1、ps命令 (Processes Status)
ps这个命令是查看系统进程,ps 是显示瞬间行程的状态,并不动态连续。
==============ps 的参数说明============================
-A 列出所有的行程
-w 显示加宽可以显示较多的资讯
-au 显示较详细的资讯
-aux 显示所有包含其他使用者的行程
-e 显示所有进程,环境变量
-f 全格式
-h 不显示标题
-l 长格式
-w 宽输出
a 显示终端上地所有进程,包括其他用户地进程
r 只显示正在运行地进程
x 显示没有控制终端地进程
=====================================================
我们常用的是 ps -aux,该命令可以查看详细的进程,包括这些进程的PID,父进程PPID,进程启动时间STIME,进程共占用的CPU时间 TIME。 但是由于ps -aux列举的是所有进程,有时候我们只需要查看我们所关心的进程的参数,比如nginx,mysql,php等的状况,这个时候应该精确查找,可以使用以下命令:
ps -aux | grep nginx , ps -aux | grep mysql , ps -aux | grep php 等,找到了进程还要知道该进程的状态
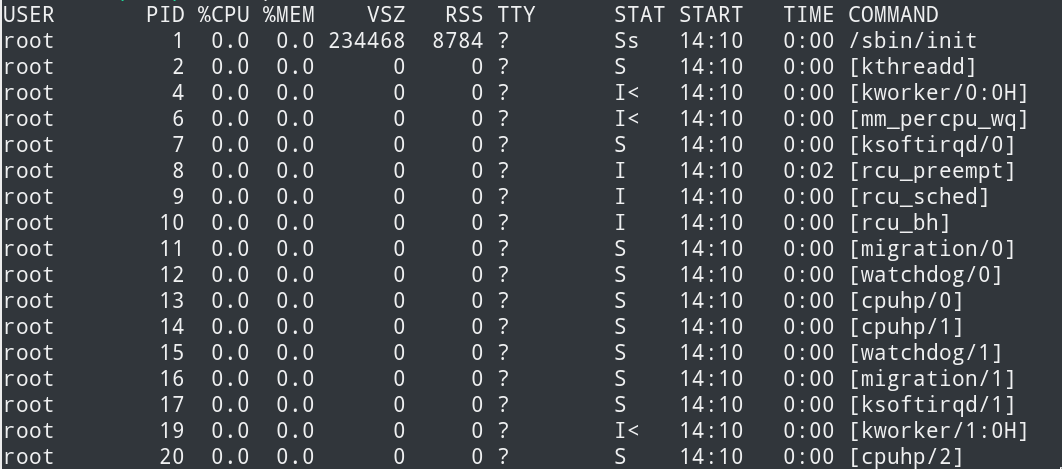
比如下图,会看到很多Ss ,S+ ,sl 等状态,这个状态是进程的STAT状态
S 是指该进程是睡眠状态,l 指多线程组,N 指低优先级任务, < 指高优先级进程, Z 指僵尸进程, X 指死掉的进程, R表示正在运行或即将执行,即在运行队列中
2、top命令
top[参数] 显示当前系统正在执行的进程的相关信息,包括进程ID、内存占用率、CPU占用率等,跟ps相比,top命令实时更新
==============top 的参数说明============================
-b 批处理
-c 显示完整的治命令
-I 忽略失效过程
-s 保密模式
-S 累积模式
-i<时间> 设置间隔时间
-u<用户名> 指定用户名
-p<进程号> 指定进程
-n<次数> 循环显示的次数
=====================================================
top命令输出可如下所示:
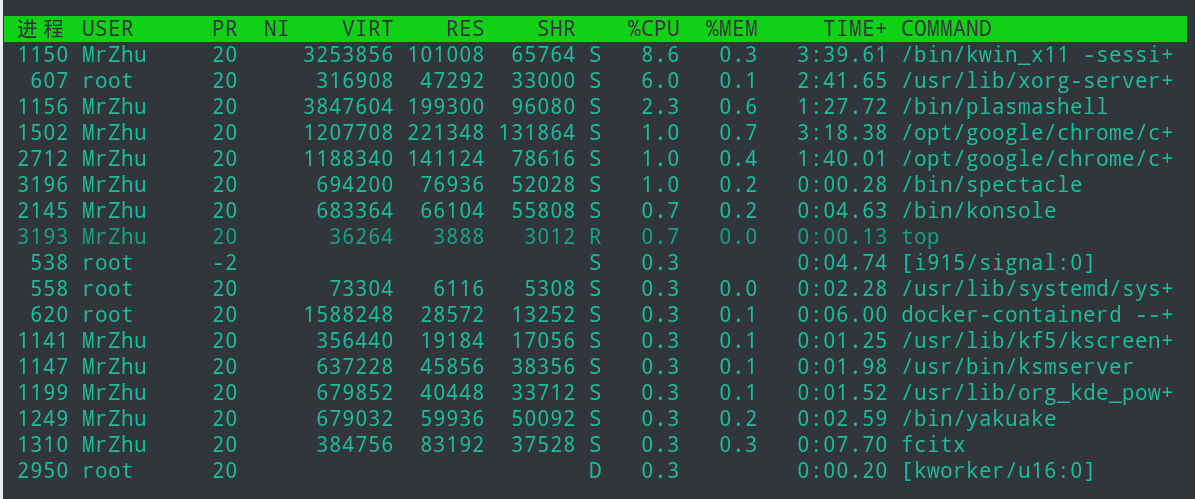
NI — nice值。负值表示高优先级,正值表示低优先级;
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES;
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA;
SHR — 共享内存大小,单位kb;
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程;
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
top交互命令:
在top 命令执行过程中可以使用的一些交互命令。这些命令都是单字母的,如果在命令行中使用了s 选项, 其中一些命令可能会被屏蔽。下面列出介个主要的:
k 终止一个进程。
r 重新安排一个进程的优先级别
S 切换到累计模式
s 改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s
l 切换显示平均负载和启动时间信息
m 切换显示内存信息
t 切换显示进程和CPU状态信息
c 切换显示命令名称和完整命令行
M 根据驻留内存大小进行排序
P 根据CPU使用百分比大小进行排序
T 根据时间/累计时间进行排序
3、vmstat 虚拟内存的实时监控工具
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况, IO读写情况。
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b 交换 空闲 缓冲 缓存 si so bi bo in cs us sy id wa st
0 0 0 30118660 100388 1170028 0 0 19 8 103 428 2 1 96 0 0
1 0 0 30118660 100388 1170028 0 0 0 0 379 1305 1 1 99 0 0
1 0 0 30118660 100396 1170028 0 0 0 22 343 1177 0 1 99 0 0
2 0 0 30118660 100396 1170028 0 0 0 0 349 1181 1 1 99 0 0
