第三单元啦!!!
PART 1 JML理论基础梳理
JML = JAVA + Math of discrete + Language
(别信我,我瞎凑的
对于最后一个单词,language,很好理解,不论是什么理论都要有一种语言将其描述出来供人使用。JAVA,一种编程语言;离散数学,一种数学(逻辑)语言。所以language就不多说了,接下来主要讨论JAVA和Math of discrete这两个词。
JAVA
既然是针对JAVA语言而使用的模型语言,那么JML必然与JAVA的思想有着千丝万缕的联系。
面向对象最重要的是什么!!——层次化!!
没错,JML也深得层次化的精髓。JML主要可以分为两个层次:类型规格——针对整个类的规约;方法规格——对于一个类中的各个方法的规约。
-
类型规格
- 数据类型规格
该规格是描述这个类中使用的所有数据的结构类型(仅针对JML,不规定实现时的数据结构),方便于之后书写JML时统一使用各个数据。
- 不变式约束(invariant)
不变式所表达的是要求在所有可见状态下都满足的特性,即一般来讲该类不执行方法时所有数据应满足的条件(不准确,但是绝大部分情况适用)。
- 状态变化约束(constraint)
该规格描述了可变对象在一次状态变化前后的新旧状态之间关系的约束,即一般来讲调用一次方法改变某个对象的状态后,新旧对象的状态差别的约束。
以上三个为类型规格级别的规格,其所规定和约束的需要该类中所有的方法都要满足。这三种约束是高级约束,是在方法规格的层次的更抽象一级层次。
-
方法规格
- normal_behavior
- 前置条件(requires):行为执行的前提条件,不满足则不做动作
- 后置条件(ensures):行为执行的结果。用 esult表示结果。
- 副作用(assignable):行为执行期间对对象状态的改变。(可以改变哪些对象的状态)
- exceptional_behavior
- 前置条件(requires):通常与正常行为的前置条件互补
- 后置条件(ensures):通常没有(也许只是我还没见到过吧,捂脸/.jpg)
- signals子句:最常用,通过signals子句来抛出异常。
以上语句均为对一个方法内部的各类行为进行规定约束,各个方法之间不互相影响。不过,在执行这些行为时,除了要满足方法规格,仍然需要始终保持类型规格的要求。当然了,方法规格更不能与类型规格发生冲突!
- normal_behavior
以上两个不同抽象等级的规格类型,很好地体现了JAVA层次化设计的思想,不愧名字中带有JAVA!(emmm,其实就是专门为JAVA诞生的
那有了这些规格,怎么写呢,拿什么语言呢?(肯定不会是JAVA,hhh)请看下面~
Math of discrete
好吧,我承认确实是为了凑出M这个字母,把好好的Discrete Math硬生生地给反过来写了。
没错,即使反着写你也能知道,就是离散数学!(主要离散一
书写JML使用的是JAVA格式的逻辑语言。
下面列出一张JML与离散数学的逻辑语言符号的对照表:
| JML | Discrete Math | |
|---|---|---|
| 全称量词 | forall | (forall) |
| 存在量词 | exists | (exists) |
| 充分 | ==> | ( ightarrow) |
| 必要 | <== | (leftarrow) |
| 充要 | <==> | (leftrightarrow) |
其余没提到的,基本与离散数学的符号一样。除此之外,JML还有很多方便的符号:
| 含义 | JML |
|---|---|
| 对给定范围内满足条件的表达式和 | sum |
| 对给定范围内满足条件的表达式的积 | product |
| 对给定范围内表达式求最大(最小) | max(min) |
| 求给定范围内满足条件的个数 | um_of |
有了以上这些,我们就可以轻松的书写JML规格了!
