analysis.cjk.CJKAnalyzer; import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import org.apache.lucene.analysis.tokenattributes.OffsetAttribute; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.Field.Store; import org.apache.lucene.document.LongField; import org.apache.lucene.document.StoredField; import org.apache.lucene.document.TextField; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.Term; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TermQuery; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.store.RAMDirectory; import org.apache.lucene.util.Version; import org.junit.Test; import org.wltea.analyzer.lucene.IKAnalyzer; /** * Lucene 入门 创建索引 查询索引 * * @author lx * */ public class FirstLucene { // 创建索引 @Test public void testIndex() throws Exception { // 第一步:创建一个java工程,并导入jar包。 // 第二步:创建一个indexwriter对象。 Directory directory = FSDirectory.open(new File("D:\temp\index")); // Directory directory = new RAMDirectory();//保存索引到内存中 (内存索引库) // Analyzer analyzer = new StandardAnalyzer();// 官方推荐 Analyzer analyzer = new IKAnalyzer();// 官方推荐 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); // 1)指定索引库的存放位置Directory对象 // 2)指定一个分析器,对文档内容进行分析。 // 第三步:创建field对象,将field添加到document对象中。 File f = new File("F:\北大青鸟培训\框架学习\Lucene&solr\01.参考资料\searchsource"); File[] listFiles = f.listFiles(); for (File file : listFiles) { // 第三步:创建document对象。 Document document = new Document(); // 文件名称 String file_name = file.getName(); Field fileNameField = new TextField("fileName", file_name, Store.YES); // 文件大小 long file_size = FileUtils.sizeOf(file); Field fileSizeField = new LongField("fileSize", file_size, Store.YES); // 文件路径 String file_path = file.getPath(); Field filePathField = new StoredField("filePath", file_path); // 文件内容 String file_content = FileUtils.readFileToString(file); Field fileContentField = new TextField("fileContent", file_content, Store.NO); document.add(fileNameField); document.add(fileSizeField); document.add(filePathField); document.add(fileContentField); // 第四步:使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写入索引库。 indexWriter.addDocument(document); } // 第五步:关闭IndexWriter对象。 indexWriter.close(); } // 搜索索引 @Test public void testSearch() throws Exception { // 第一步:创建一个Directory对象,也就是索引库存放的位置。 Directory directory = FSDirectory.open(new File("D:\temp\index"));// 磁盘 // 第二步:创建一个indexReader对象,需要指定Directory对象。 IndexReader indexReader = DirectoryReader.open(directory); // 第三步:创建一个indexsearcher对象,需要指定IndexReader对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); // 第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。 Query query = new TermQuery(new Term("fileName", "lucene")); // 第五步:执行查询。 TopDocs topDocs = indexSearcher.search(query, 10); // 第六步:返回查询结果。遍历查询结果并输出。 ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { int doc = scoreDoc.doc; Document document = indexSearcher.doc(doc); // 文件名称 String fileName = document.get("fileName"); System.out.println(fileName); // 文件内容 String fileContent = document.get("fileContent"); System.out.println(fileContent); // 文件大小 String fileSize = document.get("fileSize"); System.out.println(fileSize); // 文件路径 String filePath = document.get("filePath"); System.out.println(filePath); System.out.println("------------"); } // 第七步:关闭IndexReader对象 indexReader.close(); } // 查看标准分析器的分词效果 @Test public void testTokenStream() throws Exception { // 创建一个标准分析器对象 // Analyzer analyzer = new StandardAnalyzer(); // Analyzer analyzer = new CJKAnalyzer(); // Analyzer