1.Hash表的结构
首先,允许我们花一点时间来简单介绍hash表。
1.什么是hash表
hash表是一种二维结构,管理着一对对<Key,Value>这样的键值对,Hash表的结构如下图所示:
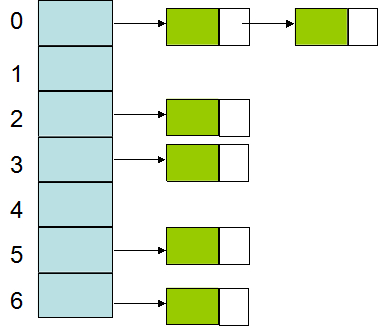
如上图所示,左侧部分是一个一维顺序存储的数组,数组单元格里的内容是指向另一个链式数组的指针。图中绿色部分是<Key,Value>,绿色部分右侧的白色部分是指向下一对键值对的指针。
hash表的工作原理:
(1).第一步 先根据给定的key和散列算法得到具体的散列值,也就是对应的数组下标。
(2).第二步,根据数组下标得到此下标里存储的指针,若指针为空,则不存在这样的键值对,否则根据此指针得到此链式数组。(此链式数组里存放的均为一对对<Key,Value>)。
(3).遍历此链式数组,分别取出Key与给定的Key比较,若找到与给定key相等的Key,即在此hash表中存在此要查找的<Key,Value>键值对,此后便可以对此键值对进行相关操作;若找不到,即为不存在此 键值对。
所以hash表其实就是管理一对对<Key,Value>这样的结构。
2.不可避免的hash冲突
总所周知,hash表是管理着一组组的<key,Value>的数据结构,访问时对Key采取散列算法求值,根据此值得到链式数组,根据链式数组取得Value.那对一个给定的Key是怎么的呢?
散列技术基于散列算法,理想情况下是将相同的key散列为相同的值,不同的key散列为不同的值。但是实际情况下,因为存储空间有限,使得这种算法是不可能被实现的,所以当不同的key被散列为相同的值时,便产生了冲突。这就是我们所说的hash冲突,下面我们来谈一谈为什么这种算法是不可能实现的?
理想情况下一维的hash表 :如下图:
![]()
(2)理想情况下的一维hash表
理想情况下的一维hash表存放的是一对对<key,Value>键值,
1.对hash散列算法的要求:不同的Key必须散列为不同的值,相同的Key必须散列为相同的值。
2.对数组的要求,为了保持访问的高效,必须保持为顺序存储的数组。(链式数组的访问时间为logn,而且还必须时刻维持平衡树的结构代价较大,不符合要求)。
OK....那么问题来了,理想情况下的hash表能完美解决以下问题吗:
(1).为了高效,你是顺序存储的数组,那么你知道你每次需要开辟多大的存储给此数组吗?如果太大,势必会造成空间的浪费,而且此空间还必须是连续的,如果过小,需要不断调整。这样你还能维持高效吗?
(2).针对每个<Key,Value>你又准备多大的空间去存储此键值对呢?很遗憾的告诉你...你不知道。过大过小都会面对刚才我们提出的问题?
问题出现后,总会有那么几个天才冒出来?
3.hash表的完美实现(允许冲突的存在)
hash查找是一种高效的查找,在存储空间和查找时间的相互妥协下,有人提出来了一种新的想法,即允许将不同的key散列为相同的值。
具体实现如下:
1.先在空间中开辟一个数组。我们首先根据key和散列算法取得数组的下标,也就是上图部分的左侧数组。
2.数组中的每个单元格维持着一个链式数组,链式数组里存放<Key,Value>.
3.访问的时候,根据key一一比较,若找到,取得到value,若找不到,不同的编程语言返回着不同的值.
4.存储的时候,先查找此key是否存在,若存在则修改此Value值,若不存在,则在此链式数组的尾部加上一个一对<Key,Value>;
有以上我们可以看出,利用hash表存储对象,查询的时候速度是非常快的。左侧数组可以随机访问,右侧链式数组虽然需要遍历,但是如果散列算法够出色的话,每个链式数组存储的键值对数量就会很小。查找的速度也足够快。理想情况下查找速度几乎可以达到o(1)。
2.JavaScript中对象的存储形式?
1.两种创建对象的区别
(1).用构造函数创建对象
1 var object=new Object(); 2 object.x=1; 3 object.2=1; //出错,因为变量不能以数字开头..
以上的错误相信大家都知道,那么用字面量创建对象呢?