到此为止,JML的理论基础也就基本梳理完成了。
PART 2 openJML相关
openjml,帮助你检查JML语法格式的好用(才怪)的工具。可以执行静态检查和动态检查两种模式。动态检查听起来是一个极其棒的功能,因为它可以帮你检查代码与JML是否相符,也就相当于帮你验证你的实现是否正确。这对于不愿意构造测试用例检测的程序员简直就是福音啊!不过,现实总是很残酷(现实也是这么对我的,一般来说,你的代码静态检查都过不了,更不要想动态检查了。
使用方式倒也不是很复杂,去官网下载一个openjml包,网址:http://www.openjml.org/downloads/ ,里面就只有一个绿框,点就完事了。
下载好后,解压到一个文件夹(随意),将你要检测的JAVA文件拖进解压到的文件夹,运行cmd,进入解压的文件夹内,执行一个命令行命令:
java -jar .openjml.jar -exec #解释器绝对路径#(输入时不要有#) -esc #要检测的JAVA文件的绝对路径#(如果为文件夹或包,记得前面加 -dir)
之后就可以看到结果了。我本地运行的结果如下图:
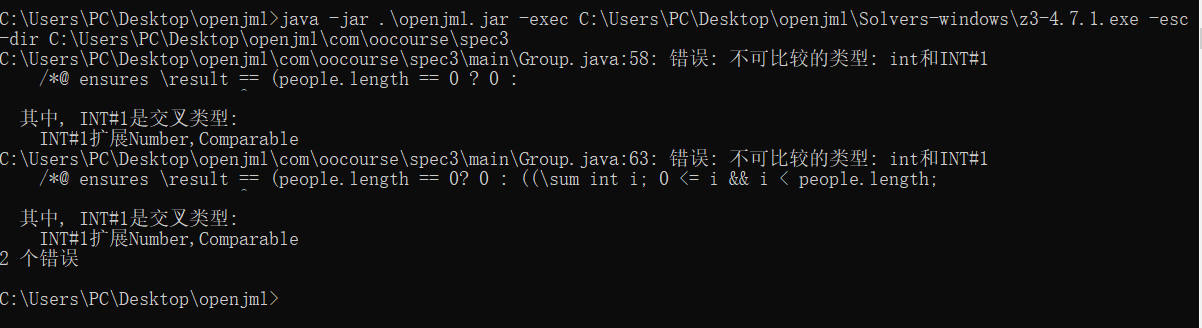
什么?三目运算符还不让用??INT#1又是神马类型???
看,静态检查就已经让你摸不着头脑了。为了通过静态检查,我尝试改掉三目运算符:
将Group类中的上图报错的两处修改为:
/*@ public normal_behavior
@ requires people.length == 0;
@ ensures
esult == 0;
@ also
@ public normal_behavior
