皮尔森相关系数(Pearson Correlation Coefficient)
先讲几个统计学中一些基本的数学概念:
数学期望就是平均值:
均值公式:

方差:
 或者:
或者:
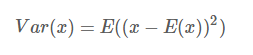
另一种形式:
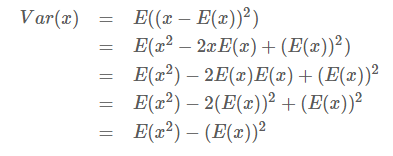
标准差:

标准差与方差不同的是,标准差和变量的计算单位相同,比方差清楚,因此很多时候我们分析的时候更多的使用的是标准差。
均值描述的是样本集合的中间点,它告诉我们的信息是有限的,而标准差给我们描述的是样本集合的各个样本点到均值的距离之平均。
标准差和方差一般是用来描述一维数据的,但现实生活中我们常常会遇到含有多维数据的数据集,最简单的是大家上学时免不了要统计多个学科的考试成绩。面对这样的数据集,我们当然可以按照每一维独立的计算其方差,但是通常我们还想了解更多。
协方差:
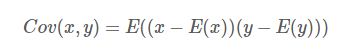
展开:
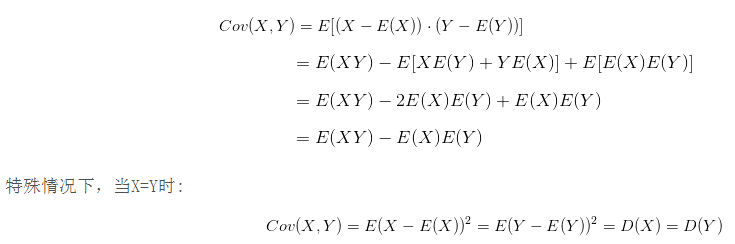
或者:
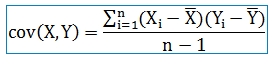
故协方差主要用来度量各个维度偏离其均值的程度。如果结果为正值,则说明两者是正相关的,如果结果为负值, 就说明两者是负相关,如果为0,则两者之间没有关系,互相独立。
协方差也只能处理二维问题,那维数多了自然就需要计算多个协方差,比如n维的数据集就需要计算![clip_image002[16]](http://images0.cnblogs.com/blog/407700/201307/10144508-45b7889a80394aafbb6e9547fd5e8e98.gif "clip_image002[16]") 个协方差,那自然而然我们会想到使用矩阵来组织这些数据。
个协方差,那自然而然我们会想到使用矩阵来组织这些数据。
协方差作为描述X和Y相关程度的量,在同一物理量纲之下有一定的作用,但同样的两个量采用不同的量纲使它们的协方差在数值上表现出很大的差异,于是引出皮尔森相关系数。
皮尔森相关系数
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:
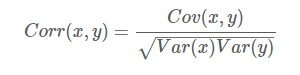
几种常见形式:

由公式可知,Pearson 相关系数是用协方差除以两个变量的标准差得到的,虽然协方差能反映两个随机变量的相关程度(协方差大于0的时候表示两者正相关,小于0的时候表示两者负相关),但其数值上受量纲的影响很大,不能简单地从协方差的数值大小给出变量相关程度的判断。为了消除这种量纲的影响,于是就有了相关系数的概念。
对皮尔森相关系数的通俗解释
对于协方差,可以通俗的理解为:两个变量在变化过程中是同方向变化?还是反方向变化?同向或反向程度如何?
你变大,同时我也变大,说明两个变量是同向变化的,这时协方差就是正的。
你变大,同时我变小,说明两个变量是反向变化的,这时协方差就是负的。
从数值来看,协方差的数值越大,两个变量同向程度也就越大。反之亦然。
咱们从公式出发来理解一下:
公式简单翻译一下是:如果有X,Y两个变量,每个时刻的“X值与其均值之差”乘以“Y值与其均值之差”得到一个乘积,再对这每时刻的乘积求和并求出均值(其实是求“期望”,但就不引申太多新概念了,简单认为就是求均值了)。
下面举个例子来说明吧:
比如有两个变量X,Y,观察t1-t7(7个时刻)他们的变化情况。
简单做了个图:分别用红点和绿点表示X、Y,横轴是时间。可以看到X,Y均围绕各自的均值运动,并且很明显是同向变化的。
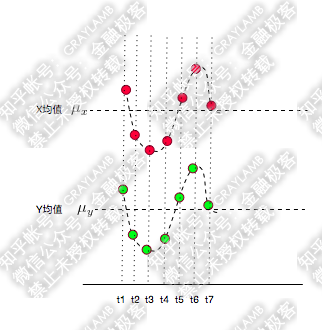
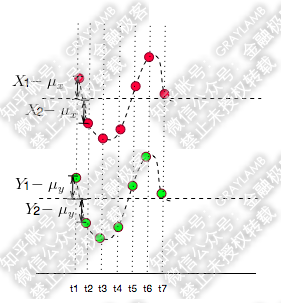
如果反向运动呢?
