1.python垃圾回收机制
https://zhuanlan.zhihu.com/p/83251959
2.redis过期删除机制 和内存淘汰机制
过期删除方式:
1.定时删除:在 设置过期时间时,新建一个定时器,在过期时间到时 立刻删除;优点:内存友好;缺点:CPU不友好,浪费资源;
2.惰性删除:再次查询时 先判断是否过期,过期则删除; 优点:CPU友好;缺点:内存不友好; 极端情况:某个key的value很大,且过期后 也不再调用,则会一直占用内存
3.定期删除: 隔断时间 从所有db中 随机抽取部分数据 检查是否过期,并删除; 注意不是 全部所有key都检查; 缺点:因为是随机删除,所以可能出现 极端情况某个key就是没找到,而其占有内存还很大;
redis综合上面几种过期删除方式;最终 使用 惰性删除+定期删除 组合的方式 达到 cpu和内存的一个合理的平衡;
内存淘汰机制:
在内存耗尽时, 可能需要淘汰旧数据 为 新数据腾出空间;
1)volatile-lru 利用LRU算法移除设置过过期时间的key (LRU:最近使用 Least Recently Used ) 。
2)allkeys-lru 利用LRU算法移除任何key (和上一个相比,删除的key包括设置过期时间和不设置过期时间的)。通常使用该方式。
3)volatile-random 移除设置过过期时间的随机key 。
4)allkeys-random 无差别的随机移除。
5)volatile-ttl 移除即将过期的key(minor TTL)
6)noeviction 不移除任何key,只是返回一个写错误 ,默认选项,一般不会选用。
https://www.cnblogs.com/ysocean/p/12422635.html
3.python实例化对象查找属性的顺序
4.python装饰器的使用,及如何改变函数名
5.python命名空间
6.python GIL锁问题
GIL(全局解释器锁) 只针对 Cpython解释器而已,和 Python语言本身无关;
当 进程内的多线程方式运行时, 为了线程级别的数据安全,减少程序员的压力, 所以同一时间只能有一个线程 获取权限 执行操作; 其实是历史遗留问题;
解决方法:
1.使用 Jython解释器;
2.使用多进程
https://www.cnblogs.com/zipxzf/p/11621630.html
7.python编译和java编译区别
8.epoll原理
https://zhuanlan.zhihu.com/p/64746509
https://blog.csdn.net/historyasamirror/article/details/5778378
https://blog.csdn.net/helloxiaozhe/article/details/78104975