@ requires people.length > 0;
@ ensures
esult == ((sum int i; 0 <= i && i < people.length; people[i].getAge()) / people.length);
@*/
public int getAgeMean();
/*@ public normal_behavior
@ requires people.length == 0;
@ ensures
esult == 0;
@ also
@ public normal_behavior
@ requires people.length > 0;
@ ensures
esult == ((sum int i; 0 <= i && i < people.length;
@ (people[i].getAge() - getAgeMean()) * (people[i].getAge() - getAgeMean())) /
@ people.length);
@*/
public int getAgeVar();
上述修改导致了pure方法变为非pure方法,因此调用过程还需修改,不过在这些修改后,运行openjml后,之前的错误没有了(心中暗自开心),但是仍会报一些奇奇怪怪的错(心里一沉):
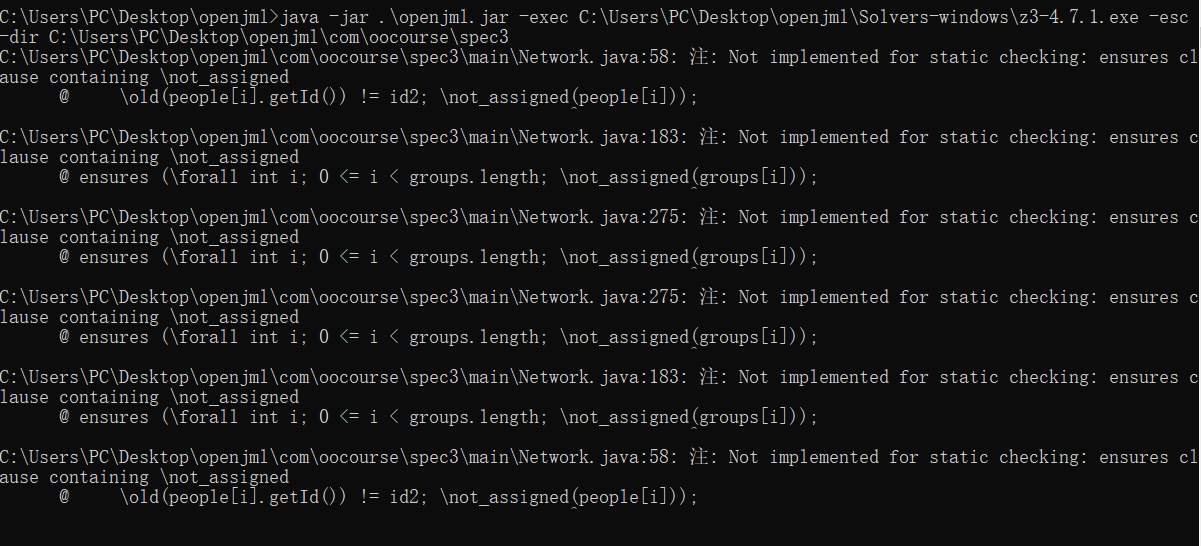
以上错误可能是由于书写不规范,不过由于错误过多,无力全部改正,因此暂且将该部分略过。
openjml的使用,本人目前掌握了安装、基本使用等知识,对于具体代码的检测,目前还未对复杂完整(作业代码)成功检查,没有报错过。
