第一次个人作业:词频统计
一、要求:
1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
2. 使用性能测试工具进行分析,找到性能的瓶颈并改进
3. 对代码进行质量分析,消除所有警告
4. 设计10个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)
5. 使用Github进行代码管理
6. 撰写博客
二、基本功能
1. 统计文件的字符数(Ascii码大于等于32且小于126)
2. 统计文件的单词总数(单词长度小于等于1024)
3. 统计文件的总行数(真实行数)
4. 统计文件中各单词的出现次数,输出频率最高的10个。
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
7. 在Linux系统下,进行性能分析,过程写到blog中(附加题)
注意:
a) 空格,水平制表符,换行符,均算字符
b) 单词的定义:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9
分割符:空格,非字母数字符号
例如:”file123”是一个单词,”123file”不是一个单词。file,File和FILE是同一个单词。
如果两个单词只有最后的数字结尾不同,则认为是同一个单词,例如,windows,windows95和windows7是同一个单词,iPhone4和IPhone5是同一个单词,但是,windows和windows32a是不同的单词,因为他们不是仅有数字结尾不同
输出按字典顺序,例如,windows95,windows98和windows2000同时出现时,输出windows2000
词组的定义:windows95 good, windows2000 good123,可以算是同一种词组。按照词典顺序输出。三词相同的情形,比如good123 good456 good789,根据定义,则是 good123 good123 这个词组出现了两次。若通篇只有hello world这个词组,但有HELLO和WORLD分立出现,也输出HELLO WORLD。
c) 输入文件名以命令行参数传入。需要遍历整个文件夹时,则要输入文件夹的路径。
d) 输出文件result.txt
characters: number
words: number
lines: number
<word>: number
<word>为文件中真实出现的单词大小写格式,例如,如果文件中只出现了File和file,程序不应当输出FILE,且<word>按字典顺序(基于ASCII)排列,上例中程序应该输出File: 2
e) 根据命令行参数判断是否为目录
f) 将所有文件中的词汇,进行统计,最终只输出一个整体的词频统计结果。
以上内容均在Ubantu 16.04和g++ 5.4.0下运行
有着特殊颜色标注的都是一些程序中的主要坑点,需要多多注意。
(其中一些未在第一次个人作业的最终版博客公告中出现,希望助教和老师在下次作业时尽早讲明,最好不要以QQ群消息的形式)
2.规划和PSP
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
45 |
45 |
|
.Estimate |
估计这个任务需要多少时间 |
45 |
45 |
|
Development |
开发 |
1710 |
1800 |
|
Analysis |
需求分析(包括学习新技术) |
180 |
190 |
|
.Design Spec |
生成设计文档 |
180 |
190 |
|
.Design Review |
设计复审 |
45 |
60 |
|
Coding Standard |
代码规范 |
90 |
100 |