9.mysql B- Tree,B+ Tree各自特点,及为何使用B+Tree作为默认索引,聚簇索引,MyIsam,Innodb索引的区别等
先讲B Tree 相对于普通二叉树区别:
假设有4个元素,用变量X表示;
二叉树 一个节点至多只能挂2个子节点,查询复杂度最坏情况为 log2(X); 当X=4时,函数值为2;也就是查询深度为2
B Tree 一个个节点可以挂多个子节点(假设挂4个子节点),查询复杂度最坏情况为 log4(X);当X=4时,函数值为1;也就是查询深度为1;
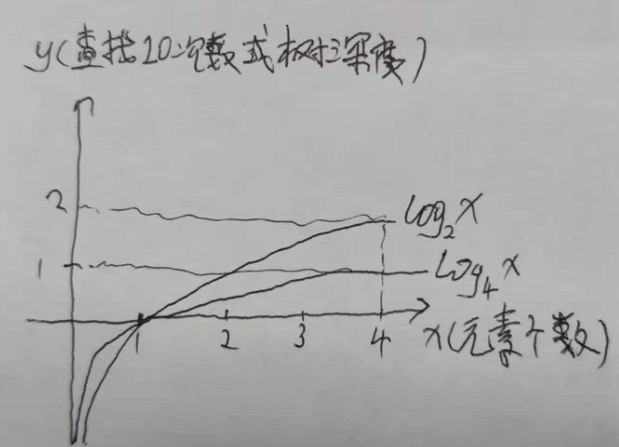
而数据库 取数据压力或瓶颈在于磁盘IO次数;因此 能够减少磁盘IO次数越多的算法越好;
B- Tree:
存储特点: 树上的所有节点 都存储者 key及对应数据(如果是innodb中聚簇索引 则存一行数据,如果是innodb中普通索引 则存 对应主键索引的key);
因为这个特点 所以查询效率在 O(1)到 O(logN)之间; 且因为每个节点都包含具体数据,所以每个节点能保存的 最大元素个数比 B+ Tree少很多; 如 一个节点存1K数据,B-Tree 一个元素(key+数据)有0.2K,则一个节点只能存 5个元素;则log底就是5;
B+ Tree:
存储特点:树上的 非叶子节点 只存储key数据; 只有叶子节点才存 具体数据;且以链表的方式将所有叶子节点连接起来;
因为这个特点 所以查询效率 只能是 O(logN),因为必须去根节点查询数据; 但是 因为非叶子节点 只存储key数据,所以非叶子节点能存储的元素个数比 B-Tree多很多;如 一个节点存1K数据,B+Tree非叶子节点key只有0.1K,则能存储10个元素;则log底就是10;则其树深度就比B-Tree少很多; 则 在一定情况下 IO次数比 B-Tree少很多;
B树包含数据的节点的数据结构如下图: 没有包含数据的节点 则把图中的 data去掉即可;
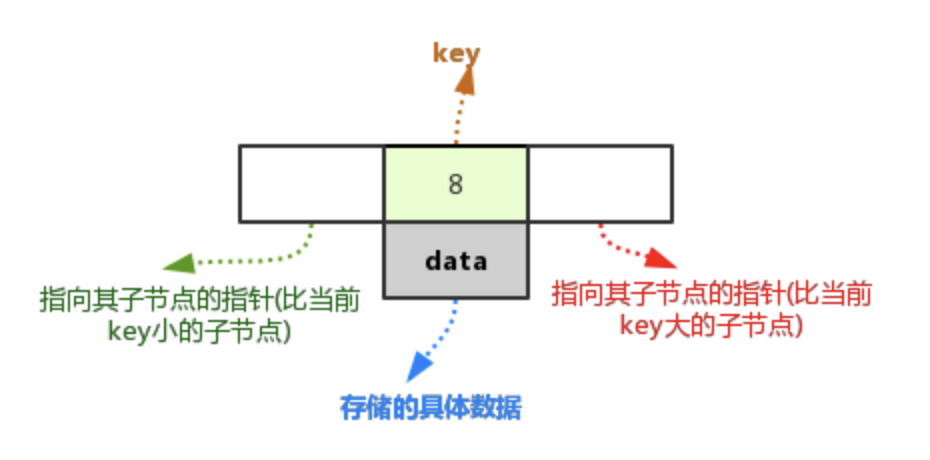
节点的key,相当于索引;
节点的data,具体存储的数据;
节点的前指针,指向比当前key小的子节点;
节点的后指针,指向比当前key大的子节点
聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据;所以Innodb的主键索引是 聚簇索引;
非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置;所以 MyISAM是 非聚簇索引;
在innodb存储引擎中主键索引(聚簇索引)和普通索引(或者叫辅助索引:除了主键索引以外的都是辅助索引) 在 B树的区别