(2).用字面量创建对象
var object = { x: 1, 2: 2 };//不会报错
(3)两种方式比较
两则相比,大家不觉得奇怪吗?------为什么第一种方式报错,第二种反而不会?
当然你也可以理解为JS引擎对语法错误的屏蔽.那么JS引擎干嘛要费那么大的劲去屏蔽违法的变量呢?答案就是:---事出必有因
假设JS允许通过下面这种方式赋值或者访问
object.2=2; //假设不会出错
2==2;
console.log(2);//那么出现这种方式的时候,你让JS引擎怎么办?是把2当做全局变量理解还是数字2
当出现这样的情况,解释器也只能干瞪眼了.所以为了语法的统一,才对以变量的形式的访问对象的变量定义了各种要求,
也就是说,js引擎对于违法变量的屏蔽是合理的。
那么问题又来了----
//既然,对变量的形式规定了要求,那么又干嘛允许这种玩意存在呢?-----答案就是:因为它也是合理的/
var object = {
x:1, 2: 2 };
为什么上面这种方式合理呢?
因为在hash表的<Key,Value>键值对中并没有对key提出这样或者那样的要求。所以,如果JS对象是基于Hash表存储变量的,既然在存储时这种形式合法,那么你又为什么不允许我访问我存储的变量呢? 这不是自相矛盾吗!
当然,这里有一个逻辑性的问题,我为什么认同JS对象的存储是基于Hash的呢?(这点在第三部分我会给出解释)
以上列举了两种定义对象变量方法以及区别,进而解释了为什么两种定义形式明明相互冲突却又同时存在!
下面开始我们的讨论: JS对象在hash表中Key到底是什么?------答案:字符串
首先来看一下他的输出结果
var object = { x: 1, 2: 2 } for (var property in object) { console.log('(' + typeof property + ')' + property + ':' + object[property]); }
//结果 (string)2:2
// (string)x:1
以上的代码证明了两点: object[2]是真的存在的..并且<Key,Value>中的key是以字符串的形式存在。也就是说,对象的变量和值作为<Key,Value>键值对存储在hash表中,key是以字符串的形式存在,那么value是以什么形式存在呢? 这点我们以后再讨论。也很值得讨论。
总结:
用字面量初始化的对象的时候,变量名可以使数字,也可以是字符串,但是不可以是对象(下面会给出解释), 但是以后用[]访问的时候,[]中的内容则可以是对象,只要[]中内容可以转换为字符串就可以。
初始化对象的两种形式都是合法的,但是在以.号访问变量时只能访问我们平时所说的合法变量,以[]访问时则比较自由,也没有那么多的要求,这是JS设计时候存在的缺点,但同时也是JS语言的有点。
为什么对象初始化的时候不能用对象作为变量,如下所示,:
var object={
{x:1}:2 //这种形式是错误的,因为解释器不能正确识别这种语法,会报错。-----理论上是可以做到的,可能是设计的时候存在的缺陷。
}
//以下的方式则不会报错
var object={};
object[{x:1}]=1;
console.log(object[{x:1}]) ;//1 解释器会尽力量把[]中的内容解释成字符串。
知道看Key是字符串,那么我们现在可以解释这个问题了:object[2]和object["2"]有区别吗?-----(没有,当然,关于这点也得看你怎么理解)!为了证明这两种形式没有区别我们看下面两个例子
请思考:用[]访问对象变量的时候,解释器帮我们都干了什么?
var object = { x: 1, 2: 2 } console.log(object[2]);//2 console.log(object["2"]);//2 object[2]=3; console.log(object["2"]);//3
之所以object[2]和object["2"]等效,那是因为解释器帮我们干了一点活,那么解释器帮我们干了什么呢?