|
Design |
具体设计 |
360 |
370 |
|
Coding |
具体编码 |
720 |
740 |
|
Code Review |
代码复审 |
45 |
60 |
|
Test |
测试(自我测试,修改代码,提交修改) |
90 |
100 |
|
Reporting |
报告 |
270 |
270 |
|
Test Report |
测试报告 |
90 |
90 |
|
Size Measurement |
计算工作量 |
90 |
90 |
|
Postmortem & Process Improvement Plan |
事后总结,并提出过程改进计划 |
90 |
90 |
|
All |
合计 |
2025 |
2125 |
2. 思路与实现
思路:
(1)字符计数——读一个字符计数一次
(2)行计数——根据文件中的换行符数+是否为空文件判断
(3)单词计数——读一个单词计数一次+注意同文件
(4)词组计数——读两个单词计数一次+注意同文件
实现流程:
寻找文件——字符计数——行计数——单词计数——词组计数——……——(找完文件)——寻找频数前十单词词组——输出各信息
功能模块一览:





3. 测试用例设计
设计了以下测试用例:
(1)空文件(char=line=word=phrase=0)。
(2)标准文件(测试集中的Aesop’s Fables.txt)文件小,测试快,单词、词组量适中。
(3)超大文件(32倍测试集中的死圣.txt)文件大(几百M),重复高,测试长时间下程序稳定性。
(4)无显式字符文件,用来测试程序对不可见字符的判读能力。
(5)各种源码文件(*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等),用来测试程序对于各种乱七八糟需要读的文件的性能。
