叉积:
在平面中我们为了度量一条直线的倾斜状态,为引入倾斜角这个概念。而通过在直角坐标系中建立tan α = k,我们实现了将几何关系和代数关系的衔接,这其实也是用计算机解决几何问题的一个核心,计算机做的是数值运算,因此你需要做的就是把几何关系用代数关系表达出来。而在空间中,为了表示一个平面相对空间直角坐标系的倾斜程度,我们利用一个垂直该平面的法向量来度量(因为这转化成了描述直线倾斜程度的问题)。
定义:
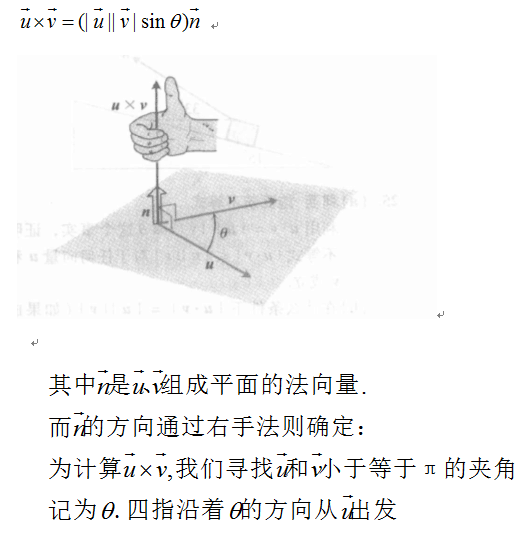
而向量的运算符合如下的代数定律.

显然这个定义式我们不怎么喜欢,因为它代数化程度还是太浅,主要就是由于角的正弦值我们不好找,但是这丝毫不影响这个定义式在应用当中的重要性,下面我们需要解决的问题就是,找到一个等价的代数化程度更高的定义式。
叉积的行列式公式:

①式子是叉乘得到的法向量的模长,由于在右手法则中的规定θ≤π,所以①两边一定是大于等于零的。但是现在我们做一些了不起的事情,通过基本定义和我们通过右手定则判定法向量的方向,将θ的范围限定在sinθ∈[0,1]的范围内,加入我们规定法向量的方向只有一个,我们就可以将向量的位置关系转移到模长的代数关系当中去。

而我们在计算几何学当中,往往不再去考察法向量,仅仅在二维平面中利用叉乘系数的代数关系,我们可以得到下面非常重要的结论:

判断线段相交:
通过上文叉积的引入,我们就可以利用它的性质涉及各种各样的算法,其中判断线段相交就是其中一个。
为了用到叉积的优良性质,这里需要从“跨立”的角度去理解线段相交。即一般情形下,两条线段相交,一条线段(segment_1)的两个端点是横跨在另一条线段(segment_2)所在直线的两侧的,同样也要满足另一条线段(segment_2)的两个端点横跨在前面线段(segment_1)所在直线的两侧。
而描述“横跨”这个几何位置的概念,就可以叉积了。
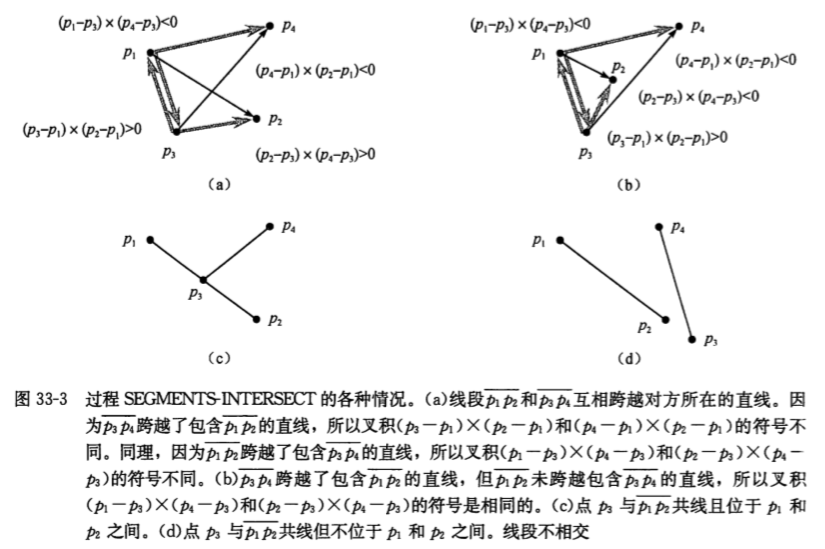
而对于一些比较特殊的情况,比如某一条线段上的点落在另外一条线段所在直线,需要特判一下,我们能够得到下述的伪代码形式:
SEGMENTS-INTERSECT(p1 , p2 , p3 , p4)//判断线段p1p2,p3p4是否相交.
