博主最近转战语音增强研究,刚学习了最基础也是最成熟的方法——谱减法,最早是boll提出的《Suppression of acousic noise in speech using spectral subtraction》。http://blog.csdn.net/leixiaohua1020/article/details/47276353 链接中的这边博客给我帮助很大,比较详细,matlab源码也可以找到,对于刚入门音频处理的小白来讲,先从这边文献《Enhencement OF Speech Corrupted by Aconstic Noise》开始是不错的选择,要讲的源码也是对应这篇文献的。
一、原理
顾名思义,谱减法,就是用带噪信号的频谱减去噪声信号的频谱。谱减法基于一个简单的假设:假设语音中的噪声只有加性噪声,只要将带噪语音谱减去噪声谱,就可以得到纯净语音,这么做的前提是噪声信号是平稳的或者缓慢变化的。提出这个假设就是基于短时谱(25ms),就是频谱在短时间内是平稳不变的。
早期文献中的方法较为简单粗暴,公式如下:
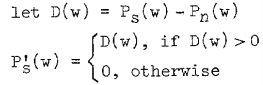
Ps(w)是输入的带噪语音的频谱,Pn(w)是估计出的噪音的频谱,两者相减得到D(w)差值频谱。由于相减后可能会出现负值,所以就简单粗暴地加上一个判断条件,将负值全部置为0,这样得到的结果作为最终输出去噪语音的频谱。
那噪音是怎么估计出来的呢?文献中一般都假设输入的一段语音中前n帧作为silence时间,也就是说这段时间没有语音输入,只有噪音,可以称之为底噪,将这5帧中的噪音强度取平均值,作为估计出来的噪音。
但是这样做的方法有一个缺点就是由于我们估计噪音的时候取得平均值,那么有的地方噪音强度大于平均值的时候,相减后会有残留的噪音存在。在噪音波形谱上表现为一个一个的小尖峰,我们将这种残存的噪声称之为音乐噪声(music noise)。更为专业点的解释如下:

为了改善这种情况,许多人都对传统的谱减法进行了改进,今天主要说的是 Berouti的改进方法,上个世纪的论文了《Enhencement OF Speech Corrupted by Aconstic Noise》。该方法将上面的公式进行了如下修改:
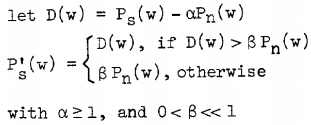
可见多了两个参数alpha 和 beta。我们将alpha称之为相减因子,beta称之为频谱下限阈值参数。alpha>1,这样可以保证相比于之前的方法能够有更强的去噪效果,能够去除大部分的噪声,这样残余的噪声就会少很多。但是同样的相减后差值如果为负值,这个负值也就会更大。老方法中是将负值直接设为0,这样残余噪音的峰值和0之间的差值还是较为显著,所以Berouti就想了一个办法,就是设置一个语音的下限值beta* Pn(w)。将相减后的幅值小于此下限值得统一设置为这个固定值,这个下限值其实也是宽带的噪音,只不过设置下限值的好处是残余峰值相比之下没有那么显著,从而减小了“音乐噪声”的影响。可以通过调整beta的值来调整这个宽带的噪声的强度。
好了基本的原理就是这个了,接下来就是参数的设置,文献中根据输入信号的SNR做了大量实现来确定alpha和beta的值,最终给出的alpha随每一个音频帧的SNR的变换曲线是这样的:
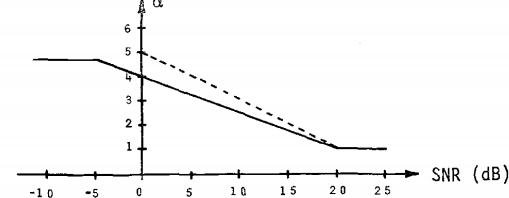
也就是alpha的不能为一个固定值,需要根据每一个音频帧的信噪比大小来确定合适的值。计算alpha的公式如下,其中1/s为斜率,alpha0位期望的SNR为0时的值:
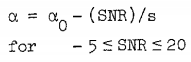
好了,alpha得值已经确定,beta的值文献中也给出了详细的说明,我就不赘述了。