(6)各种不用读的文件(*.jpg,*.gif,*.bmp等),用来测试程序对于各种乱七八糟需要读的文件的性能。
…………………上述为单文件测试,下面是多文件测试………………
(7)空文件夹。
(8)仅存放空文件的文件夹。
(9)存放单个文件的文件夹。
(10)仅存放多文件的文件夹。
(11)什么都有的文件夹。
(12)助教给的测试集。
4.代码性能分析(for Windows)

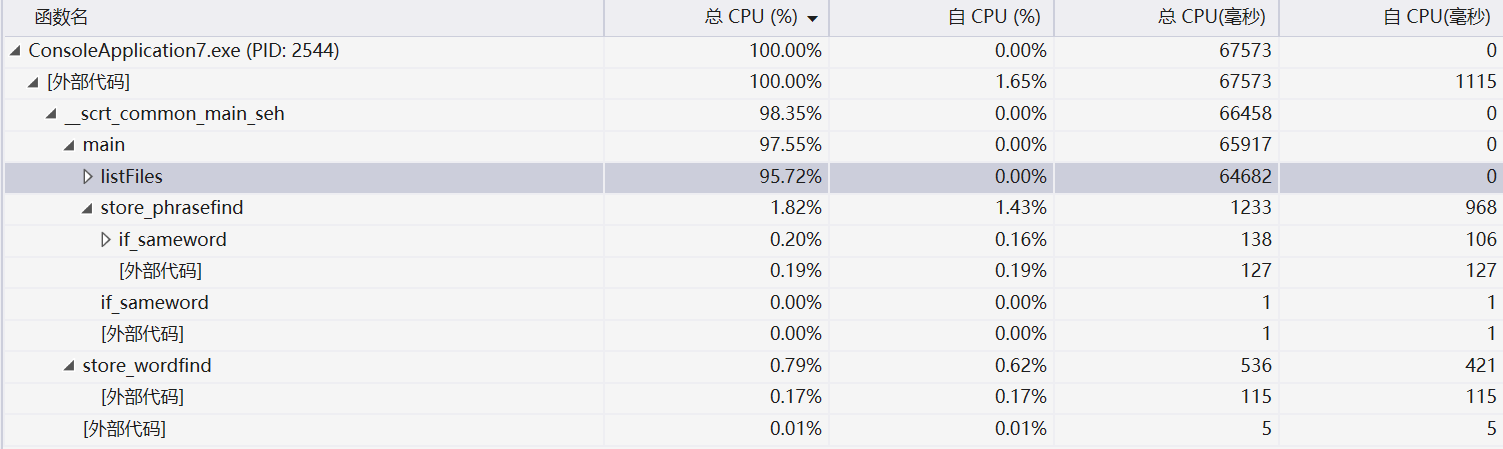


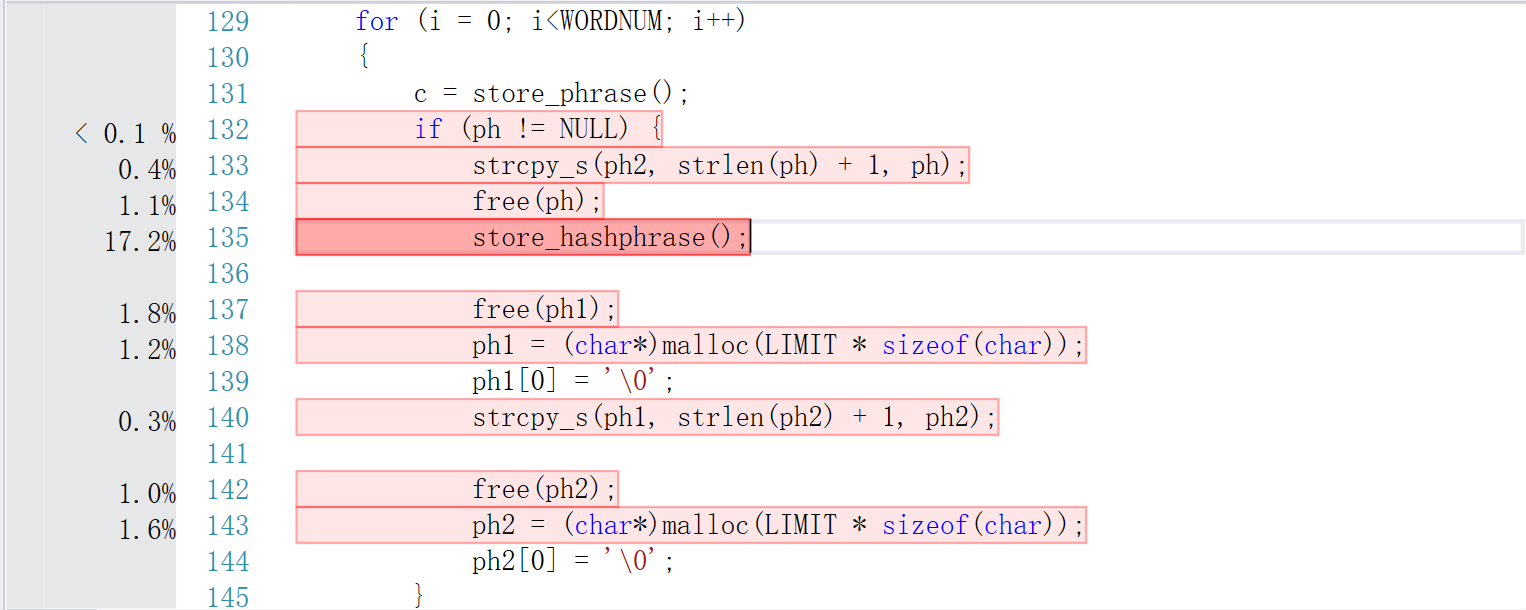

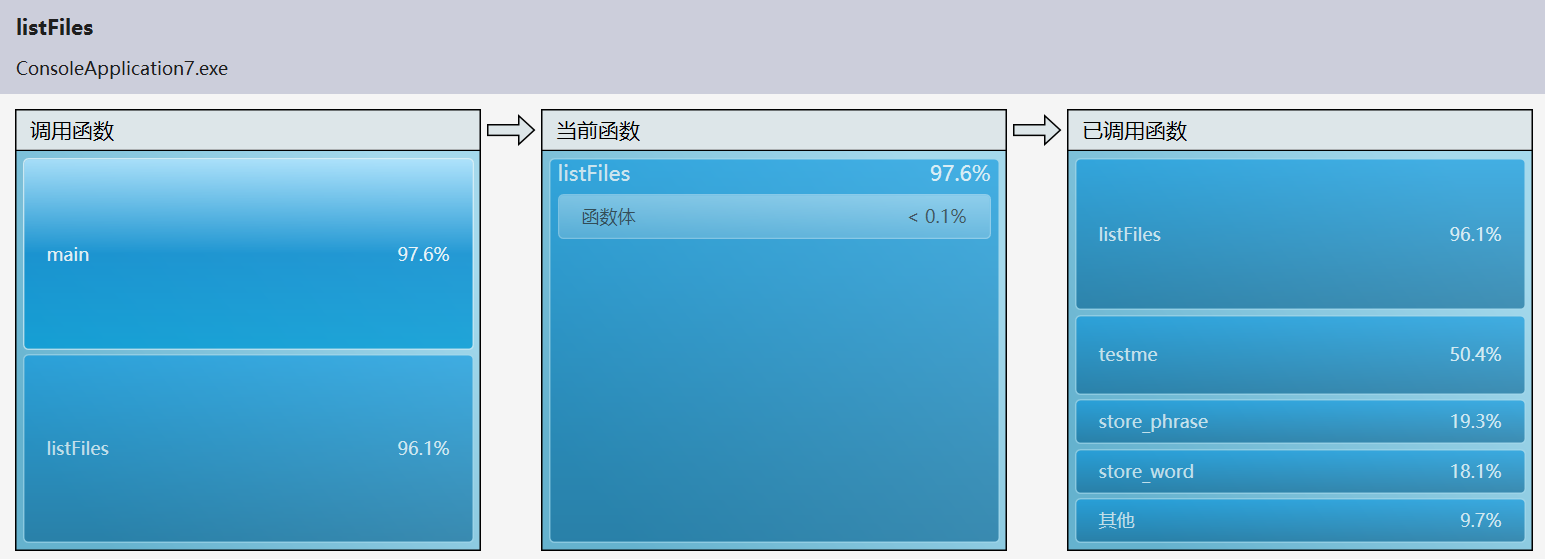
由此可见,程序执行的时候相当大的一部分开销花在了搜索文件(list Files)上,而在查找各项目的时候程序在hash表的存储(store_hashphrase&store_hashword)和循环上(字符、行数、单词数统计)。所以在削减了这两部分的开销之后,程序能够在,更短的时间内运行;再加上将程序遍历单个文件的次数由四次缩减为一次,使得效率大大提高。
另一方面,由于对单词量的过分估计——导致在开哈希表的时候一律以千万级别建立,使得程序在使用初期占用的的内存陡升。核算后发现如此大的数组不是很有必要,于是缩减到百万量级,程序占用内存的量得到了较大改观。
RESULT:

结果前三个与助教有少量出入,单词词组结果相同
分析(for Linux)
在同学的倾力相助下,在Linux上调好代码,并且利用gprof进行性能分析,得到以下结果(节选)
(如果有机会,明天贴一下Linux上的代码,尽管没在规定时间内完成,最终还是完成了这一步,也还算是圆满)
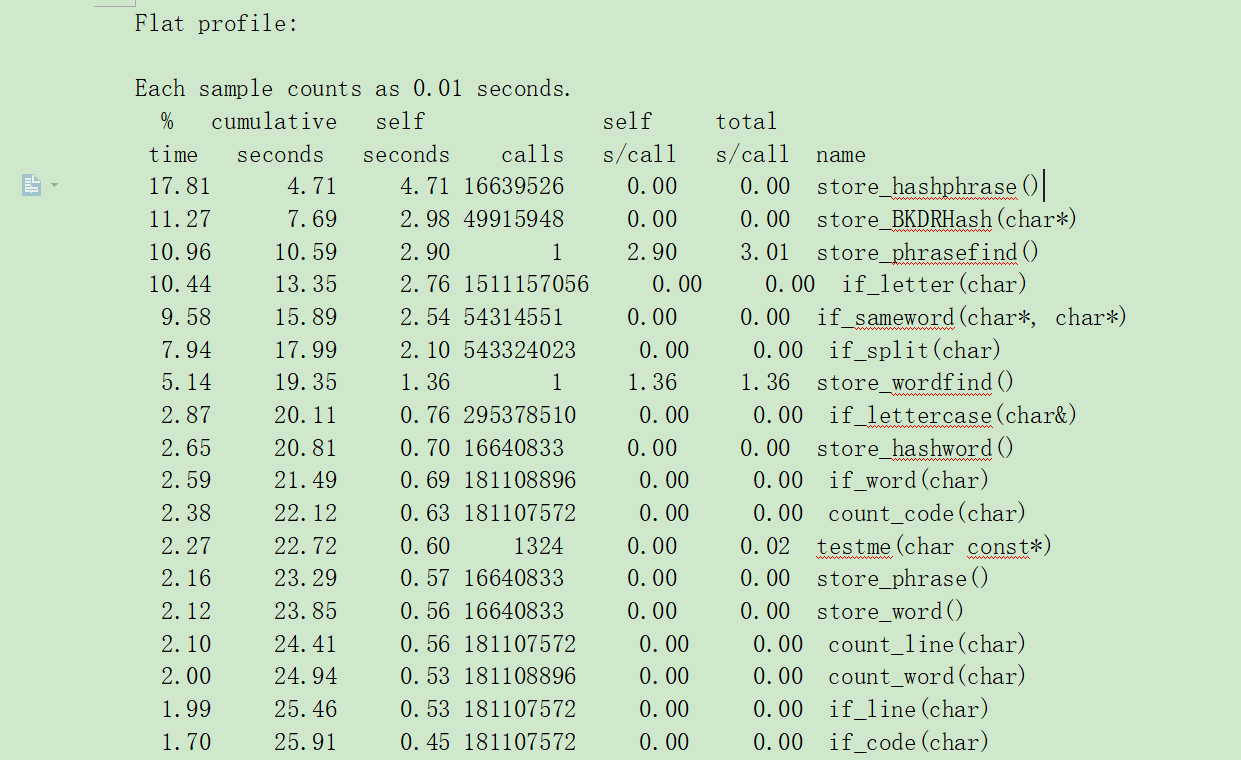
从中可以看出,哈希值计算&存储的确花费了不少时间,而且调用频繁,应该改为内联函数较好;两个find函数的时间有待进一步缩短,其他结果与Windows下出入不大。