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi 每秒从块设备接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo 每秒向块设备发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
4、mpstat CPU的实时监控工具
mpstat报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。mpstat最大的特点是:可以查看多核心cpu中每个计算核心的统计数据;而类似工具vmstat只能查看系统整体cpu情况。mpstat [-P {|ALL}] [internal [count]]
参数 解释
-P {|ALL} 表示监控哪个CPU, cpu在[0,cpu个数-1]中取值
internal 相邻的两次采样的间隔时间、
count 采样的次数,count只能和delay一起使用
当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。从第二行开始,输出为前一个interval时间段的平均信息。
5、iostat 设备IO负载的实时监控工具
iostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况。同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。
==============iostat 的参数说明============================
-C 显示CPU使用情况
-d 显示磁盘使用情况
-k 以 KB 为单位显示
-m 以 M 为单位显示
-N 显示磁盘阵列(LVM) 信息
-n 显示NFS 使用情况
-p[磁盘] 显示磁盘和分区的情况
-t 显示终端和CPU的信息
-x 显示详细信息
-V 显示版本信息
=====================================================
查看磁盘使用状态 : iostat -d -k 2
参数 -d 表示,显示设备(磁盘)使用状态;-k 某些使用block为单位的列强制使用Kilobytes为单位; 2 表示,数据显示每隔2秒刷新一次。
iostat -d -k 2
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 3.93 14.26 53.73 107912 406740
sdb 4.14 106.02 4775.37 802503 36146511
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.00 0.00 0.00 0 0
sdb 0.00 0.00 0.00 0 0
6、free 查看当前系统内存的使用情况
| 选项 | 说明 |
| -b | 以字节为单位显示数据。 |
| -k | 以千字节(KB)为单位显示数据(缺省值)。 |
| -m | 以兆(MB)为单位显示数据。 |
| -s delay | 该选项将使free持续不断的刷新,每次刷新之间的间隔为delay指定的秒数,如果含有小数点,将精确到毫秒,如0.5为500毫秒,1为一秒。 |
7、df 报告磁盘的使用情况
df -h
文件系统 容量 已用 可用 已用% 挂载点
dev 16G 0 16G 0% /dev
run 16G 1.3M 16G 1% /run
/dev/sdb2 83G 32G 47G 41% /
tmpfs 16G 27M 16G 1% /dev/shm
tmpfs 16G 0 16G 0% /sys/fs/cgroup
tmpfs 16G 12K 16G 1% /tmp
/dev/sdb1 300M 264K 300M 1% /boot/efi
/dev/sda1 916G 12G 858G 2% /home
tmpfs 3.2G 8.0K 3.2G 1% /run/user/1000
8、du 评估磁盘的使用状况
| 选项 | 说明 |
| -a | 包括了所有的文件,而不只是目录。 |
| -b | 以字节为计算单位。 |
| -k | 以千字节(KB)为计算单位。 |
| -m | 以兆字节(MB)为计算单位。 |
| -h | 是输出的信息更易于阅读。 |
| -s | 只显示工作目录所占总空间。 |
| --exclude=PATTERN | 排除掉符合样式的文件,Pattern就是普通的Shell样式,?表示任何一个字符,*表示任意多个字符。 |
| --max-depth=N | 从当前目录算起,目录深度大于N的子目录将不被计算,该选项不能和s选项同时存在。 |