至于还有其他的参数,比如说frameSize, windowOverlap, DFT order等直接去看原文献就可以。
二 、实现
下面说一下算法的代码流程(matlab实现,分步代码,完整代码请参见文章开始的链接)
1.读入语音数据,matlab有现成的函数,waveread()和audioread()都可以,不过waveread()函数将来会被移除。分通道进行处理。

2.设置好frameSize,windowOverlap,shift等参数

3.因为要对语音进行分帧处理,所以需要生成汉明窗hamming window,并且取前5帧估计噪声。

4. 根据公式求出每一帧的去噪后的幅值sub_speech。

5.更新噪声的估计
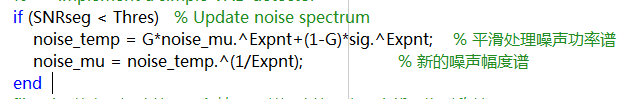
6.从频域转换为时域,相位信息还是采用输入信号的相位。

7. 输出最终去噪后的语音

有空再把图贴上,如有理解错误的,请指正,谢谢。
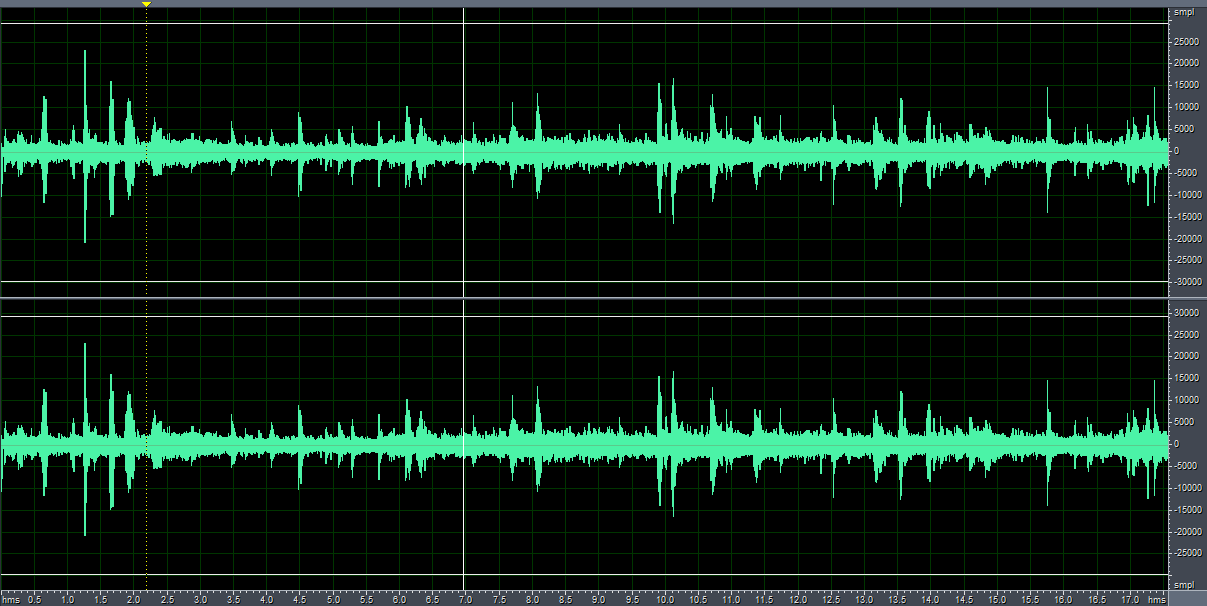
贴图如下:
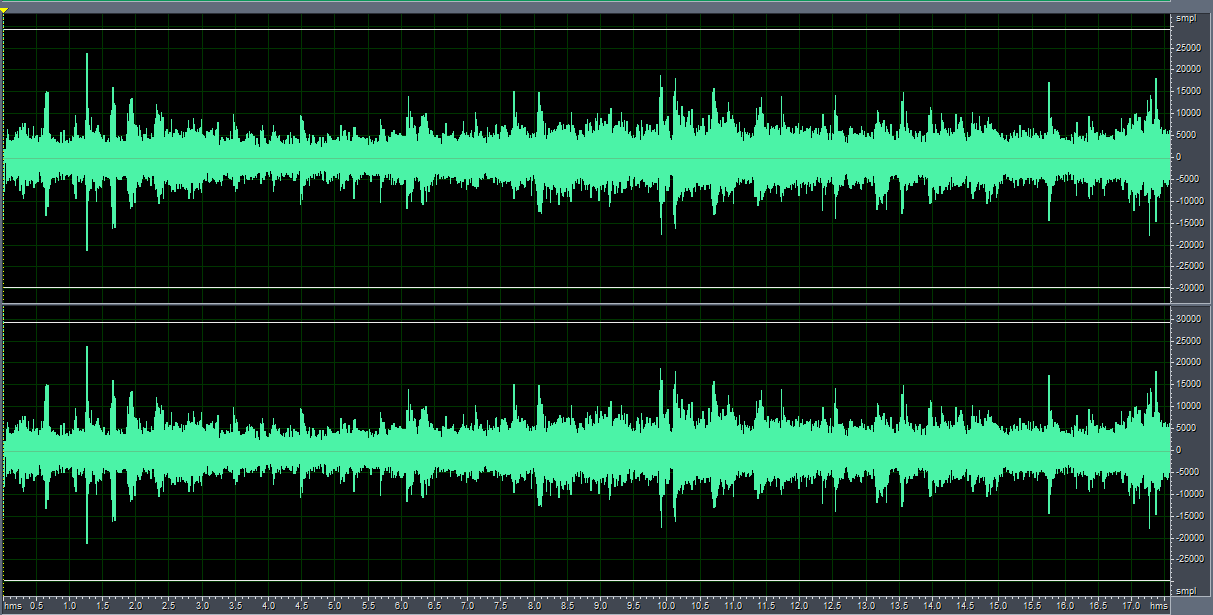