d1 = DIRECTION(p3 , p4 , p1) ;
d2 = DIRECTION(p3 , p4 , p2) ;
d3 = DIRECTION(p1 , p2 , p3) ;
d4 = DIRECTION(p1 , p2 , p4) ;
if((d1 > 0 and d2 < 0 or d1 < 0 and d2>0) and ((d3 > 0 and d4 < 0 or d4 < 0 and d3>0))) return true;
else if(d1 = 0) and ON-SEGMENT(p3 , p4 , p1)
return true;
else if(d2 = 0) and ON-SEGMENT(p3 , p4 , p2)
return true;
else if(d3 = 0) and ON-SEGMENT(p1 , p2 , p3)
return true;
else if(d4 = 0) and ON-SEGMENT(p1 , p2 , p4)
return true;
else
return false;
DIRECTION(pi , pj , pk)//向量pkpi叉乘向量pjpi.
return (pk - pi)×(pj - pi).
ON-SEGMENT(pi , pj , pk)//判断点pk是否在线段pipj上.
if(min(xi , xj)≤xk≤max(xi , xj) and min(yi , yj)≤yk≤max(yi , yj))
return true
else
return false;
下面给出了几种线段相交的情形,以便于理解整个算法流程。
寻找凸包:
求一个点集V的凸包是计算几何中常见而且基本的算法,基于凸包寻找最近点对也将为时间复杂度上带来优化。
寻找凸包的算法整体上有Graham扫描法(Graham’s scan)以及Jarvis步进法(Jarvis march),他们都利用的叉积的性质,使用了一种称为“旋转扫除”的技术。
而构造凸包还有下面几个其他方法:
- 增量法:首先从左到右进行排序,得到点集V={v1 , v2 , …,vn}.然后构造凸包P(3)={v1,v2,v3},然后依次向后扫描,每次添加第i个点,并更新P(i-1),得到一个新的凸包P(i),扫描到点集中第n个点的时候,便完成了凸包的构造。
- 分治法:将点集一分为二,然后对子集进行递归的凸包运算
- 剪枝-搜索方法:在构造过程中,类似第九章的最坏情况下限行时间算法,它会进行两遍构造,分别完成凸包上链和下链的构造。
上面描述的方法非常的概括笼统,对于初学者来说会显得一头雾水,下面我们开始对逐个的分析算法步骤、正确性分析以及时间复杂度.
一般寻找构造凸包的算法,都是Graham扫描法/Jarvis步进法和下面的增量/剪枝-搜索/分治的方法结合起来,而不同的组合方法,往往依赖于不同的排序方式(水平序,极角序)。
基本Graham扫描法:
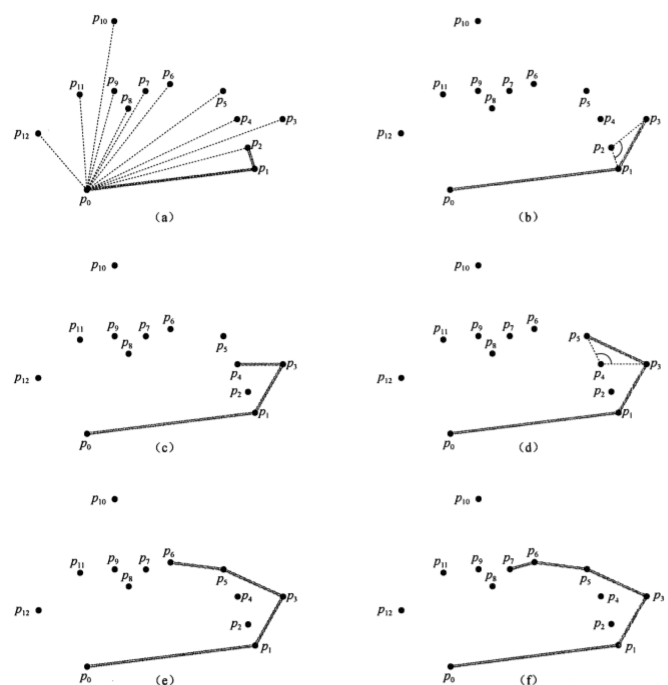
这种方法基于极角序,用一个栈S结构来储存凸包点集V1,然后更新到第i个点时,拿到当前栈顶的两个元素S[top] , S[top - 1],利用叉积考察这两个点和P[i]的相对位置(这就是前面我们所说的“旋转扫除”技术),更新凸包点集V1,下面呈现出这个算法的伪代码:
GRAHAM-SCAN(P)
let p0 be the point in P the minimum y-coordinate,
or the leftmost such point in case of a tie
let<p1 , p2 , ..., pn> be th remaining points in P ,
sorted by polar angle in counterclockwise order around p0
(if more tan one point has the same angle , remove all but
the on that is farthest from p0)
if m < 2
return "convex hull is empty"
else let S be an empty stack
PUSH(p0 , S)
PUSH(p1 , S)
PUSH(P2 , S)
for i = 3 to m
while the angle formed by points NEXT-TO-TOP(S) , TOP(S),pi
makes a nonleft turn
POP(S)
PUSH(pi , S)
return S
下面我们给出一个基本Graham扫描法的模拟过程:
寻找最近点对:
在交通控制等系统中,为检测出潜在的碰撞事故,在空中或者海洋交通系统中,需要识别两个距离最近的交通工具,抽象出来,最近点对就是给定点集P,找到相距最近的两个点。
朴素枚举的时间复杂度是O(n^2),这里我们介绍的分治算法能够将时间复杂度降到O(nlgn).
