Pandas 讲解
Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
Series:一维数组,与Numpy中的一维array类似。 二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型, 而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。 Time- Series:以时间为索引的Series。 DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。 可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。 Panel :三维的数组,可以理解为DataFrame的容器。
---------------------------------------------------
Series
Series 是一种类似于一维数组的对象, 它由一组数据(各种numpy数据类型)以及一组与之相关的数据标签(索引)组成。
""" In [1]: from pandas import Series In [2]: from pandas import DataFrame In [3]: obj = Series([4, 7, -5, 3]) In [4]: obj Out[4]: 0 4 1 7 2 -5 3 3 dtype: int64 """
Series 索引,指定索引(也就是左边的列)
通过 上面的例子, 我们知道Series的字符表现形式为索引在左边, 值在右边。没有指定索引,
那么索引会自动从0开始的整数型索引
可以通过Series的values和index属性获取其数组表示形式和索引对象。
""" In [5]: obj.values Out[5]: array([ 4, 7, -5, 3]) In [6]: obj.index Out[6]: RangeIndex(start=0, stop=4, step=1) """
那么我们可以自定义索引
In [7]: obj2 = Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c']) In [8]: obj2 Out[8]: d 4 b 7 a -5 c 3 dtype: int64 In [9]: obj2.index Out[9]: Index([u'd', u'b', u'a', u'c'], dtype='object')
索引赋值
In [11]: obj2['d'] = 9 In [12]: obj2 Out[12]: d 9 b 7 a -5 c 3 dtype: int64
索引取值
In [13]: obj2[["a", "b", "c"]] Out[13]: a -5 b 7 c 3 dtype: int64
索引值映射
In:'b' in obj2 Out:True In:'f' in obj2 Out:False
通过字典创建Series
""" In [14]: sdata = {"Ohio":3500, "Texas":71000, "Oregon":16000, "Utah":51000} In [15]: obj3 = Series(sdata) In [16]: obj3 Out[16]: Ohio 3500 Oregon 16000 Texas 71000 Utah 51000 dtype: int64 """
索引匹配值和判断缺失
相对应Series也可以匹配对应的索引,如果找不到结果为NaN(非数字),pandas中用于表示缺失的数据
同时isnull和notnull函数用于检测缺失数据。
In [17]: states = ['California', 'Ohio', 'Oregon', 'Texas'] In [18]: obj4 = Series(sdata, index=states) In [19]: obj4 Out[19]: California NaN Ohio 3500.0 Oregon 16000.0 Texas 71000.0 dtype: float64
In [22]: pd.isnull(obj4) Out[22]: California True Ohio False Oregon False Texas False dtype: bool ------------- In [23]: pd.notnull(obj4) Out[23]: California False Ohio True Oregon True Texas True dtype: bool ----------- In [24]: obj4.isnull() Out[24]: California True Ohio False Oregon False Texas False dtype: bool
Series 数据对齐
In [25]: obj3 + obj4 Out[25]: California NaN Ohio 7000.0 Oregon 32000.0 Texas 142000.0 Utah NaN dtype: float64
name属性
Series 对象本身及其索引都有一个name属性, 该属性跟pandas其他的关键功能关系非常密切
In [26]: obj4.name = 'population' In [27]: obj4.index.name = 'state' In [29]: obj4 Out[29]: state California NaN Ohio 3500.0 Oregon 16000.0 Texas 71000.0 Name: population, dtype: float64
Series修改索引名称
Series 的索引也可以通过索引的方式就地修改
In [30]: obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan'] In [31]: obj Out[31]: Bob 4 Steve 7 Jeff -5 Ryan 3 dtype: int64
--------------------------------------------------------
DataFrame及常用方法
ix 标签索引
T index和columns变换方向
index
reindex
DataFrame 是一个表格行的数据结构, 他含有一组有序的列,每列可以是不同的值类型
(数值,字符串,布尔值等)。