解释器在访问object[2]的时候,先将方括号里面的2转换成字符串。然后再访问,为了证明这点,我写了一点代码证明这点。
var object = { x: 1, 2: 2 } Object.prototype.toString = function () { return '2'; } console.log(object[{x: 1}]); //2
console.log(object["2"]); //2
console.log(object[2]); //2
下面花一点时间来分析上述代码的执行过程:
1.首先定义并初始化了一个object对象,对象中存在两个变量。
2.重写了Object原型中的toString()方法。
3.第7行输出时对于[]中我们用了一个临时的对象{x:1}。此对象被初始化后,在object[]执行时,先分析方括号中{x:1},此时解释器为了将此对象转换为字符串,如果是引用类型会调用原型对象中的toString()函数,如果是基本数据类型是也会将基本数据类型转化为对应字符串,结果即是访问object["2"].输出的结果也就是2了。
所以我们也间接证明了JS对象中,所有的key都是字符串,即使你访问的时候不是字符串的形式,解释器也会尽力先将其转化为字符串。
所以下面两种方式初始化对象是完全等效的:
1 var object1 = { 2 x: 1, 3 1: 2 4 } //第一种 5 var object2 = { 6 'x': 1, 7 '1': 2 8 } //第二种
以上我们讨论的是 JS对象的存储形式以及数据是怎么存放的。
下面我们讨论,为什么说JS中对象存储的变量是基于hash的。
3.JavaScript中的对象基于Hash表存储变量。
(1).证明:
我们可以随时给一个对象增加或删除变量(如果此变量允许删除的话)
1 var object={}; 2 object.x=1;//增加一个变量 3 delete object.x;//删除一个变量 success 4 console.log(Object.keys(object).length); //0
(1) 既然变量的对象类型和个数是可变的,我们也就不能像java,c++那样,先将一个对象分配固定的空间。JS的引用指向的对象所占用的空间必须支持随时调整。基于此,顺序存储的数组已经被淘汰。
(2)链式数组查询较慢的弊端已经先天决定其不可能作为对象中变量的存储结构。
(3)当然你可以说,我可以用树的存储结构,效率较高的可能就是平衡树了。平衡树在查询的时候时间复杂度为log(n),也不算太高,但是当删除属性的时候,平衡树在调整的时候代价相比 于hash表也是很大。或许,你还有其他的选择,但是我敢说,肯定没有任何一种有hash表存储数据那么方便和高效。
(4).只有JavaScript的对象是基于hash表存储的,那么所有的在c++,java,c#中存在的不合理才会在JavaScript语言中变得合理。
其实说白一点,物理存储并非非hash表不可,只是没有比hash表更好的了,所以在JS语言设计的时候就是当做hash表结构进行设计的。
为了证明对象是基于hash表以键值对存储的,我们来简单看一下数组类型和函数:
函数:
var person=function y(){}; person.x=1; person.y=2; for(var property in person){ console.log(property+" : "+ person[property]) }//x:1
// y:2
数组:
var array=[1,2,4] for(var property in array){ console.log(property+" : "+ array[property]) }// 0: 1
// 1: 2
// 2:4
(2).理解了这些有什么用:
1.你还会对数组数可以拥有属性,函数也可以拥有属性奇怪吗? 因为他们本身管理着属于自己的hash表,所以他们随时都可以给自己添加或则删除一些属性。
2.我们知道数组中的下表是可以随意添加的,无论你设置为多大,你也可以越界访问(严格来说,根本就没有所谓的越界),只是返回的结果是undefined...因为没有找到对应的key。
你将其理解为下标,倒不如理解为Key,如此,JS数组还有那么神秘吗? 说白了,也就是一种hash结构。如果你想,你也可以把object当成数组,然后自定义一整套函数,只是可能没有那么方便。
注:当然,函数作为一种对象肯定有其的特殊性。在这里我们就不过多的讨论了。
4.JS对象是基于Hash表的典型应用
数组去重
1 var array=['true',true,false,'1',1,'','sss'," ",1,34,,,{x:1},{x:2}] 2 3 Array.prototype.unique=function(){ 4 5 //利用对象的hash存储特性去重 6 var object={},result=[]; 7 8 for(var i=0,length=this.length;i<length;i++){ 9 10 var temp=this[i],key; 11 12 if((typeof temp)=='object'){ 13 key=JSON.stringify(temp); //若为对象类型,将对象序列化为字符串 14 }else{ 15 key=typeof temp+temp; 16 } 17 18 if(!object[key]){ 19 object[key]=true; //若object中已经存在此键值,则证明此元素在数组中已经存在 20 result.push(temp); 21 22 } 23 24 } 25 26 return result; 27 28 } 29 30 console.log(array.unique());
//此算法的缺点,因为另外建立一个object对象和result数组,所以比较占用空间,但是速度非常快,至少比用树形结构快。这是对网上一些算法的改进,网络上有好多针对对象hash的算法并不能完美的去重。
比如数组[1,"1",{x:1},{x:2}]。
文章中存在的疑点: Number,Boolean 等基本类型在转化为字符串的时候到底调用的是什么方法?(不是原型链中的toString()方法,关于这点未能叙述,欢迎补充);