analyzer = new SmartChineseAnalyzer(); Analyzer analyzer = new IKAnalyzer(); // 获得tokenStream对象 // 第一个参数:域名,可以随便给一个 // 第二个参数:要分析的文本内容 // TokenStream tokenStream = analyzer.tokenStream("test", // "The Spring Framework provides a comprehensive programming and configuration model."); TokenStream tokenStream = analyzer.tokenStream("test", "高富帅可以用二维表结构来逻辑表达实现的数据"); // 添加一个引用,可以获得每个关键词 CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); // 添加一个偏移量的引用,记录了关键词的开始位置以及结束位置 OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class); // 将指针调整到列表的头部 tokenStream.reset(); // 遍历关键词列表,通过incrementToken方法判断列表是否结束 while (tokenStream.incrementToken()) { // 关键词的起始位置 System.out.println("start->" + offsetAttribute.startOffset()); // 取关键词 System.out.println(charTermAttribute); // 结束位置 System.out.println("end->" + offsetAttribute.endOffset()); } tokenStream.close(); } }
索引维护
import static org.junit.Assert.*; import java.io.File; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field.Store; import org.apache.lucene.document.TextField; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.Term; import org.apache.lucene.queryparser.classic.MultiFieldQueryParser; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.BooleanClause.Occur; import org.apache.lucene.search.BooleanQuery; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.MatchAllDocsQuery; import org.apache.lucene.search.NumericRangeQuery; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TermQuery; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; import org.junit.Test; import org.wltea.analyzer.lucene.IKAnalyzer; /** * 索引维护 * 添加 入门程序 * 删除 * 修改 * 查询 入门程序 精准查询 * @author lx * */ public class LuceneManager { // public IndexWriter getIndexWriter() throws Exception{ // 第一步:创建一个java工程,并导入jar包。 // 第二步:创建一个indexwriter对象。 Directory directory = FSDirectory.open(new File("D:\temp\index")); // Directory directory = new RAMDirectory();//保存索引到内存中 (内存索引库) Analyzer analyzer = new StandardAnalyzer();// 官方推荐 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer); return new IndexWriter(directory, config); } //全删除 @Test public void testAllDelete() throws Exception { IndexWriter indexWriter = getIndexWriter(); indexWriter.deleteAll(); indexWriter.close(); } //根据条件删除 @Test public void testDelete() throws Exception { IndexWriter indexWriter = getIndexWriter(); Query query = new TermQuery(new Term("fileName","apache")); indexWriter.deleteDocuments(query); indexWriter.close(); } //修改 @Test public void testUpdate() throws Exception { IndexWriter indexWriter = getIndexWriter(); Document doc = new Document(); doc.add(new TextField("fileN", "测试文件名",Store.YES)); doc.add(new TextField("fileC", "测试文件内容",Store.YES)); indexWriter.updateDocument(new Term("fileName","lucene"), doc, new IKAnalyzer()); indexWriter.close(); } //IndexReader IndexSearcher public IndexSearcher getIndexSearcher() throws Exception{ // 第一步:创建一个Directory对象,也就是索引库存放的位置。 Directory directory = FSDirectory.open(new File("D:\temp\index"));// 磁盘 // 第二步:创建一个indexReader对象,需要指定Directory对象。 IndexReader indexReader = DirectoryReader.open(directory); // 第三步:创建一个indexsearcher对象,需要指定IndexReader对象 return new IndexSearcher(indexReader); } //执行查询的结果 public void printResult(IndexSearcher indexSearcher,Query query)throws Exception{ // 第五步:执行查询。 TopDocs topDocs = indexSearcher.search(query, 10); // 第六步:返回查询结果。遍历查询结果并输出。 ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { int doc = scoreDoc.doc; Document document = indexSearcher.doc(doc); // 文件名称 String fileName = document.get("fileName"); System.out.println(fileName); // 文件内容 String fileContent = document.get("fileContent"); System.out.println(fileContent); // 文件大小 String fileSize = document.get("fileSize"); System.out.println(fileSize); // 文件路径 String filePath = document.get("filePath"); System.out.println(filePath); System.out.println("------------"); } } //查询所有 @Test public void testMatchAllDocsQuery() throws Exception { IndexSearcher indexSearcher = getIndexSearcher(); Query query = new MatchAllDocsQuery(); System.out.println(query); printResult(indexSearcher, query); //关闭资源 indexSearcher.getIndexReader().close(); } //根据数值范围查询 @Test public void testNumericRangeQuery() throws Exception { IndexSearcher indexSearcher = getIndexSearcher(); Query query = NumericRangeQuery.newLongRange("fileSize", 47L, 200L, false, true); System.out.println(query); printResult(indexSearcher, query); //关闭资源 indexSearcher.getIndexReader().close(); } //可以组合查询条件 @Test public void testBooleanQuery() throws Exception { IndexSearcher indexSearcher = getIndexSearcher(); BooleanQuery booleanQuery = new BooleanQuery(); Query query1 = new TermQuery(new Term("fileName","apache")); Query query2 = new TermQuery(new Term("fileName","lucene")); // select * from user where id =1 or name = 'safdsa' booleanQuery.add(query1, Occur.MUST); booleanQuery.add(query2, Occur.SHOULD); System.out.println(booleanQuery); printResult(indexSearcher, booleanQuery); //关闭资源 indexSearcher.getIndexReader().close(); } //条件解释的对象查询 @Test public void testQueryParser() throws Exception { IndexSearcher indexSearcher = getIndexSearcher(); //参数1: 默认查询的域 //参数2:采用的分析器 QueryParser queryParser = new QueryParser("fileName",new IKAnalyzer()); // *:* 域:值 Query query = queryParser.parse("fileName:lucene is apache OR fileContent:lucene is apache"); printResult(indexSearcher, query); //关闭资源 indexSearcher.getIndexReader().close(); } //条件解析的对象查询 多个默念域 @Test public void testMultiFieldQueryParser() throws Exception { IndexSearcher indexSearcher = getIndexSearcher(); String[] fields = {"fileName","fileContent"}; //参数1: 默认查询的域 //参数2:采用的分析器 MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields,new IKAnalyzer()); // *:* 域:值 Query query = queryParser.parse("lucene is apache"); printResult(indexSearcher, query); //关闭资源 indexSearcher.getIndexReader().close(); } }
单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。
基于Solr实现站内搜索扩展性较好,并且可以减少程序员的工作量,因为Solr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。
搭建solr
步骤一:创建solr文件夹,放入tomcat和solr
bin:solr的运行脚本
contrib:solr的一些贡献软件/插件,用于增强solr的功能。
dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
docs:solr的API文档
example:solr工程的例子目录:
example/solr:
该目录是一个包含了默认配置信息的Solr的Core目录。
example/multicore:
该目录包含了在Solr的multicore中设置的多个Core目录。
example/webapps:
该目录中包括一个solr.war,该war可作为solr的运行实例工程。
licenses:solr相关的一些许可信息
步骤二:拷贝,粘贴
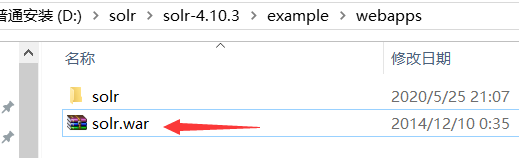
(上面不行的话换solr-4.10.3distsolr-4.10.3.war)
改名为solr.war
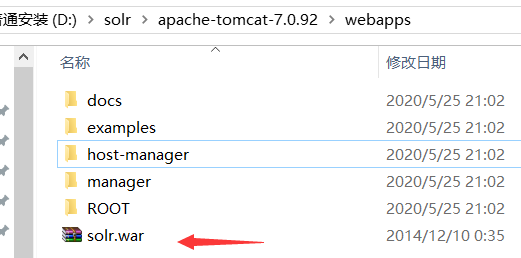
解压,删掉war包
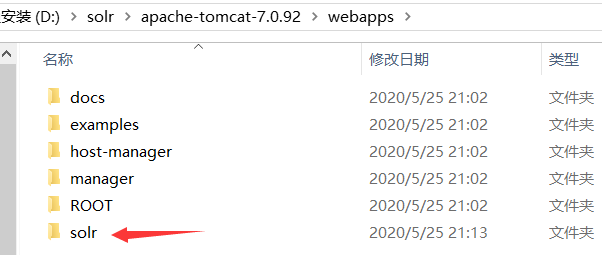
找到solr-4.10.3examplelibext下的jar包

放到D:solrapache-tomcat-7.0.92webappssolrWEB-INFlib下
步骤三
新建solrhome(放索引库)
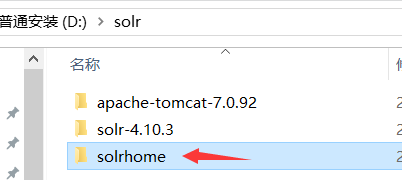
粘贴到solrhome下
接下来,修改配置
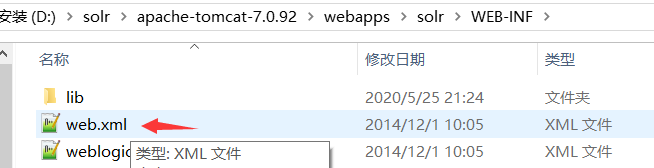
<env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>D:solrsolrhome</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry>
启动上文的tomcat
浏览器访问http://localhost:8080/solr
失败!