不过单独对作业代码的Person类接口进行检查,是没有问题的(唯一一个能不改就通过检查的代码)
PART 3 JMLUnitNG相关
这也是帮助检查代码正确性的一个工具。
用法同样不很复杂,只是需要不断尝试和修改代码,着实有点麻烦。
首先,可以在该网站下载JMLUnitNG的jar包:http://insttech.secretninjaformalmethods.org/software/jmlunitng/
下载好后,放到任意一个文件夹(我把它和openjml放一起了),将要测试的代码文件也一并放入(记得要连package一起放进去)。之后,我开始了不断的修改,直至语法通过了JMLUnitNG的编译。
以下为需要使用的命令行命令:

当最后一行命令输入后,会在命令框中输出测试结果,我的测试结果如下:
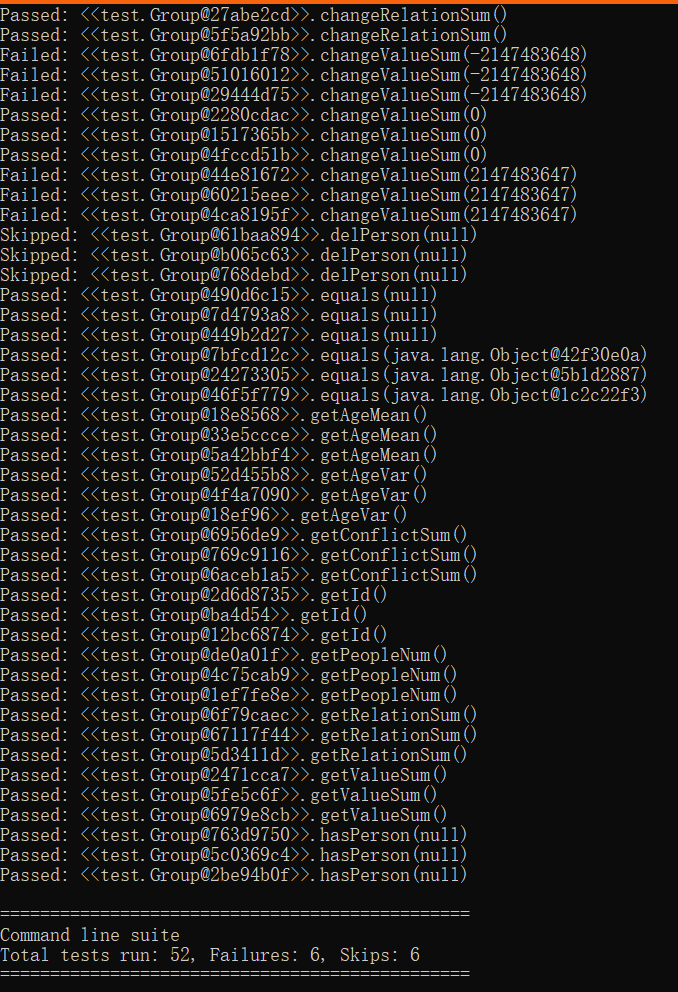
通过上图的测试用例的使用,我们不难发现,JMLUnitNG给我们创造的用例全部都是极端的边界情况,比如int的最大最小值、对象为null等。以上测试没有通过的6个点,是value的int最大值最小值,错误是正常的,因为我们的作业没有对溢出进行处理,所以会导致错误。其他方法都没有错误,很大程度证明了我们的程序在边界极端值的情况下的正确性。
不过,对于一般情况,和非边界值的极端情况,就需要我们自己手动构造测试样例了。
PART 4 架构设计
第一次作业
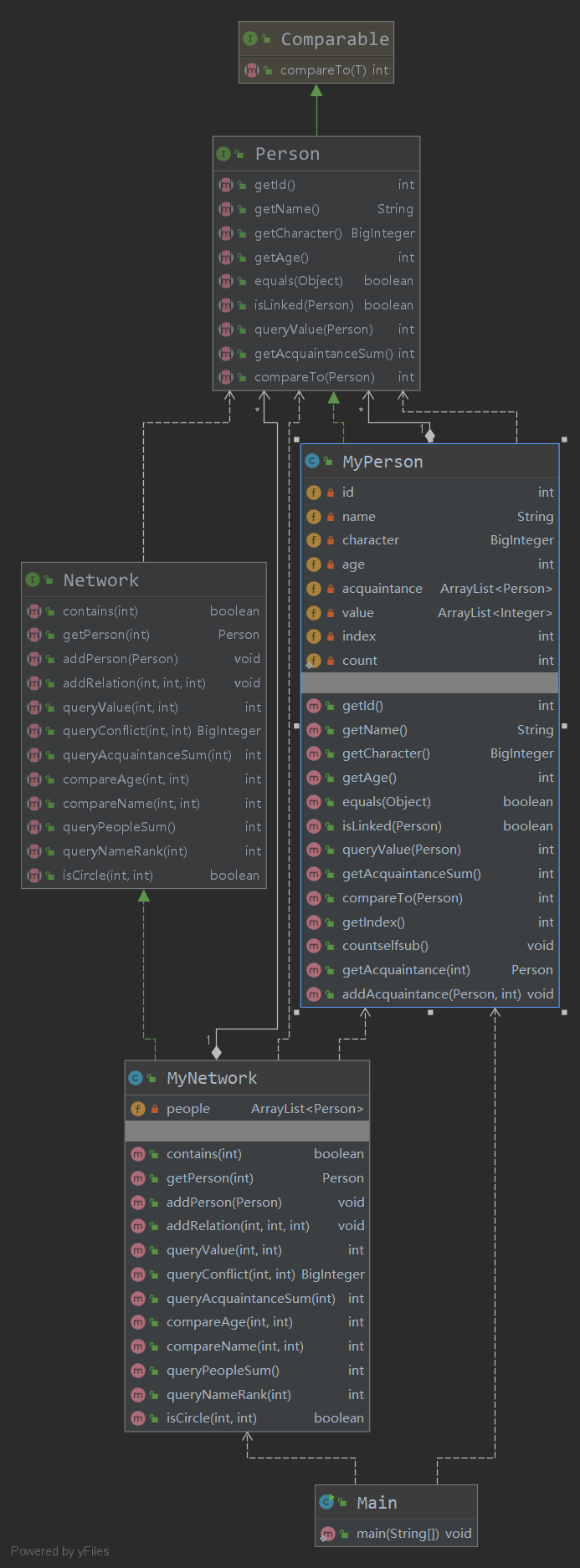
上图为第一次作业的UML图,可见结构清晰(课程组给的架构怎么能不清晰!夸!!