因为此引擎 索引文件和数据文件在同一个文件
主键索引:
节点的 key对应的Data存的是 一行数据;
普通索引(辅助索引):
节点的key对应的Data存的是 主键值; 所以使用普通索引时,要先找到普通索引对应的 Data,从里面拿到 主键值,然后再去主键索引里找真实的数据;
这种 普通索引的好处是 当行数据发送移动或页移动时,因为指向的 主键索引的key不变,所有 这时 普通索引树不用做任何修改;
在MyISAM存储引擎中
因为此引擎 索引文件和数据文件不在同一个文件中
主键索引:
节点的 key对应的Data存的是 指向具体数据的指针;而不是存具体的一行数据;
普通索引:
节点的 key对应的Data存的是 指向具体数据的指针;而不是指向 主键的索引;
https://blog.csdn.net/a519640026/article/details/106940115/
https://blog.csdn.net/weixin_39992660/article/details/113000277
https://my.oschina.net/xiaoyoung/blog/3046779
10.为何使用主键自增
在Innodb的聚簇索引中,由于索引和数据是存储在一起的,所以 索引按照顺序排序,数据当然也是按照顺序存放在 物理空间中的; 当使用主键自增时,新的索引及数据 只需放在索引树的尾部添加即可;这样对 索引树的 修改,从新排序 等影响最小;
如果不是主键自增,而是 随机数,那么 在每次新增数据时 对 索引树的修改变动范围较大,复杂度增加,造成不必要的资源浪费; 需要 不断的分页等等,造成磁盘碎片化高等情况;
且 主键尽量使用int类型,且最好从1开始,如果直接从 1千万开始,则 辅助索引中保存的主键ID的值也会很大,造成不必要的浪费; 且 主键索引中 的索引值较大,造成一页数据中 能保存的行数下降;
https://my.oschina.net/xiaoyoung/blog/3046779
11.flask cookie,session用法区别,前端token存在什么地方;
cookie存储在客户端; 数据不安全,任何人通过浏览器都能看到内容;不能存储敏感数据
session存储在服务端; 相对cookie安全些;
flask中默认是 将session的数据 通过加密后 放到 客户端的cookie中; 然后下个请求 带着cookie中的 session 交给服务端;
目前 token在前端存储在 session storage中; 向后端查询数据时 将token放在请求头中;
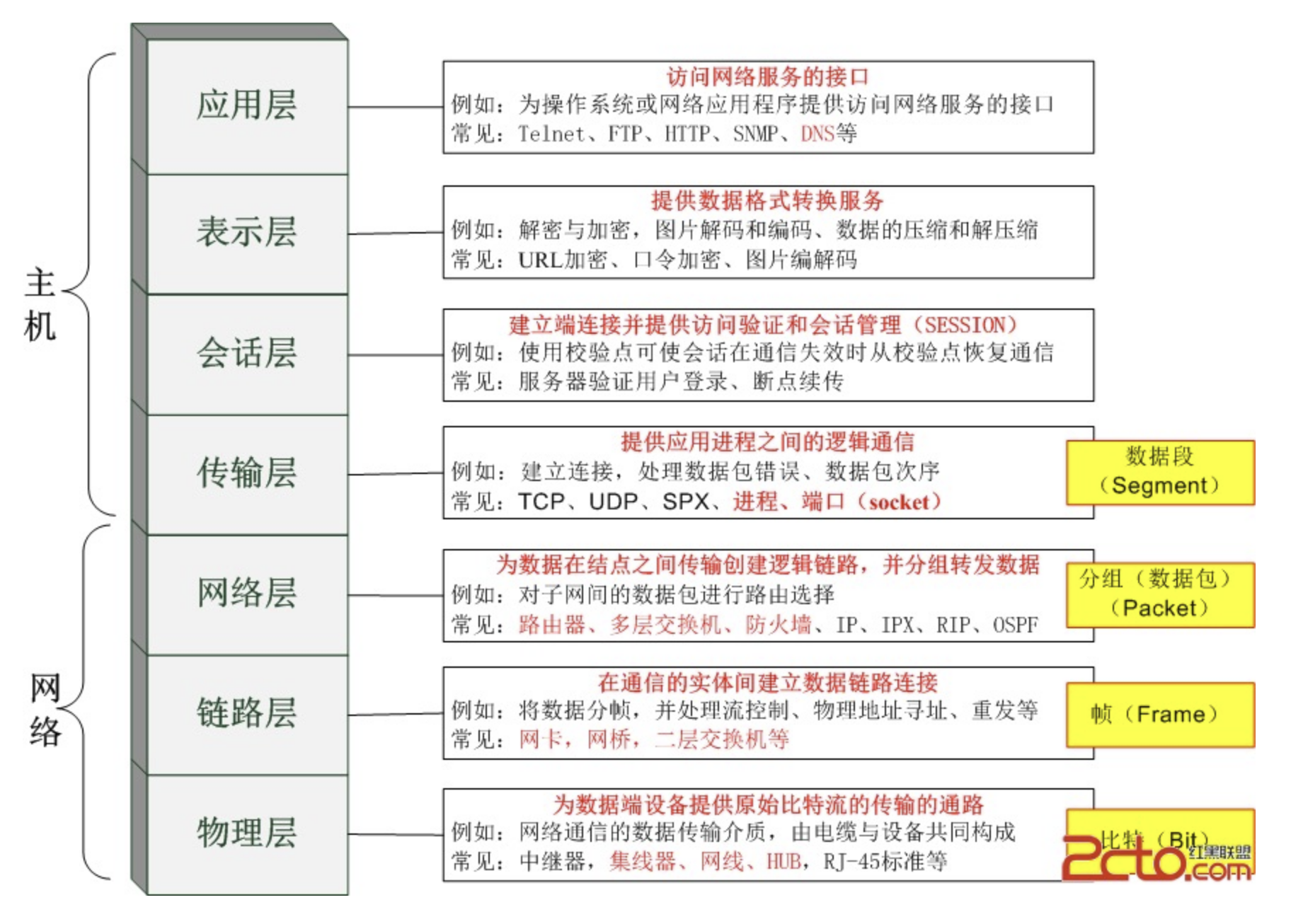
12.网络七层模型 及 路由器,交换机 ;tcp/ip协议,http协议,所在层次;