分治策略:
分解:找到一条垂直线L(在笛卡尔系中,x=a),它把点集P分为两个点集PL,PR.使得|PL| = |PR|并且PL、PR中所有的点都分布在垂线l的左侧和右侧。然后得到PL集合按照x、y坐标升序排列的辅助数组XL,YL,得到PR集合按照x、y坐标升序排列的辅助数组XR,YR.
对于每次递归进来,我们都需要按照x升序的数组P,因为只有这样我们才能确定垂直线L。这就是为什么分解问题的时候需要得到XL,XR,这是为了下面的递归过程准备按x升序排列的点集参数。而点集YL,YR有什么用处呢?在后面分析算法中另外一个辅助数组Y’我们就能够看到它们的用处。
解决:拿到PL,PR后,递归调用上面的以后我们已经构造好的寻找最近点对的算法,第一次调用的点集参数是PL,第二次调用的点集参数是PR.
合并:假设在上一步中,我们返回了两个值: δ1 , δ2分别代表分治后两个子问题的解集,δ = min(δ1 , δ2)和可能是当前问题的答案。为了确保答案正确,我们必须将那些没有遍历到的情况给考虑进来。能够看到,如果存在更优化的结果,则对应的两个点必然分布在以L为对称轴的δ * 2δ的矩形区域内,而容易看到,如果我们将P集合中分布在该区域的点放到按y坐标升序的Y ’中,则如果存在更优点对(pi,pj),那么j-i必然在[1,7],依据这条结论,我们将合并过程中的补充枚举过程的时间复杂度降低到O(n).
而为什么Y’中的更优点对的下标距离必然小于等于7呢?原理其实很简单,参考下面的图。
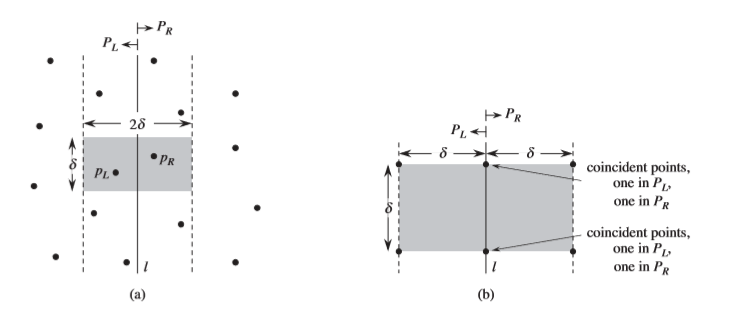
下面的问题是,我们如何构造Y’呢?我们基于进入递归调用中的点集X,得到的垂线L = a,为了构造Y’,我们基于点集P按y升序排列的集合Y,O(n)复杂度的情况下,通过判断横坐标是否在(a –δ,a+δ)范围内,便可以找到阴影区域中按照y排序的点集Y’.
总结起来,每次递归调用,我们需要点集X,Y,分治后需要找到对应子问题的点集参数XL,YL,XR,YR,而构造这些数组的时间复杂度都是O(n)的。
下面我们对这个算法进行时间复杂度的分析:
根据先前介绍过的主定理,T(n) = O(nlogn).
对于初始状态给出的无序的点集P,我们用O(nlogn)对其按x、y进行排序,之后的子问题就不再需要排序过程,利用O(n)的时间复杂度将X,Y数组折半即可得到XR,XL,YR,YL.
T’(n) = T(n) + O(nlogn)
对于初始状态给出的无序点集P,整个寻找最短点对的算法时间复杂度T’(n) = O(nlogn).