由于第一次作业方法并不复杂,仅有isCircle方法需要一些复杂操作,因此我除了接口给定要求实现的方法外,仅针对isCircle方法实现过程中需要的数据结构进行了增加和设计。
我为了isCircle方法增加的额外设计和方法如下:
为了方便顺序遍历所有人员,我给每个person添加了一个属性:index。这个index从0开始递增,最大为添加的人数 - 1。这样,我在使用visited数组时,就方便了很多,可以将人员和下标一一对应起来,同时也最大程度上的节省了空间(使用people.size大小的visited数组就够用了)
第二次作业
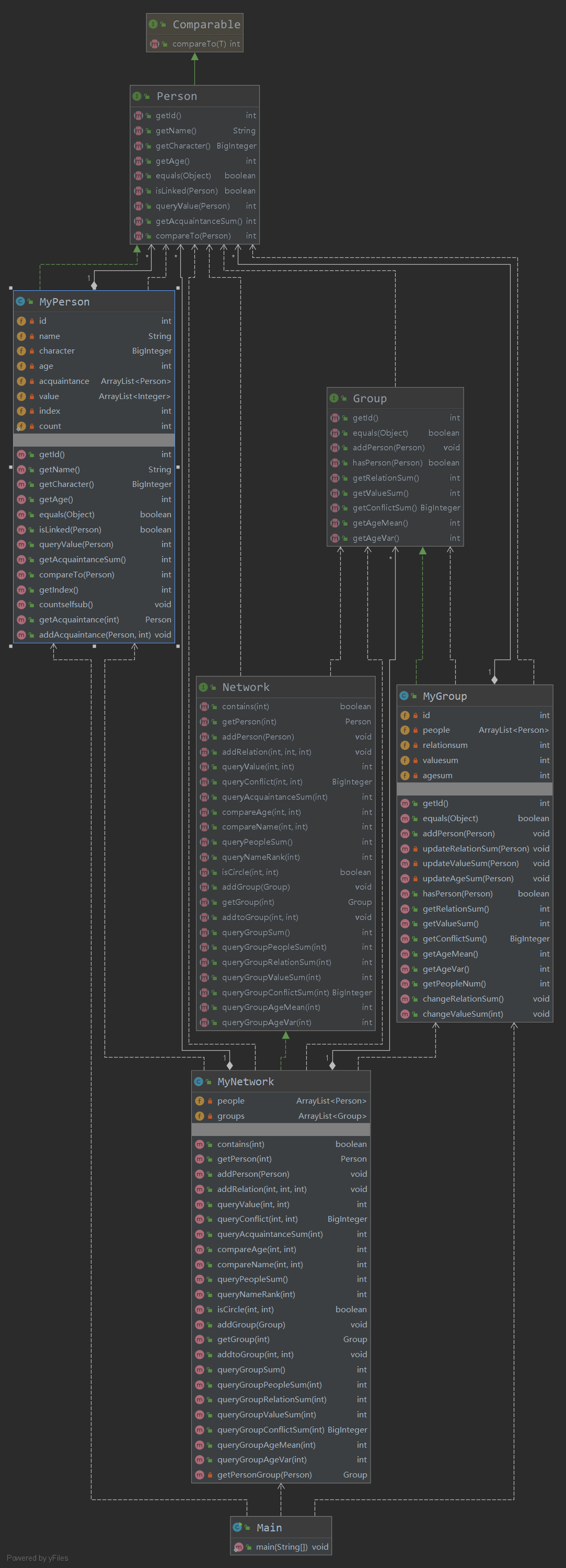
第二次作业较第一次新增了group类,即整个人际网络(Network类)的子集,包含部分person。
由于第二次作业要求的指令条数上限达到10w条,因此时间复杂度就必须要划入考虑范围内了。不仅要正确地完成方法的功能,还要在较短的时间内完成。
本次作业时间复杂度较高的几个方法:
group类中的getRelationSum、getValueSum、getAgeSum等,复杂度最高可达人数平方。因此对于这几个方法,采用一贯的套路——空间换时间。具体来说就是,使用冗余存储(见上图MyGroup类中的后三个数据),存储下group类中的relationsum、valuesum和agesum这三个值,在向group中添加新人时更新这三个值(见上图中的三个update方法(private))。同时,在Network中进行addRelation操作时,不要忘了改变relationsum和valuesum的值!