9、系统运行状态统计工具 sar
sar命令可以从文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等方面进行报告。
==============sar 的参数说明============================
-A:所有报告的总和
-u:输出CPU使用情况的统计信息
-v:输出inode、文件和其他内核表的统计信息
-d:输出每一个块设备的活动信息
-r:输出内存和交换空间的统计信息
-b:显示I/O和传送速率的统计信息
-a:文件读写情况
-c:输出进程统计信息,每秒创建的进程数
-R:输出内存页面的统计信息
-y:终端设备活动情况
-w:输出系统交换活动信息
=====================================================
(1) CPU资源监控
sar -u 2 5 //每2s采样一次,连续采5次
16时57分59秒 CPU %user %nice %system %iowait %steal %idle
16时58分01秒 all 0.63 0.00 0.38 0.00 0.00 98.99
16时58分03秒 all 0.63 0.00 1.01 0.06 0.00 98.30
16时58分05秒 all 0.69 0.00 0.44 0.00 0.00 98.87
16时58分07秒 all 0.69 0.00 0.56 0.00 0.00 98.74
16时58分09秒 all 0.88 0.00 0.38 0.00 0.00 98.74
平均时间: all 0.70 0.00 0.55 0.01 0.00 98.73
输出项说明:
CPU:all表示统计信息为所有 CPU的平均值。
%user:显示在用户级别(application)运行使用 CPU 总时间的百分比。
%nice:显示在用户级别,用于nice操作,所占用 CPU总时间的百分比。
%system:在核心级别(kernel)运行所使用 CPU总时间的百分比。
%iowait:显示用于等待I/O操作占用 CPU总时间的百分比。
%steal:管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比。
%idle:显示 CPU空闲时间占用 CPU总时间的百分比。
P.S:
1.若 %iowait的值过高,表示硬盘存在I/O瓶颈
2.若 %idle的值高但系统响应慢时,有可能是 CPU等待分配内存,此时应加大内存容量
3.若 %idle的值持续低于1,则系统的 CPU处理能力相对较低,表明系统中最需要解决的资源是 CPU。
(2)内存和交换空间监控:
sar -r 2 5
17时06分08秒 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
17时06分10秒 29952524 30811920 2853740 8.70 123392 1092288 4507064 6.54 1427688 949088 140
17时06分12秒 29953020 30812436 2853244 8.70 123400 1092144 4507064 6.54 1427728 948916 244
17时06分14秒 29953020 30812436 2853244 8.70 123400 1092112 4507064 6.54 1427732 948884 244
17时06分16秒 29952524 30811944 2853740 8.70 123400 1092116 4507064 6.54 1427736 948916 244
17时06分18秒 29952816 30812236 2853448 8.70 123408 1092116 4507064 6.54 1427736 948916 248
平均时间: 29952781 30812194 2853483 8.70 123400 1092155 4507064 6.54 1427724 948944 224
输出项说明:
kbmemfree:这个值和free命令中的free值基本一致,所以它不包括buffer和cache的空间.
kbmemused:这个值和free命令中的used值基本一致,所以它包括buffer和cache的空间.
%memused:这个值是kbmemused和内存总量(不包括swap)的一个百分比.
kbbuffers和kbcached:这两个值就是free命令中的buffer和cache.
kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap).
%commit:这个值是kbcommit与内存总量(包括swap)的一个百分比.