13.rabbitmq保证消息重复消费,消息丢失等
.消息重复消费: 数据库层unique字段/或业务层逻辑 等保证消息幂等性;
https://blog.haohtml.com/archives/19165
https://zhuanlan.zhihu.com/p/281912931
14.python dict 为何 list无法做为key;
python dict 其实是通过 hash算法 将 key 计算成hash值,并存储; 当 不同key的hash值相同(冲突时),会找下一个位置作为存储;
dict的key可以使用 str,float,int,tuple等类型; 但是不能使用 list;因为list是可变对象,当list内部数据变化时,即使通过hash算法也找不到 dict中key的位置;所以不能用list作为key
https://zhuanlan.zhihu.com/p/74003719
15.redis 去重
set 或 HyperLoglog
16. http 请求 content_type json类型和文件类型 对应的字段;
17. python list实现原理
tuple和list都是 基于 顺序表数据结构:
开辟一块连续的内存空间; append/pop时 O(1); insert时 O(n); remove时 O(n);
1.元素有位置下标,以索引就可以直接取到元素 --> 连续的存储空间,以偏移量计算取得元素,不必遍历所有元素
2.元素无论如何改变,表对象不变,也就是其id不变 --> 分离式结构,表头和元素内容分开储存,这样在更改list时,表对象始终是同一个,只是其指向的地址不同
3.元素可以是任意类型 --> 既要要求是连续存储,又可以存储不同类型的数据,那么其用的就是元素外置的方式,存储的只是地址的引用
4.可以任意添加新元素 --> 要能不断地添加新元素,其使用了动态扩充的策略
https://zhuanlan.zhihu.com/p/143223943?utm_source=wechat_session
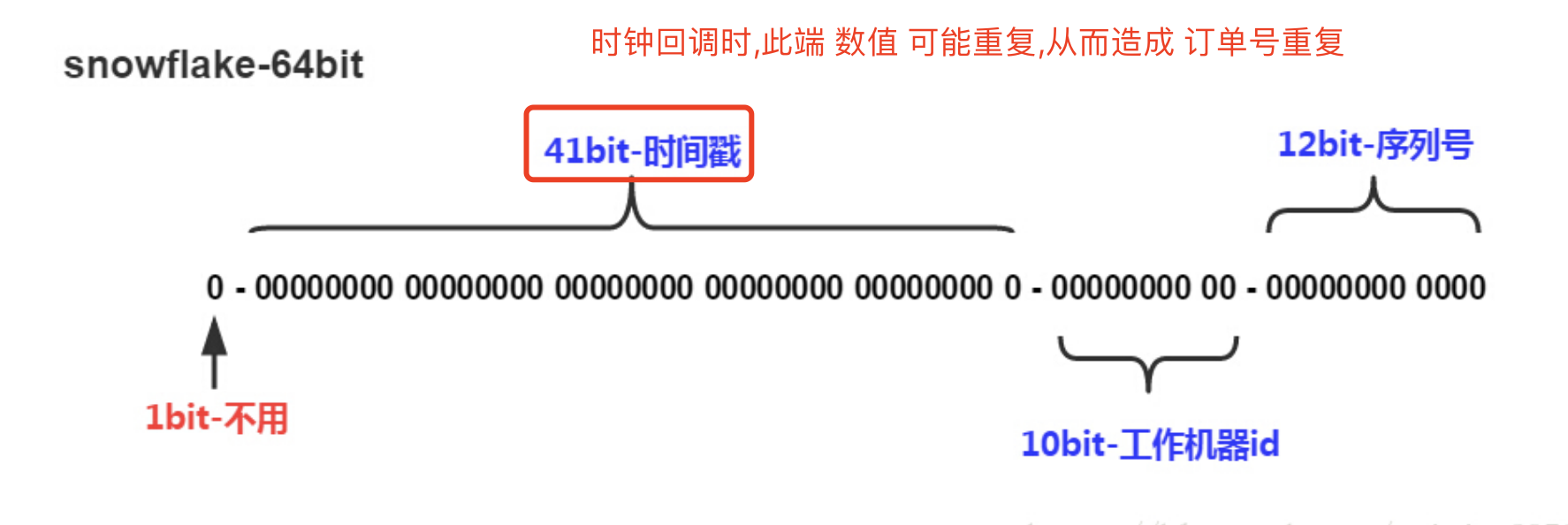
20.雪花(snowflake)算法
https://blog.csdn.net/weixin_39767528/article/details/82595841
用在分布式系统中生成全局唯一自增的ID;主要用在生成订单号等等;
大致思路为 在 毫秒 + 不同机器ID 情况下生成唯一的ID;
需要防止 当 时钟 回调时,可能出现订单号重复,因为 时间字段 和历史重复了;所以 生成的ID 需要和 上一个ID 进行比较;如果小于上一个ID 则表明 时钟回调;报异常;或 使用美团的leaf-snowFlake