DataFrame既有行索引也有列索引,他可以被看做是由Series组成的字典(共用同一个索引)
跟其他类似的数据结构相比,DataFrame中面向行和面向列的操作基本上是平衡的。
DataFrame 是以二维数据结构保存数据的
构建DataFrame
最常用的一种是直接传入一个有等长列表或Numpy数组组成的字典
In [2]: data = {"state": ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'], 'year':[2000, 2001, 2002, 2001, 2002], 'pop':[1.5, 1.7, 3.6, 2.4, 2.9]}
In [3]: from pandas import Series, DataFrame
In [4]: DataFrame(data)
Out[4]:
pop state year
0 1.5 Ohio 2000
1 1.7 Ohio 2001
2 3.6 Ohio 2002
3 2.4 Nevada 2001
4 2.9 Nevada 2002
另一种嵌套字典生成DataFrame
In [29]: pop = {'Nevada': {2001:2.4, 2003:2.9}, 'Ohio':{2000:1.5, 2001:1.7, 2002:3.6}}
In [30]: frame3 = Dataframe(pop)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-30-da7c61f3c94a> in <module>()
----> 1 frame3 = Dataframe(pop)
NameError: name 'Dataframe' is not defined
In [31]: frame3 = DataFrame(pop)
In [32]: frame3
Out[32]:
Nevada Ohio
2000 NaN 1.5
2001 2.4 1.7
2002 NaN 3.6
2003 2.9 NaN
第三种:
>>> d = [{"a":1,"b":2}, {"b":1,"a":2}]
>>> D = DataFrame(d)
>>> D
a b
0 1 2
1 2 1
第四种
In [52]: data = DataFrame(np.arange(16).reshape((4,4)), index=["Ohio", "Colorado", "Utah", "New York"], columns=["one", "two", "three", "four"]) In [53]: data Out[53]: one two three four Ohio 0 1 2 3 Colorado 4 5 6 7 Utah 8 9 10 11 New York 12 13 14 15
DataFrame 的列按照顺序进行排列(列排序)
In [6]: DataFrame(data, columns=['year', 'state', 'pop']) In [7]: data Out[7]: year state pop 0 2000 Ohio 1.5 1 2001 Ohio 1.7 2 2002 Ohio 3.6 3 2001 Nevada 2.4 4 2002 Nevada 2.9
跟Series一样,如果传入的列在数据中找不到, 就会产生NA值
In [11]: frame2 = DataFrame(data, columns=['year', 'state', 'pop', 'debt'], index=['one', 'two', 'three', 'four', 'five']) In [12]: frame2 Out[12]: year state pop debt one 2000 Ohio 1.5 NaN two 2001 Ohio 1.7 NaN three 2002 Ohio 3.6 NaN four 2001 Nevada 2.4 NaN five 2002 Nevada 2.9 NaN
axis=0和1分别的表格的纵轴和横轴
通过字典标记(索引)的方式获取一个Series
In [13]: frame2['year'] 也可以写成frame2.year Out[13]: one 2000 two 2001 three 2002 four 2001 five 2002 Name: year, dtype: int64
返回的Series拥有同样的索引
行也可以通过位置或名称的方式进行获取,例如用索引字段ix
In [14]: frame2.ix['three'] Out[14]: year 2002 state Ohio pop 3.6 debt NaN Name: three, dtype: object
索引赋值
In [23]: df2.loc['d'] = [i*0 for i in range(len(df2.columns))] In [24]: df2 Out[24]: b d e dd Uhahdd 0.0 1.0 2.0 0 Ohiodd 3.0 4.0 5.0 0 Texasdd 6.0 7.0 8.0 0 Oregondd 9.0 10.0 11.0 0 dd 1.0 2.0 3.0 4 d 0.0 0.0 0.0 0
列表推到式还可以写成
map(lambda x:0 if x >0 else 0, a)
列赋值
列可以通过赋值的方式进行修改。例如我们可以给那个空的‘debt’列附上一个附上一个标量或一组值
In [15]: frame2['debt'] = 16.5 In [16]: frame2 Out[16]: year state pop debt one 2000 Ohio 1.5 16.5 two 2001 Ohio 1.7 16.5 three 2002 Ohio 3.6 16.5 four 2001 Nevada 2.4 16.5 five 2002 Nevada 2.9 16.5
In [17]: import numpy as np In [18]: frame2['debt'] = np.arange(5.) In [19]: frame2 Out[19]: year state pop debt one 2000 Ohio 1.5 0.0 two 2001 Ohio 1.7 1.0 three 2002 Ohio 3.6 2.0 four 2001 Nevada 2.4 3.0
将一个列表或数组赋值给某个列时, 如果赋值的是Series, 就会精确匹配DataFrame的索引,
所有的空值将会被填上缺失值。