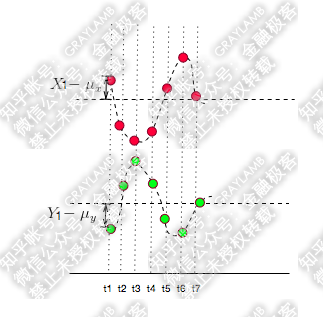
当然上面说的是两种特殊情况,很多时候X,Y的运动是不规律的,比如:
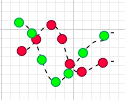
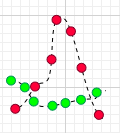
总结一下,如果协方差为正,说明X,Y同向变化,协方差越大说明同向程度越高;如果协方差为负,说明X,Y反向运动,协方差越小说明反向程度越高。
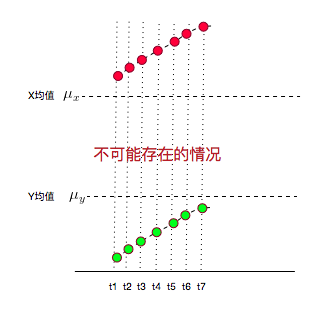
这种情况是有可能出现的,比如:
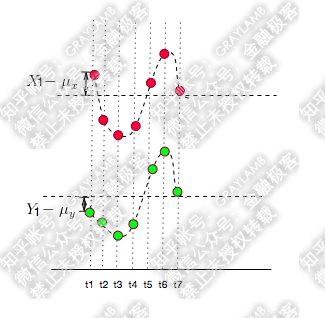
另外,如果你还钻牛角尖,说如果t1,t2,t3……t7时刻X,Y都在增大,而且X都比均值大,Y都比均值小,这种情况协方差不就是负的了?7个负值求平均肯定是负值啊?但是X,Y都是增大的,都是同向变化的,这不就矛盾了?
这个更好解释了:这种情况不可能出现!
因为,你的均值算错了……
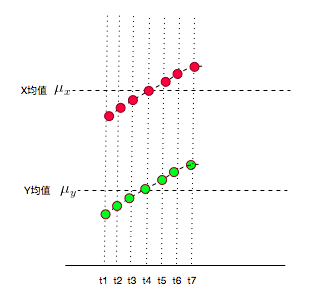
X,Y的值应该均匀的分布在均值两侧才对,不可能都比均值大,或都比均值小。
所以,实际它的图应该是下面这样的:
对于相关系数,我们从它的公式入手。一般情况下,相关系数的公式为:
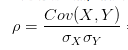
就是用X、Y的协方差除以X的标准差和Y的标准差。
所以,相关系数也可以看成协方差:一种剔除了两个变量量纲影响、标准化后的特殊协方差。
既然是一种特殊的协方差,那它:
1、也可以反映两个变量变化时是同向还是反向,如果同向变化就为正,反向变化就为负。
2、由于它是标准化后的协方差,因此更重要的特性来了:它消除了两个变量变化幅度的影响,而只是单纯反应两个变量每单位变化时的相似程度。
比较抽象,下面还是举个例子来说明:
首先,还是承接上文中的变量X、Y变化的示意图(X为红点,Y为绿点),来看两种情况:
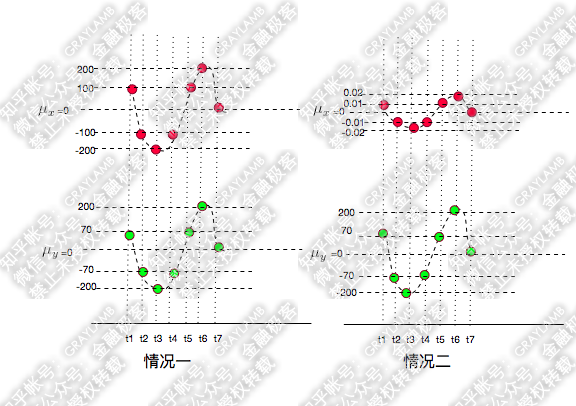
很容易就可以看出以上两种情况X,Y都是同向变化的,而这个“同向变化”,有个非常显著特征:X、Y同向变化的过程,具有极高的相似度!无论第一还是第二种情况下,都是:t1时刻X、Y都大于均值,t2时刻X、Y都变小且小于均值,t3时刻X、Y继续变小且小于均值,t4时刻X、Y变大但仍小于均值,t5时刻X、Y变大且大于均值……
可是,计算一下他们的协方差,
第一种情况下:
协方差差出了一万倍,只能从两个协方差都是正数判断出两种情况下X、Y都是同向变化,但是,一点也看不出两种情况下X、Y的变化都具有相似性这一特点。
这是为什么呢?