Network类中的queryNameRank、isCircle方法是复杂度较高的,达到总人数的级别。对于queryNameRank方法,说多了都是泪,在之后的bug环节再具体讨伐自己吧。
第三次作业
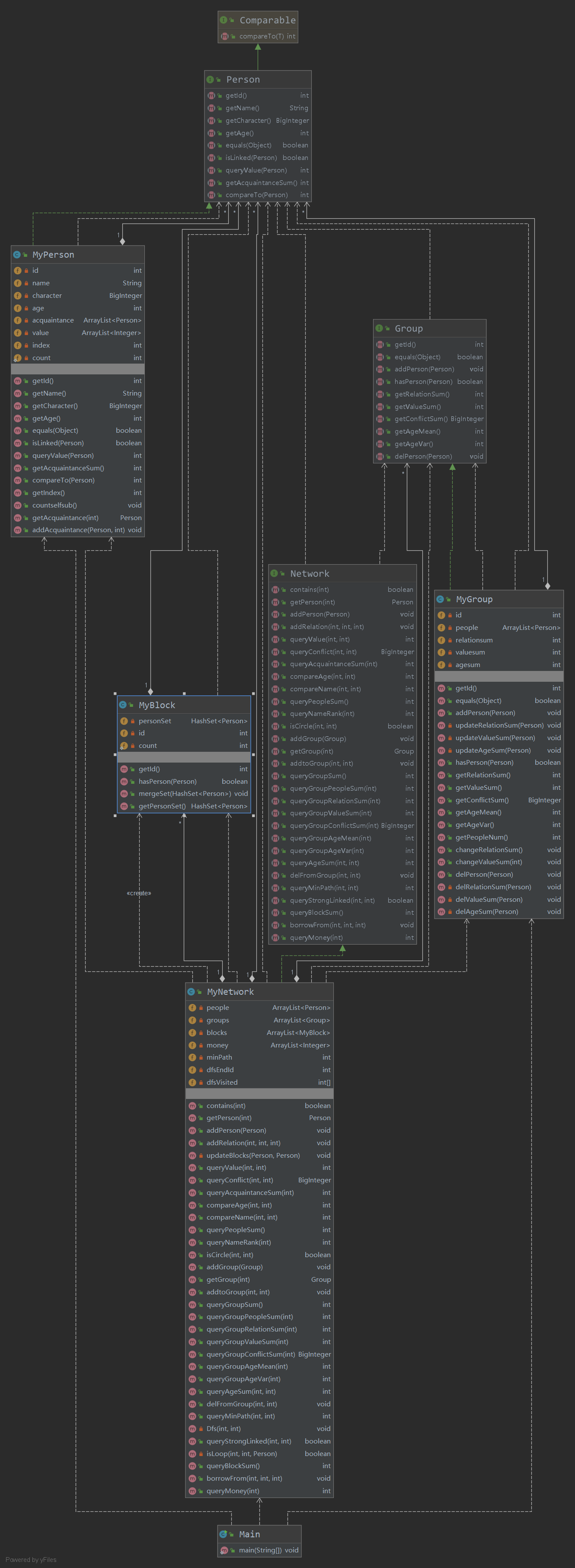
第三次作业,我突破了!我不仅仅有要求实现接口的类,还自己多创建了一个MyBlock类来实现queryBlockSum的O(1)实现。其实,本质思想就是并查集,只不过我一直坚持到了第三次作业才用(我靠BFS活过了10w条指令,hhh
MyBlock类里面有存有人员的HashSet,还有自己的id。方法有mergeSet用于两个Block的融合。
使用方法也很简单,在addperson时,为每一个人新建一个MyBlock类实例,里面只存新加的人,然后将实例加入blocks数组。addrelation时,判断两个人是否在同一个Block里,若是则啥也不干;否则,将两个Block融合,删除其中一个。这样操作之后,queryBlockSum操作只需要返回blocks数组的长度即可。
对于Network类中新加的blocks数组,我在课上讨论的时候正好为它写了一份JML规格以保证正确性(其实强测已经帮我通过数据验证过了hhh)。具体代码见下:
invariant
(forall int i; 0 <= i && i < blocks.length;
(forall int j; 0 <= j && j < blocks[i].people.length;
(forall int k; 0 <= k && k < j; isCircle(blocks[i].people[j], blocks[i].people[k])) &&
(forall Person p; p<>null; isCircle(p, blocks[i].people[j])==>(exists int q;
0 <= q && q < blocks[i].people.length; blocks[i].people[q].equals(p)))))
其实,上述JML代码也就是描述了极大连通子图的约束。第四行描述了连通,最后两行描述了极大。
以上代码感谢吴际老师的修改(我之前写的好麻烦,捂脸/.jpg)
PART 5 Buuuuug!