换了一顿官网的纯净版tomcat,重新解压了新的solr进行配置,还是不行!
浪费一个多小时,改了tomcat环境变量,成功……
安装中文分词器
①将IKAnalyzer2012FF_u1.jar拷到tomcat下的solr项目中
②在solr项目的WEB-INF文件夹中新建classes文件夹,拷入ext.dic,IKAnalyzer.cfg.xml,stopword.dic
③solr实例的conf文件夹中(D:solrsolrhomecollection1conf),修改schema.xml文件(新增)
<!-- IKAnalyzer--> <fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> <!--IKAnalyzer Field--> <field name="title_ik" type="text_ik" indexed="true" stored="true" /> <field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/>
启动tomcat
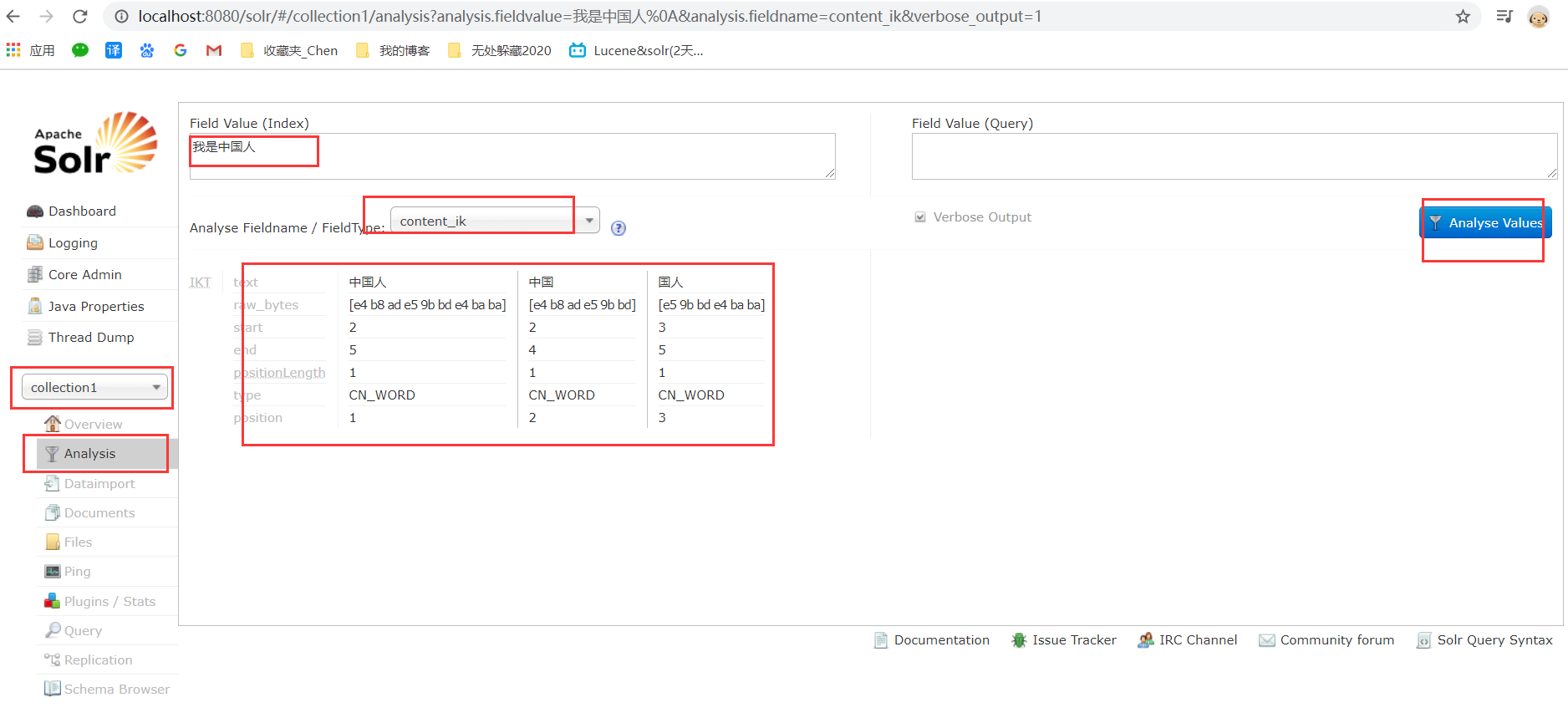
左下角就是对域/数据的维护
导数据
拷入jar包
solr-dataimporthandler-4.10.3.jar
solr-dataimporthandler-extras-4.10.3.jar
mysql-connector-java-5.1.7-bin.jar
拷贝到D:solrsolrhomecollection1lib
修改配置D:solrsolrhomecollection1confsolrconfig.xml
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xml</str> </lst> </requestHandler>
同级目录下创建data-config.xml,粘入如下内容
<?xml version="1.0" encoding="UTF-8" ?> <dataConfig> <dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/lucene" user="root" password="root"/> <document> <entity name="product" query="SELECT pid,name,catalog_name,price,description,picture FROM products "> <field column="pid" name="id"/> <field column="name" name="product_name"/> <field column="catalog_name" name="product_catalog_name"/> <field column="price" name="product_price"/> <field column="description" name="product_description"/> <field column="picture" name="product_picture"/> </entity> </document> </dataConfig>
创建lucene数据库,导入数据
下一步,将这些数据导入到索引库当中
修改D:solrsolrhomecollection1confschema.xml
<!--product--> <field name="product_name" type="text_ik" indexed="true" stored="true"/> <field name="product_price" type="float" indexed="true" stored="true"/> <field name="product_description" type="text_ik" indexed="true" stored="false" /> <field name="product_picture" type="string" indexed="false" stored="true" /> <field