整个互联网的流量中,真人占比有多少?
80% ? 60% ? 50% ?
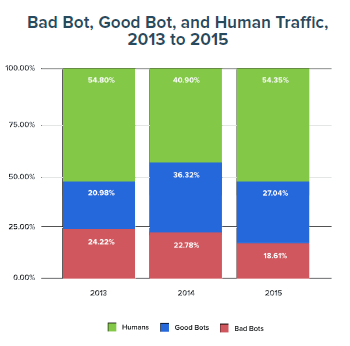
根据 Aberdeen Group 在近期发布的以北美几百家公司数据为样本的爬虫调查报告显示,2015 年网站流量中的真人访问仅为总流量的 54.4% ,剩余的流量由 27% 的好爬虫和 18.6% 的恶意爬虫构成。
爬与反爬的斗争从未间断
恶意爬虫占比数据与 2013 年和 2014 年相比有所下降,同时真人访问的占比也有所提升,但这并不意味着恶意爬虫日渐式微。一个原因是印度、印度尼西亚等高人口总数国家的互联网新增人口有大幅提升,另一方面,恶意爬虫制造者更专注于爬虫的质量而不是数量,如今的恶意爬虫具有高持续性和可变性。
爬与反爬的斗争从未间断。过去的初级爬虫能很明显从异常的 Headers 信息甄别,但爬虫制造者从一次次爬与反爬中总结出可能被封的原因,通过不断的测试和改善爬虫程序,更新换代后的高持续性恶意爬虫通常具有以下特点中的某几个:
-
模仿真人行为
-
加载 Javascript 和外部资源
-
模拟 cookie 和 useragent
-
浏览器自动化操作
-
变化的 IP 地址池
可能很多人认为,恶意爬虫只会威胁到少数以文本为核心价值的网站,其实这些能改变自己请求路径和请求方式的伪装者可能潜伏在任何一个网站的每一个角落,文本、图片、价格、评论、接口、架构等方方面面均有可能成为爬虫的囊中物。
纵容爬虫的危害你必须知道
从网站业务安全的角度,纵容这些伪装者的危害有以下几点:
1. 核心文本被爬
网站的核心文本可能在几小时甚至几分钟内就被恶意爬虫抓取并悄无声息的复制到别的网站。核心内容被复制会极大影响网站和网页本身在搜索引擎上的排名,低排名会导致访问量降低和销量、广告收益降低的恶性循环。
在内容为王、用户粘性不高的今天,核心内容很大程度上会影响网站在用户心目中的价值。若网站以文本为商品作为盈利点,那恶意爬虫更是影响 KPI 的罪魁祸首。
2. 注册用户被扫描
如果在网站的注册页面输入一个已注册过的号码,通常会看到“该用户已注册”的提示,这一信息也会在请求的 response 中显示,一些网站的短信接口也有类似逻辑,注册用户和非注册用户返回的字段和枚举值会有不同。利用这一业务逻辑,恶意爬虫通过各类社工库拿到一批手机号后可以在短时内验证这批号码是否为某一网站的注册用户。
这个数据有什么利用价值?除了很明显的违法欺诈外,攻击者可以将数据打包出售给竞争对手或感兴趣的数据营销公司,完善他们的精准营销数据。
3. 其他危害
-
点击欺诈:点击欺诈会给网站造成实实在在的利益损失。投放广告通常是为了触达符合网站定位的潜在消费者,爬虫造成的点击欺诈使得广告的点击率虚高,使得网站承担了本不应承担的点击费用。从运营角度出发,访问量无原因的忽高忽高也不利于分析广告投放效果。
-
网站带宽负担:对于带宽有限的中小型网站,爬虫可能会降低网页加载速度,影响真实用户的访问体验。
事前的甄别预防才是关键
恶意爬虫在给网站带来可观访问量的同时,也带来了难以估量的威胁和损失。
从实际案例中我们可以看到,恶意爬虫已经承担了整个攻击环节先锋者的重任,所以在分析网站的业务安全风险时,我们可以更多的关注流量和用户行为的异常点,尽可能的在恶意行为刚发生时就及时甄别并做出合理的判断和拦截,必要时,宜采用专业的风险情报系统和数据分析平台进行系统的部署。对于企业来说,事前预防远比事后补救重要。
作者简介
rianley cheng 爬虫爱好者
3年互联网开发经验,对爬虫有着一定的了解!曾经也组织编写过高可用爬虫!