带噪语音波形图
利用过减技术的谱减法去除噪音后的波形图,beta值不同,得到的宽带噪音和”音乐噪音“的比例也不同。
(1)beta=0.005,宽带噪音基本上被完全去除,但是“音乐噪声"很明显。
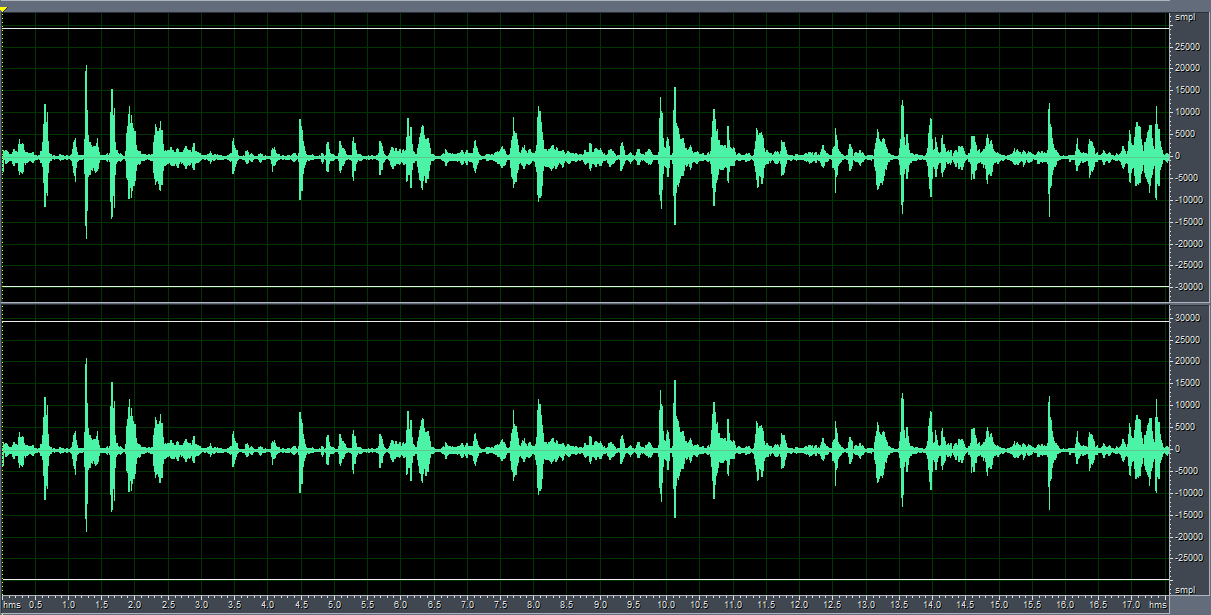
(2)beta=0.01, 既含有宽带噪音,也含有部分”音乐噪声“
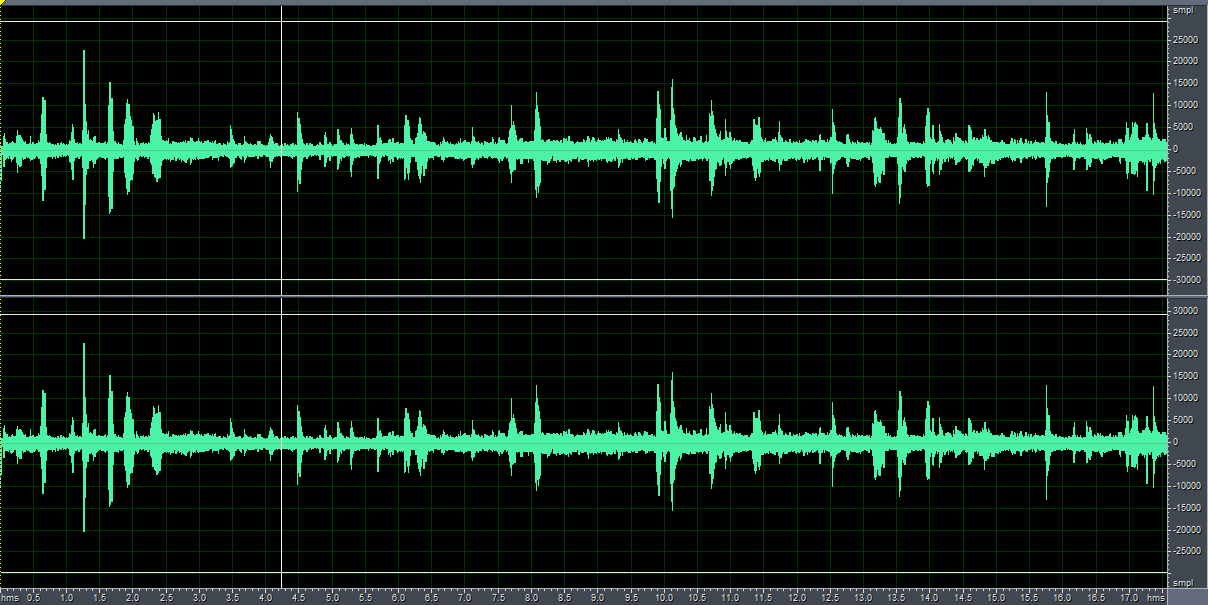
(3)beta=0.05,含有大量宽带噪音,去噪效果不明显,但是几乎没有”音乐噪音“