5.在这次项目中获得的经验:
首先我想说的是,我自己果然还是能力不足,相对一些比较牛的同学来说自己的代码无论是效率还是质量都被碾压,需要努力学习一个,以获得更好的成长。
前期的规划的确是十分重要的,由于我之前对这次作业做了一个还算比较好的规划,所以时间花费还在预料之中。不过可以看出来,在这种项目中,面向对象比面向过程好用得多(个人感觉)。虽然GitHub认为我的代码成分9成以上是c++的,个人觉得我自己的思维方式还是停留在面向过程的角度,所以并没有利用好语言的特性(比如说用String类),语言的应用上还有待磨砺。
接下来说说算法方面的不足。Hash表,数组中查找前n个数的算法是我以前学习过的,但在实际运用中其实不大熟练,效果也就差强人意,甚至犯了一些很低级的错误,说明算法并不是在脑中记个大概就好了,也需要经常使用,才能更好地掌握。
之后是调试部分。一方面由于我安装的VS2015在调试时经常报错(我感觉自己应该还没有成长到可以警告编译器的地步),求助同学未果;另一方面我对于IDE的操作有待加强,在某些场合还是习惯于使用printf来debug,导致纠错的效率不太高。然后对于测试集的设计,测试个人还是较为满意的。另外采取了多人核对一份测试的方法,也让测试变得更有效率。
文件读取的破解是一个比较痛苦的过程……完全一窍不通,基本是根据网上的不全代码再加上个人分析搞出来的,居然效率还不错……然而个人时间开销有点大。最后电脑配置装不下Ubuntu,借用别人电脑测试也来不及(3.29下午完成Windows版),再加上个人对Linux操作不熟,只能作罢Linux的移植,感觉有些遗憾吧。还好第二天用Linux勉强性能分析了一波,虽然过了DDL,也算是补了一些遗憾。
总的来说,这次个人作业我收获了很多,也暴露了自己的一些不足,希望自己在之后再接再厉,能在这方面不断进步。