功能描述:
目标 获取淘宝搜索页面的信息,提取其中的商品信息名称和价格
理解 淘宝的搜索接口 翻页的处理
技术路线 requests re
当我们在淘宝上搜索书包时:
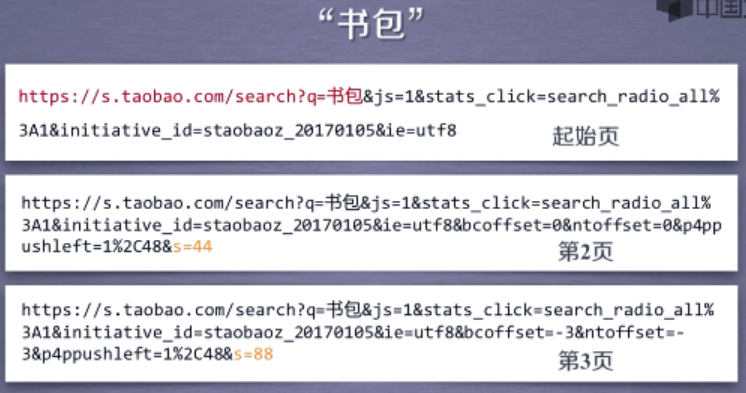
观察淘宝页面可知每一页共44个商品。
同时通过robots协议,发现不支持爬取。
程序的结构设计:
1、提交商品搜索需求,循环获取页面
2、对于每个页面,提取商品名称和价格信息
3、将信息输出在屏幕上
import requests import re def getHTMLText(url): print('') def parserPage(ilt,html): print('') def printGoodList(ilt): print('') def main(): goods='书包'#搜索关键词 depth=2#爬取深度 start_url='https://s.taobao.com/search?q='+goods#初始链接 infoList=[]#输出列表 for i in range(depth): try: url=start_url+'&s='+str(44*i) html=getHTMLText(url) parserPage(infoList,html) except: continue printGoodList(infoList) main()
代码编写习惯,先写框架,再填充丰满。
完整程序:
import requests import re def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return '' def parserPage(ilt,html): try: plt=re.findall(r'"view_price":"[d.]*"',html) tlt=re.findall(r'"raw_title":".*?"',html)#加问号最小匹配 for i in range(len(plt)): #eval函数去掉最外层的单引号 双引号 price=eval(plt[i].split(':')[1])#只保留键值对中的数字部分 title=eval(tlt[i].split(':')[1]) ilt.append([price,title]) except: print('') def printGoodList(ilt): #打印模板 tplt='{:4} {:8} {:16}' print(tplt.format('序号','价格','商品名称')) count=0 for q in ilt: count=count+1 print(tplt.format(count,q[0],q[1])) def main(): goods='书包'#搜索关键词 depth=2#爬取深度 start_url='https://s.taobao.com/search?q='+goods#初始链接 infoList=[]#输出列表 for i in range(depth): try: url=start_url+'&s='+str(44*i) html=getHTMLText(url) parserPage(infoList,html) except: continue printGoodList(infoList) main()
输出;