n [20]: val = Series([1.2, 1.3, -1.2], index=['two', 'four', 'five']) In [21]: frame2['debt'] = val In [22]: frame2 Out[22]: year state pop debt one 2000 Ohio 1.5 NaN two 2001 Ohio 1.7 1.2 three 2002 Ohio 3.6 NaN four 2001 Nevada 2.4 1.3 five 2002 Nevada 2.9 -1.2
创建列
可以创建新列
In [23]: frame2['eastern'] = frame2.state == 'Ohio' In [24]: frame2 Out[24]: year state pop debt eastern one 2000 Ohio 1.5 NaN True two 2001 Ohio 1.7 1.2 True three 2002 Ohio 3.6 NaN True four 2001 Nevada 2.4 1.3 False five 2002 Nevada 2.9 -1.2 False
删除列
In [26]: del frame2['eastern'] In [27]: frame2 Out[27]: year state pop debt one 2000 Ohio 1.5 NaN two 2001 Ohio 1.7 1.2 three 2002 Ohio 3.6 NaN four 2001 Nevada 2.4 1.3 five 2002 Nevada 2.9 -1.2
In [28]: frame2.columns
Out[28]: Index([u'year', u'state', u'pop', u'debt'], dtype='object')
结果 行、列倒置,调换位置
In [33]: frame3.T Out[33]: 2000 2001 2002 2003 Nevada NaN 2.4 NaN 2.9 Ohio 1.5 1.7 3.6 NaN
内层字典的键会被合并、排序以形成最终的索引。如果显示指定了索引, 则按照索引走
In [35]: DataFrame(pop, index=[2001, 2002, 2003, 2004]) Out[35]: Nevada Ohio 2001 2.4 1.7 2002 NaN 3.6 2003 2.9 NaN 2004 NaN NaN
也可以根据索引key和切片取值赋值
In [36]: pdata = {'Ohio': frame3['Ohio'][:-1], 'Nevada': frame3['Nevada'][:2]}
In [39]: DataFrame(pdata)
Out[39]:
Nevada Ohio
2000 NaN 1.5
2001 2.4 1.7
2002 NaN 3.6
可以输入给DataFrame构造器的数据
二维ndarray 数据矩阵,还可以传入行标和列标 由数组、列表和元组组成的字典 每个序列会变成DataFrame的一列。 所有序列的长度必须相同 Numpy的结构化/记录数组 类似于“由数组组成的字典” 由Series组成的字典 每个Series会成为一列。如果没有显示指定索引, 则各Series的索引会被合并成结果的行索引 由字典组成的字典 各内层字典会成为一列。键会被合并成结果的行索引,跟"由Series组成的字典"的情况一样 字典或Series的列表 各项将会成为DataFrame的一行。字典键或Series索引的并集将会成为DataFrame的列标 由列标或元组组成的列表 类似于“二维ndarray” 另一个DataFrame 该DataFrame的索引将会被沿用,除非显示指定了其他索引 Numpy的MaskedArray 类似于"二维ndarray"的情况, 只是掩码值在结果DataFrame会变成NA/缺失值
行标,列标设置别名
In [40]: frame3.index.name = "year"; frame3.columns.name = "state" In [41]: frame3 Out[41]: state Nevada Ohio year 2000 NaN 1.5 2001 2.4 1.7 2002 NaN 3.6 2003 2.9 NaN
获取数据
DataFrame以二维ndarray的形式返回数据
In [42]: frame3.values Out[42]: array([[ nan, 1.5], [ 2.4, 1.7], [ nan, 3.6], [ 2.9, nan]])
如果DataFrame各列的数据类型不同, 则值数组的数据类型就会选用能兼容所有列的数据类型
----------------------------------------
索引对象
pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等。)构建Series或Data Frame时,所用到的任何数组或其他序列的标签都会被转换成一个Index。
In [1]: from pandas import Series, DataFrame In [2]: obj = Series(range(3), index=["a", "b", "c"]) In [3]: index = obj.index In [4]: index Out[4]: Index([a, b, c], dtype=object) In [5]: obj Out[5]: a 0 b 1 c 2 In [6]: index[1:] Out[6]: Index([b, c], dtype=object)
而索引是不可修改的
那么根据上面的例子,报错,证明索引是不可以修改的
In [7]: index[1] Out[7]: 'b' In [8]: index[1] = "d" --------------------------------------------------------------------------- Exception Traceback (most recent call last) C:Python27<ipython-input-8-092906bbf8a9> in <module>() ----> 1 index[1] = "d" C:Python27libsite-packagespandascoreindex.pyc in __setitem__(self, key, value) 307 def __setitem__(self, key, value): 308 """Disable the setting of values.""" --> 309 raise Exception(str(self.__class__) + ' object is immutable') 310 311 def __getitem__(self, key): Exception: <class 'pandas.core.index.Index'> object is immutable