name="product_catalog_name" type="string" indexed="true" stored="true" /> <field name="product_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/> <copyField source="product_name" dest="product_keywords"/> <copyField source="product_description" dest="product_keywords"/>
重启服务

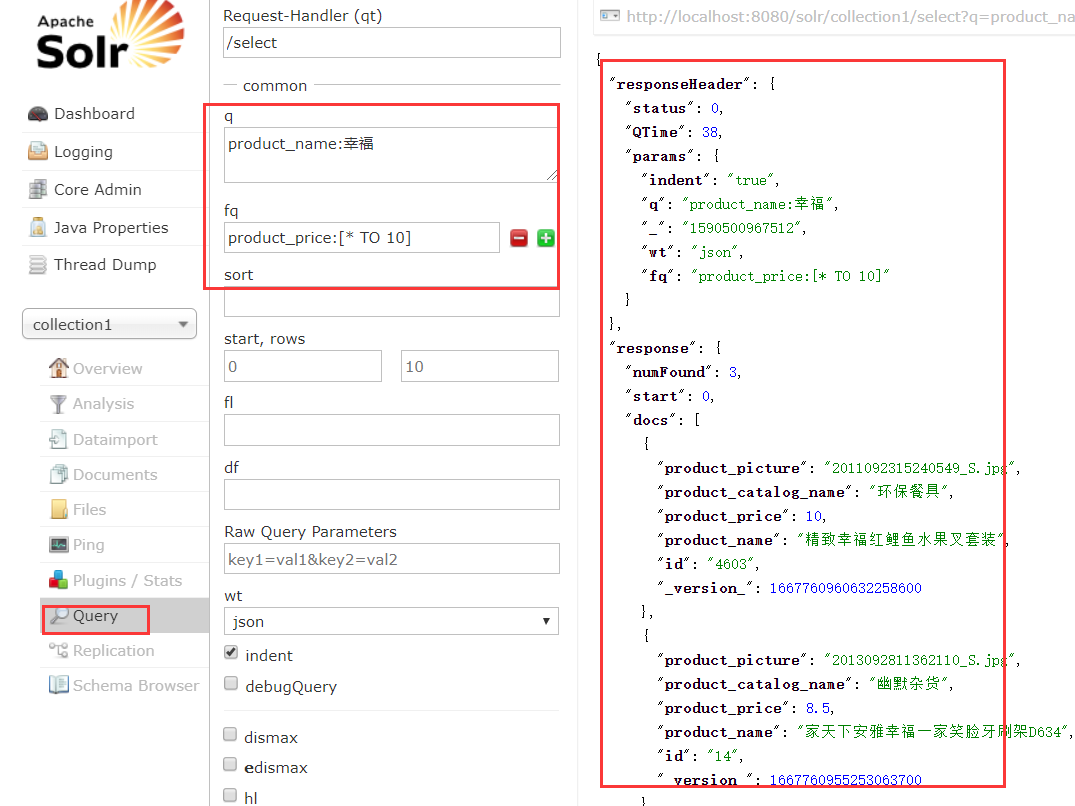
筛选
使用SolrJ管理索引
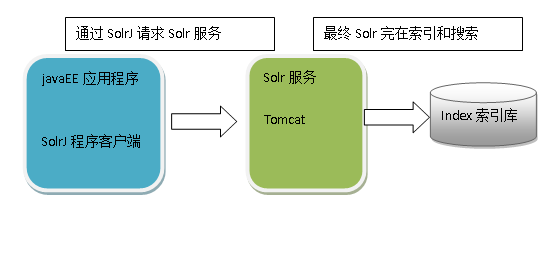
代码
//向索引库中添加索引 @Test public void addDocument() throws Exception { //和solr服务器创建连接 //参数:solr服务器的地址 SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr"); //创建一个文档对象 SolrInputDocument document = new SolrInputDocument(); //向文档中添加域 //第一个参数:域的名称,域的名称必须是在schema.xml中定义的 //第二个参数:域的值 document.addField("id", "c0001"); document.addField("title_ik", "使用solrJ添加的文档"); document.addField("content_ik", "文档的内容"); document.addField("product_name", "商品名称"); //把document对象添加到索引库中 solrServer.add(document); //提交修改 solrServer.commit(); }
根据id删除
//删除文档,根据id删除 @Test public void deleteDocumentByid() throws Exception { //创建连接 SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr"); //根据id删除文档 solrServer.deleteById("c0001"); //提交修改 solrServer.commit(); }
根据查询删除
//根据查询条件删除文档 @Test public void deleteDocumentByQuery() throws Exception { //创建连接 SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr"); //根据查询条件删除文档 solrServer.deleteByQuery("*:*"); //提交修改 solrServer.commit(); }
查询
//查询索引 @Test public void queryIndex() throws Exception { //创建连接 SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr"); //创建一个query对象 SolrQuery query = new SolrQuery(); //设置查询条件 query.setQuery("*:*"); //执行查询 QueryResponse queryResponse = solrServer.query(query); //取查询结果 SolrDocumentList solrDocumentList = queryResponse.getResults(); //共查询到商品数量 System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound()); //遍历查询的结果 for (SolrDocument solrDocument : solrDocumentList) { System.out.println(solrDocument.get("id")); System.out.println(solrDocument.get("product_name")); System.out.println(solrDocument.get("product_price")); System.out.println(solrDocument.get("product_catalog_name")); System.out.println(solrDocument.get("product_picture")); } }
复杂查询
//复杂查询索引 @Test public void queryIndex2() throws Exception { //创建连接 SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr"); //创建一个query对象 SolrQuery query = new SolrQuery(); //设置查询条件 query.setQuery("钻石"); //过滤条件 query.setFilterQueries("product_catalog_name:幽默杂货"); //排序条件 query.setSort("product_price", ORDER.asc); //分页处理 query.setStart(0); query.setRows(10); //结果中域的列表 query.setFields("id","product_name","product_price","product_catalog_name","product_picture"); //设置默认搜索域 query.set("df", "product_keywords"); //高亮显示 query.setHighlight(true); //高亮显示的域 query.addHighlightField("product_name"); //高亮显示的前缀 query.setHighlightSimplePre("<em>"); //高亮显示的后缀 query.setHighlightSimplePost("</em>"); //执行查询 QueryResponse queryResponse = solrServer.query(query); //取查询结果 SolrDocumentList solrDocumentList = queryResponse.getResults(); //共查询到商品数量 System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound()); //遍历查询的结果 for (SolrDocument solrDocument : solrDocumentList) { System.out.println(solrDocument.get("id")); //取高亮显示 String productName = ""; Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting(); List<String> list = highlighting.get(solrDocument.get("id")).get("product_name"); //判断是否有高亮内容 if (null != list) { productName = list.get(0); } else { productName = (String) solrDocument.get("product_name"); } System.out.println(productName); System.out.println(solrDocument.get("product_price")); System.out.println(solrDocument.get("product_catalog_name")); System.out.println(solrDocument.get("product_picture")); } }
案例实现