有一位名人曾说过:“中测温水煮青蛙,强测开水烫死猪”
(别问我是哪个名人
第三单元的作业,看起来简单,写起来简单,想拿高分却不容易。
总结起来我的问题:自己新增的设计考虑不周,按着JML写的方法又过于死板。
前者导致WA或是RE,后者导致CTLE。
第一次作业
"你在强测中得到0分"
当互测环节没有我的时候,我就预感到大事不妙。不过强测公布之前,我一直在好奇哪个部分让我死得这么惨(尤其是群中的普遍错误——isLinked我还没有写错)。
当强测数据公布后,满屏的RE,20个点都是RE。好奇的我点开一个数据看了一看,wow,数组越界。这个RE已经多久没出现过了,我很难受也很好奇,开始了漫长的debug之旅。经过15分钟的漫长debug之旅后,我发现了自己有多傻!没错,就是自己增加的设计——人员的index出了问题。我没有考虑addperson方法的异常情况,也就是说可能会有相同id的person加入,但是此时people数组并不会增加,而由于新建了person的实例,所以index会增长。这样,在访问visited数组时,就会出现数组越界(我也是为了追求空间性能,只开了与people数组大小相同的visited数组,要是开大点也就没问题了)。
针对这个bug,修改方式也很简单。我在person类中加入一个countselfsub方法,给计数器count进行自减操作。在addperson类中出现异常时,调用自减方法,可以保证visited下标与index一一对应,不会越界。
第一次作业的bug就是自己增加的设计考虑不周导致的。
第二次作业
我进互测了,我感觉事情的走向好了起来,直到……
直到强测公布,我的分数也不是很理想。这次所有的问题都是CTLE。
我知道第二次作业指令数多,可是我也用了缓存机制啊,理论上应该那些复杂度大的方法不会超时啊。
检查了一遍后发现,我太单纯了,我怎么能只按照JML规格给的方法写呢!(会超时的!
导致我CTLE的方法就是一个——queryNameRank,当时写作业的时候,我分析这就是个O(n)的方法,可是实现之后事情变得不是这么简单了起来。我先使用一层for循环遍历所有人,每一层循环内使用一个compareName。我当时一看compareName就是getPerson一下,然后比较,没啥问题,像是O(1)的方法,可谁知事实并非如此。getPerson是我第一次作业写的,可能第二次作业忘了它的实现,其实getPerson方法也是要遍历数组才能得到结果的。那么,综合起来,queryNameRank就是一个O((n^2))的方法了,这就导致了我的CTLE。
针对这个bug,修改方式也很简单,将compareName方法改为Person类自己的compareTo方法,这样就是一个O(1) 的实现了。
第二次作业的bug就是我直接照着JML规格里给的方法直接写,没有仔细考虑其中使用的方法的复杂度导致的CTLE。
第三次作业
还是进了互测,这个在预料之中,我针对第三次作业易错的几个算法复杂的方法进行了针对性的大量测试,如queryMinPath、queryStrongLink等。
强测分数也还可以,有一点CTLE的问题,经我计算应该是qeuryMinPath复杂度卡的不好,导致了CTLE。
在互测中,我将自己本地测试的用例提交后,得到了较好的hack成功率。几乎每组都能hack到至少一个人。
我构造用例的方法是,将我自己写复杂算法的过程中用来否定自己算法的用例保存下来。比如:queryStrongLink方法中,X型关系,纺锤形关系等,都是容易出现误判的情况。用这些用例,确实可以hack到一些考虑不周的同学的代码。
PART 6 感悟与总结
JML说他好,也真是挺好使;说他不好,也真是挺难用。
具体这两方面怎么说呢?
好,确实好。它将JAVA代码的方法,高度抽象地提取出来,使这个方法的功能和具体实现分离开来。这样做的一个巨大好处就是,我可以肉眼验证正确性了!也就是,对于一个方法,只需要看调用该方法的方法传入的数据是否ok,再看看使用该方法的处理,是否与该方法的 esult符合,正确性的验证就OK了。较之前看实现代码,大脑模拟一个个if的方法要方便太多了,而且稳定性也有了很大提升。也就是说,“用上JML,正确有保障”!
不好,确实费劲。这个费劲指相关工具链。真的难用!!!(大声喊出)这个工具链,从一开始还没用上就用户不友好。下载渠道不统一,好不容易下下来了,配置环境jdk11还不行,下载个jdk8后,安装好了,跑起来检查报出无数错误(说多了都是泪啊),改来改去,最后还是神秘错误,遂放弃。真的,多想有一套完整成熟好用(输出多丑都行)的JML工具链啊。有了之后,以后JAVA代码我必先写JML(手动狗头)
不过,话说回来,既然课程中包含这部分,那这部分必然是有很大用处的。确实,在作业中体会了JML的强大之处,其好处也必然是能盖过工具链的尴尬。
写在最后,还是那句话:
"用上JML,正确有保障"