而这样做的目的是index对象在多个数据结果之间安全共享
In [11]: index = pd.Index(np.arange(3)) In [12]: index Out[12]: Int64Index([0, 1, 2], dtype=int64) In [13]: obj2 = Series([1.5, -2.5, 0], index=index) In [14]: obj2 Out[14]: 0 1.5 1 -2.5 2 0.0
证明是共享的
In [16]: obj2.index is index
Out[16]: True
pandas中主要的Index对象
Index 最泛化的Index对象, 将轴标签表示为一个由python对象组成的Numpy数组
Int64Index 针对整数的特殊Index
MultiIdex “层次化”索引对象, 表示单个轴上的多层索引。可以看做由元组组成的数组
DatatimeIndex 存储纳秒级时间戳(用NumPy的datatime64类型表示)
PeriodIndex 针对Period数据(时间jiange)的特殊Index
Index的方法和属性
append 连接另一个index对象,产生另一个新的Index
diff 计算差集,并得到一个index
intersection 计算交集
union 计算并集
isin 计算一个指示各值是否都包含在参数集合中的布尔型数据
delete 删除索引i处的元素,bing得到一个新的Index
drop 删除传入的值,并得到新的Index
insert 将元素插入到索引i出, 并得到新的index
is_monotonic 当各元素均大于等于前一个元素是,返回True
is_unique 当index没有重复值时,返回True
unique 计算Index中唯一值的数组
In [42]: index3.delete(2) Out[42]: Int64Index([0, 1, 4, 5, 6], dtype=int64) In [28]: index3 = index.append(Index2) In [29]: index3 Out[29]: Int64Index([0, 1, 2, 4, 5, 6], dtype=int64)
reindex重新索引 (fill_value 设置默认值)
pandas对象的一个重要方法是reindex, 其作用是创建一个适应新索引的新对象。
而调用Series的reindex将会根据新索引进行重排。如果某个索引值不存在,就引入缺失值。
obj = Series([4.5, 7.l2, -5.3, 3.6], index=['d', 'b', 'a', 'c']) In [25]: obj2 = obj.reindex([i for i in list("abcde")], fill_value=0) In [26]: obj2 Out[26]: a -5.2 b 7.2 c 3.6 d 4.5 e 0.0 dtype: float64
但是注意:时间序列这样的有序数据, 重新索引时可能需要做一些插值处理。method选项即可达到目的
例如使用ffill可以实现向前值填充:
In [27]: obj3 = Series(["blue", "purple", "yellow"], index=[0, 2, 4]) In [28]: obj3.reindex(range(6), method="ffill") Out[28]: 0 blue 1 blue 2 purple 3 purple 4 yellow 5 yellow dtype: object In [29]: obj3 Out[29]: 0 blue 2 purple 4 yellow dtype: object

reindex 可以重新 修改(行)索引、列, 或两个都可以修改。传入一个值默认为行索引
In [33]: frame = DataFrame(np.arange(9).reshape((3, 3)), index=[i for i in list('abc')], columns=["Ohio", "Texas", "California"]) In [34]: frame Out[34]: Ohio Texas California a 0 1 2 b 3 4 5 c 6 7 8 In [35]: frame2 = frame.reindex([i for i in list("abcd")]) In [36]: frame2 Out[36]: Ohio Texas California a 0.0 1.0 2.0 b 3.0 4.0 5.0 c 6.0 7.0 8.0 d NaN NaN NaN In [37]: states = ["Texas", "Utah", "California"] In [38]: frame.reindex(columns=states) Out[38]: Texas Utah California a 1 NaN 2 b 4 NaN 5 c 7 NaN 8 In [39]: frame.ix[[i for i in list("abcd")], states] Out[39]: Texas Utah California a 1.0 NaN 2.0 b 4.0 NaN 5.0 c 7.0 NaN 8.0 d NaN NaN NaN

-------------------------------------------------------------------
Series 和 DataFrame 丢弃指定轴上的项 pandas删除行
丢弃某条轴上的一个或多个项很简单, 只要偶一个索引数组或列表即可。
而drop方法返回的是一个在指定轴上删除了指定值的新对象。
In [46]: obj = Series(np.arange(5.), index=[i for i in list("abcde")]) In [47]: obj Out[47]: a 0.0 b 1.0 c 2.0 d 3.0 e 4.0 dtype: float64 In [48]: new_obj = obj.drop("c") In [49]: new_obj Out[49]: a 0.0 b 1.0 d 3.0 e 4.0 dtype: float64 In [50]: obj.drop(["b", "c"]) Out[50]: a 0.0 d 3.0 e 4.0 dtype: float64