因为以上两种情况下,在X、Y两个变量同向变化时,X变化的幅度不同,这样,两种情况的协方差更多的被变量的变化幅度所影响了。
所以,为了能准确的研究两个变量在变化过程中的相似程度,我们就要把变化幅度对协方差的影响,从协方差中剔除掉。于是,相关系数就横空出世了,就有了最开始相关系数的公式:
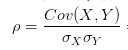
那么为什么要通过除以标准差的方式来剔除变化幅度的影响呢?咱们简单从标准差公式看一下:
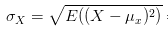
从公式可以看出,标准差计算方法为,每一时刻变量值与变量均值之差再平方,求得一个数值,再将每一时刻这个数值相加后求平均,再开方。
所以标准差描述了变量在整体变化过程中偏离均值的幅度。协方差除以标准差,也就是把协方差中变量变化幅度对协方差的影响剔除掉,这样协方差也就标准化了,它反应的就是两个变量每单位变化时的情况。这也就是相关系数的公式含义了。
总结一下,对于两个变量X、Y,
当他们的相关系数为1时,说明两个变量变化时的正向相似度最大,即,你变大一倍,我也变大一倍;你变小一倍,我也变小一倍。也即是完全正相关(以X、Y为横纵坐标轴,可以画出一条斜率为正数的直线,所以X、Y是线性关系的)。
随着他们相关系数减小,两个变量变化时的相似度也变小,当相关系数为0时,两个变量的变化过程没有任何相似度,也即两个变量无关。
当相关系数继续变小,小于0时,两个变量开始出现反向的相似度,随着相关系数继续变小,反向相似度会逐渐变大。
当相关系数为-1时,说明两个变量变化的反向相似度最大,即,你变大一倍,我变小一倍;你变小一倍,我变大一倍。也即是完全负相关(以X、Y为横纵坐标轴,可以画出一条斜率为负数的直线,所以X、Y也是线性关系的)。
有了上面的背景,我们再回到最初的变量X、Y的例子中,可以先看一下第一种情况的相关系数:
X的标准差为
说明第一种情况下,X的变化与Y的变化具有很高的相似度,而且已经接近完全正相关了,X、Y几乎就是线性变化的。
那第二种情况呢?
X的标准差为
说明第二种情况下,虽然X的变化幅度比第一种情况X的变化幅度小了10000倍,但是丝毫没有改变“X的变化与Y的变化具有很高的相似度”这一结论。同时,由于第一种、第二种情况的相关系数是相等的,因此在这两种情况下,X、Y的变化过程有着同样的相似度。
皮尔森相关系数的主要性质
1、有界性
相关系数的取值范围为-1到1,其可以看成是无量纲的协方差。
2、统计意义
值越接近1,说明两个变量正相关性(线性)越强,越接近-1,说明负相关性越强,当为0时表示两个变量没有相关性。
试用场景
当两个变量的标准差都不为零时,相关系数才有意义,皮尔逊相关系数适用于:
(1)、两个变量之间是线性关系,都是连续数据。
(2)、两个变量的总体是正态分布,或接近正态的单峰分布。
(3)、两个变量的观测值是成对的,每对观测值之间相互独立
注:在时间序列领域的自相关函数ACF是类似的计算公式,可用于ARIMA模型平稳性判定和模型定阶。
根据公式四,python3实现代码:

参考地址,感谢各位作者:
https://www.cnblogs.com/arachis/p/Similarity.html
https://blog.csdn.net/u010670689/article/details/41896399
http://blog.codinglabs.org/articles/basic-statistics-calculate.html
https://blog.csdn.net/qq_29540745/article/details/52132836
http://bbs.pinggu.org/thread-5811958-1-1.html
https://blog.csdn.net/huangfei711/article/details/78456165?utm_source=gold_browser_extension
https://blog.csdn.net/AlexMerer/article/details/74908435
http://blog.sina.com.cn/s/blog_6aa3b1010102xkp5.html