大数据离线分析场景
通常是指对海量数据进分析和处理,形成结果数据,供下一步数据应用使用。离线处理对处理时间要求不高,但是所处理数据量较大,占用计算存储资源较多,通常通过MR或者Spark作业或者SQL作业实现。离线分析系统架构中以HDFS分布式存储软件为数据底座,计算引擎以基于MapReduce的Hive和基于Spark的SparkSQL为主。

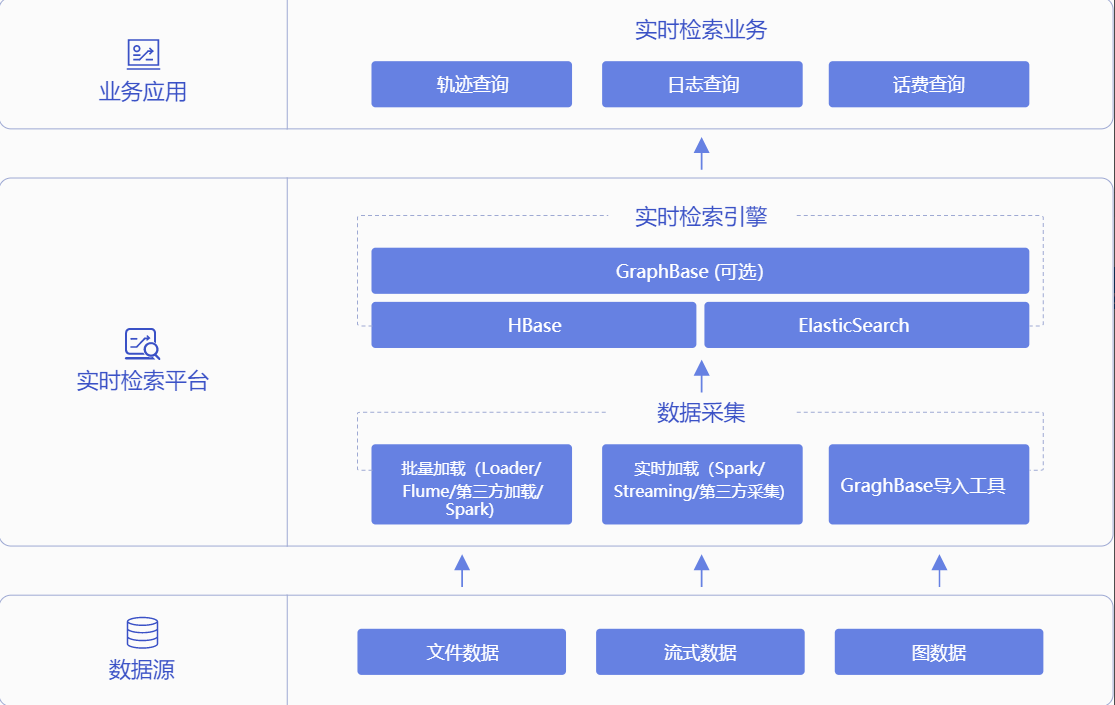
大数据实时检索场景
提供可弹性扩展、低时延、高吞吐的高性能计算资源,支持业界主流的实时分析业务平台,结合大带宽、支持多种协议的对象存储服务,提升实时分析业务整体资源利用率。
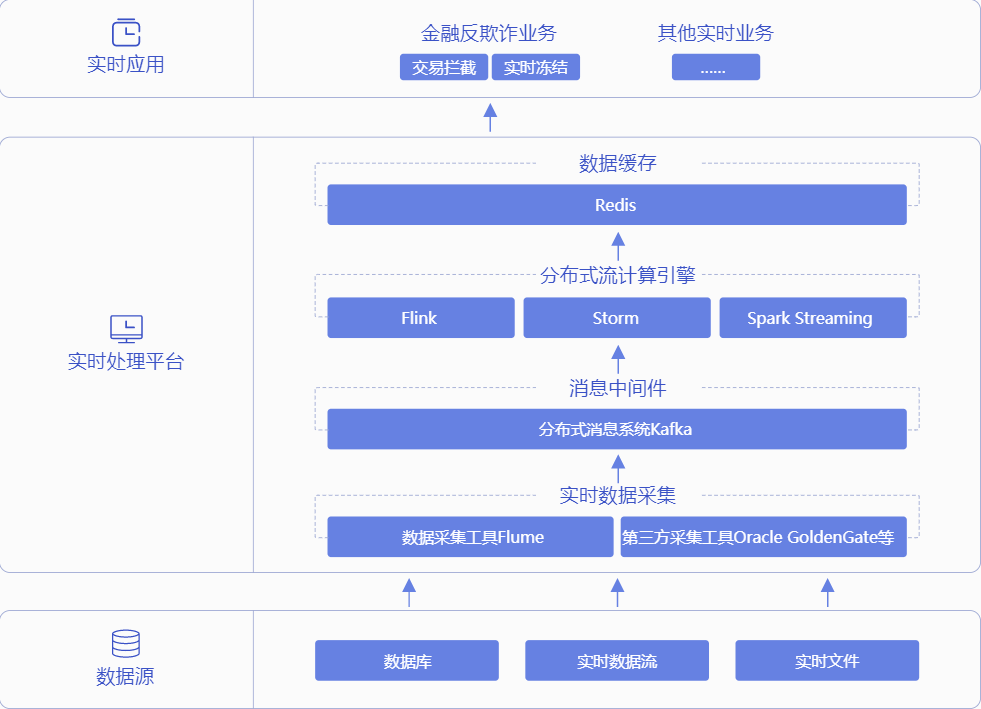
大数据实时流处理场景
常指对实时数据源进行快速分析,迅速触发下一步动作的场景。实时数据对分析处理速度要求极高,数据处理规模巨大,对CPU和内存要求很高,但是通常数据不落地,对存储量要求不高。实时处理,通常通过Storm、Spark Streaming或者Flink任务实现。数据采集通过分布式消息系统Kafka实时发送到分布式流计算引擎Flink、Storm、Spark Streaming进行数据处理,结果存储Redis为上层业务提供缓存。
@摘自【华为鲲鹏云】