而DataFrame可以删除任意轴上的索引值
In [52]: data = DataFrame(np.arange(16).reshape((4,4)), index=["Ohio", "Colorado", "Utah", "New York"], columns=["one", "two", "three", "four"]) In [53]: data Out[53]: one two three four Ohio 0 1 2 3 Colorado 4 5 6 7 Utah 8 9 10 11 New York 12 13 14 15 In [54]: data.drop(["Colorado", ""Ohio]) File "<ipython-input-54-8d771dda6c46>", line 1 data.drop(["Colorado", ""Ohio]) ^ SyntaxError: invalid syntax In [55]: data.drop(["Colorado", "Ohio"]) Out[55]: one two three four Utah 8 9 10 11 New York 12 13 14 15 ------- In [57]: data.drop(["one"], axis=1) Out[57]: two three four Ohio 1 2 3 Colorado 5 6 7 Utah 9 10 11 New York 13 14 15 In [58]: data.drop(["one", "four"], axis=1) Out[58]: two three Ohio 1 2 Colorado 5 6 Utah 9 10 New York 13 14
---------------------------------------------
索引选取和过滤
Series
Series 索引(obj[...])的工作方式类似与Numpy数组的索引,只不过Series的索引值不只是整数
In [8]: obj = Series(np.arange(4.), index = [i for i in list("abcd")]) In [9]: obj['b'] Out[9]: 1.0 In [10]: obj[1] Out[10]: 1.0 In [11]: obj[2:4] Out[11]: c 2.0 d 3.0 dtype: float64 In [12]: obj[['b', 'c', 'd']] Out[12]: b 1.0 c 2.0 d 3.0 dtype: float64 In [13]: obj[[1, 3]] Out[13]: b 1.0 d 3.0 dtype: float64 In [14]: obj[obj<2] Out[14]: a 0.0 b 1.0 dtype: float64
利用索引赋值
In [15]: obj['b':'c'] Out[15]: b 1.0 c 2.0 dtype: float64 In [16]: obj['b':'c'] = 5 In [17]: obj Out[17]: a 0.0 b 5.0 c 5.0 d 3.0 dtype: float64
DataFrame
而DataFrame进行索引就是获取一个或多个列, 默认是columns
data【columns, index】的格式


In [18]: data = DataFrame(np.arange(16).reshape((4,4)), index=['Ohio', 'Colorado', 'Utah', 'New York'], columns = ['one', 'two', 'three', 'four']) In [19]: data Out[19]: one two three four Ohio 0 1 2 3 Colorado 4 5 6 7 Utah 8 9 10 11 New York 12 13 14 15 In [20]: data['two'] Out[20]: Ohio 1 Colorado 5 Utah 9 New York 13 Name: two, dtype: int64 In [21]: data[['three', 'one']] Out[21]: three one Ohio 2 0 Colorado 6 4 Utah 10 8 New York 14 12 In [23]: data[:2] Out[23]: one two three four Ohio 0 1 2 3 Colorado 4 5 6 7 In [24]: data[data['three'] > 5] Out[24]: one two three four Colorado 4 5 6 7 Utah 8 9 10 11 New York 12 13 14 15
值为bool类型
In [25]: data < 5 Out[25]: one two three four Ohio True True True True Colorado True False False False Utah False False False False New York False False False False
重新赋值
In [26]: data[data < 5] = 0 In [27]: data Out[27]: one two three four Ohio 0 0 0 0 Colorado 0 5 6 7 Utah 8 9 10 11 New York 12 13 14 15
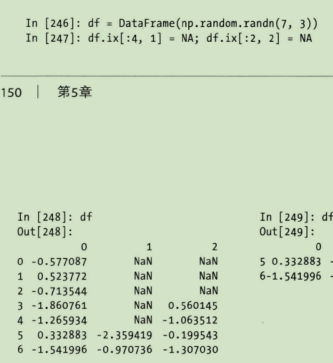
DataFrame.ix
如果DataFrame 使用标签索引的话,就是index,需要引入专门的ix,其实就是调换方向
data【index, columns】
In [28]: data.ix['Colorado', ['three']] Out[28]: three 6 Name: Colorado, dtype: int64 In [29]: data.ix[['Colorado', 'Utah'], [3, 0, 1]] Out[29]: four one two Colorado 7 0 5 Utah 11 8 9
Chrome://flags/#enable-smooth-scrolling