(3)IO和传送速率监控
sar -b 2 5 //每2s采样一次,连续采样5次
17时11分31秒 tps rtps wtps bread/s bwrtn/s
17时11分33秒 2.00 0.00 2.00 0.00 824.00
17时11分35秒 15.50 0.00 15.50 0.00 224.00
17时11分37秒 0.00 0.00 0.00 0.00 0.00
17时11分39秒 20.00 0.00 20.00 0.00 204.00
17时11分41秒 1.50 0.00 1.50 0.00 48.00
平均时间: 7.80 0.00 7.80 0.00 260.00
(4)进程队列长度和平均负载状态监控
sar -q 2 5
17时13分47秒 runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked
17时13分49秒 0 505 0.85 0.95 0.98 0
17时13分51秒 3 505 0.94 0.97 0.99 0
17时13分53秒 0 505 0.94 0.97 0.99 0
17时13分55秒 0 505 0.94 0.97 0.99 0
17时13分57秒 0 505 0.87 0.95 0.99 0
平均时间: 1 505 0.91 0.96 0.99 0
输出项说明:
runq-sz:运行队列的长度(等待运行的进程数)
plist-sz:进程列表中进程(processes)和线程(threads)的数量
ldavg-1:最后1分钟的系统平均负载(Systemload average)
ldavg-5:过去5分钟的系统平均负载
ldavg-15:过去15分钟的系统平均负载
(5)设备使用情况监控
sar -d 2 5 -p
17时15分58秒 DEV tps rkB/s wkB/s areq-sz aqu-sz await svctm %util
17时16分00秒 sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17时16分00秒 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17时16分00秒 DEV tps rkB/s wkB/s areq-sz aqu-sz await svctm %util
17时16分02秒 sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17时16分02秒 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17时16分02秒 DEV tps rkB/s wkB/s areq-sz aqu-sz await svctm %util
17时16分04秒 sda 1.00 0.00 20.00 20.00 0.01 8.50 8.50 0.85
17时16分04秒 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17时16分04秒 DEV tps rkB/s wkB/s areq-sz aqu-sz await svctm %util
17时16分06秒 sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17时16分06秒 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17时16分06秒 DEV tps rkB/s wkB/s areq-sz aqu-sz await svctm %util
17时16分08秒 sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
17时16分08秒 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: DEV tps rkB/s wkB/s areq-sz aqu-sz await svctm %util
平均时间: sda 0.20 0.00 4.00 20.00 0.00 8.50 8.50 0.17
平均时间: sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
参数-p 可以打印出sda,hdc等磁盘设备名称,如果不用参数-p,设备节点则有可能是dev8-0,dev22-0
tps:每秒从物理磁盘I/O的次数.多个逻辑请求会被合并为一个I/O磁盘请求,一次传输的大小是不确定的.
rd_sec/s:每秒读扇区的次数.
wr_sec/s:每秒写扇区的次数.
avgrq-sz:平均每次设备I/O操作的数据大小(扇区).
avgqu-sz:磁盘请求队列的平均长度.
await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1秒=1000毫秒).
svctm:系统处理每次请求的平均时间,不包括在请求队列中消耗的时间.
%util:I/O请求占CPU的百分比,比率越大,说明越饱和.
1. avgqu-sz的值较低时,设备的利用率较高。
2.当%util的值接近 1%时,表示设备带宽已经占满
要判断系统瓶颈问题,有时需几个 sar 命令选项结合起来
怀疑CPU存在瓶颈,可用 sar -u和 sar -q 等来查看
怀疑内存存在瓶颈,可用 sar -B、sar -r和 sar -W 等来查看
怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d等来查看
10、网络状态查询 netstat
常见参数:
==============netstat 的参数说明============================
-a (all)显示所有选项,netstat默认不显示LISTEN相关
-t (tcp)仅显示tcp相关选项
-u (udp)仅显示udp相关选项
-n 拒绝显示别名,能显示数字的全部转化成数字。(重要)
-l 仅列出有在 Listen (监听) 的服務状态
-p 显示建立相关链接的程序名(macOS中表示协议 -p protocol)
-r 显示路由信息,路由表
-e 显示扩展信息,例如uid等
-s 按各个协议进行统计 (重要)
-c 每隔一个固定时间,执行该netstat命令。
=====================================================
(1)列出所有端口
列出所有端口: netstat -a
列出所有tcp端口: netstat -at
列出所有udp端口: netstat -au
(2)列出所有处于监听状态的 Sockets
只显示监听端口: netstat -l
只列出所有监听tcp端口: netstat -lt
只列出所有监听udp端口: netstat -lu
只列出所有监听UNIX端口: netstat -lx
(3)显示每个协议的统计信息
显示TCP统计信息: netstat -st
显示UDP统计信息: netstat -su
(4)不显示主机,端口和用户名 (host, port or user)
netstat -an
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:1080 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:60426 127.0.0.1:1080 ESTABLISHED
tcp 0 0 192.168.1.63:51720 66.98.115.46:8443 ESTABLISHED
参考文章:
1、《linux服务器日常管理学习心得》 地址:https://www.cnblogs.com/luckylihuizhou/p/6382365.html
2、《linux 查看服务器性能常用命令》 地址:http://www.cnblogs.com/grimm/p/5622932.html
3、《【性能测试】Linux性能监控命令——sar详解》 地址:https://blog.csdn.net/mig_davidli/article/details/52149993
4、《Linux netstat命令详解》 地址:https://www.cnblogs.com/echo1937/p/6677325.html