在爬取某站时并做简单分析时,遇到如下问题和大家分享,避免犯错:
一丶网站的path为 /info/1013/13930.htm ,其中13930为不同新闻的 ID 值,但是这个数虽然为升序,但是没有任何规律的升序。
解决办法:
使用 range 顺序爬取,错误的网站在页面会报如图错误:
这时我们首先去判断返回页面是否包含 str 'Sorry, Page Not Found',如果包含则跳过,不包含则爬取页面关键信息

二、在爬取过程中发现有其它页面,该内容已经被撤销,这时我正常去判断页面,并跳过,发现无法跳过
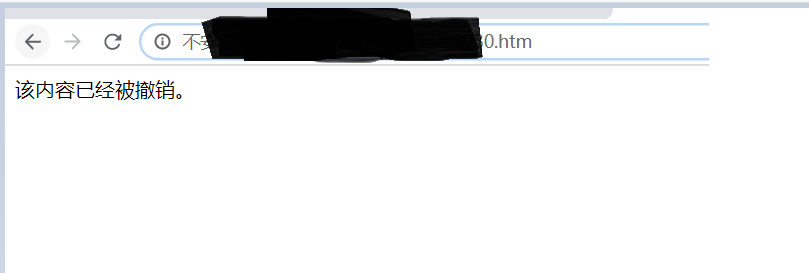

解决办法:
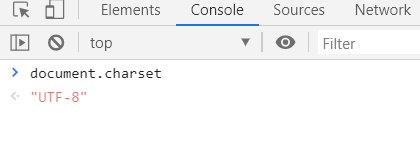
查看页面编码为:UTF-8
在用 if 判断页面是否存在 str 时,首先将页面内容进行UTF-8编码即可解决:
response.encoding = 'utf-8'
三、在爬取网站时,遇到了没有 text 的主页面,新闻全部为图片
解决办法:这时查看图片页面和新闻页面的不同
图片页面关键标签:

新闻页面关键标签:

发现div标签下的 ID 不同,这时我们就跳过 id = 'vsb_content' 即可,在跳过时,判断页面内容应当先判断 id = 'vsb_content_4' ,因为 vsb_content_4 包含了 vsb_content
四、在爬取新闻后,将新闻写入csv文件时出现BUG,文件内容有重复
解决办法:
在写入文件的列表写入后将列表清空,因为在循环执行跳过不存在页面时会有空隙,这时的data_list里面是有内容的
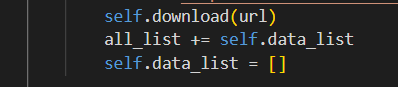
五、在写入csv文件后,新闻文本乱码
解决办法:使用utf-8-sig编码
为什么不用utf-8?
原因如下:
1、”utf-8“ 是以字节为编码单元,它的字节顺序在所有系统中都是一样的,没有字节序问题,
因此它不需要BOM,所以当用"utf-8"编码方式读取带有BOM的文件时,它会把BOM当做是文件内容来处理, 也就会发生类似上边的错误.
2、“uft-8-sig"中sig全拼为 signature 也就是"带有签名的utf-8”,
因此"utf-8-sig"读取带有BOM的"utf-8文件时"会把BOM单独处理,与文本内容隔离开,也是我们期望的结果.
最终代码:


1 #!/user/bin/env python 2 # -*- coding:utf-8 -*- 3 # Author: Mr.riy 4 5 6 import re 7 import requests 8 import csv 9 import time 10 import jieba 11 import jieba.analyse 12 from requests.exceptions import RequestException 13 from bs4 import BeautifulSoup 14 15 16 class Downloader: 17 def __init__(self): 18 self.data_list = [] 19 20 def download(self, url, num_retries=3): 21 '判断页面' 22 print('Downloading:', url) 23 global response 24 response = requests.get(url) 25 response.encoding='utf-8' 26 try: 27 if 'Sorry, Page Not Found' in response.text: 28 print(url, '页面不存在') 29 elif '该内容已经被撤销' in response.text: 30 print(url, '页面不存在') 31 elif response.status_code == 200: 32 print('下载成功,开始执行......') 33 # print(response.text) 34 # print(response.encoding) 35 page = response.content 36 self.find_all(page) 37 time.sleep(1) 38 else: 39 if num_retries > 0 and 500 <= response.status_code <= 600: 40 html = self.download(url, num_retries-1) 41 except RequestException as e: 42 print(e) 43 44 def find_all(self, page): 45 '爬取内容' 46 soup_title = BeautifulSoup(page, 'lxml') 47 sp_title_items = soup_title.find('h2', attrs={'align': 'center'}) 48 title = sp_title_items.text 49 print(title) 50 51 sp_time_items = soup_title.find('div', attrs={'style': 'line-height:400%;color:#444444;font-size:14px'}) 52 times = sp_time_items.text 53 # print(times) 54 time = re.findall(r'd{4}年d{2}月d{2}日 d{2}:d{2}', times) 55 # print(time) 56 author = re.findall(r'作者:(.*)', times) 57 # print(author) 58 global response 59 if 'vsb_content_4' in response.text: 60 sp_words_items = soup_title.find('div', attrs={'id': 'vsb_content_4'}) 61 elif 'vsb_content_501' in response.text: 62 sp_words_items = soup_title.find('div', attrs={'id': 'vsb_content_501'}) 63 else: 64 sp_words_items = soup_title.find('div', attrs={'id': 'vsb_content'}) 65 66 words = sp_words_items.text 67 # print(words) 68 row = [] 69 row.append(time) 70 row.append(author) 71 row.append(words) 72 self.data_list.append(row) 73 74 def write_csv(self, filename, all_list): 75 '写入csv文件' 76 with open(filename, 'w', encoding="utf-8-sig", newline='') as f: 77 writer = csv.writer(f) 78 fields = ('时间', '作者', '内容') 79 writer.writerow(fields) 80 for row in all_list: 81 writer.writerow(row) 82 83 def fetch_data(self): 84 '设置爬取页面' 85 all_list = [] 86 for page in range(13795, 14000, 1): #设置爬取的页面范围 87 url = f'http://www.xxxxxx.cn/info/1013/{page}.htm' 88 self.download(url) 89 all_list += self.data_list 90 self.data_list = [] 91 92 self.write_csv('data.csv', all_list) 93 94 95 class analyze: 96 def get_all_text(self, filename): 97 '取出所有评价的句子' 98 comment_list = [] 99 with open(filename, encoding="utf-8-sig") as f: 100 rows = csv.reader(f) 101 for row in rows: 102 one_comment = row[-1] 103 comment_list.append(one_comment) 104 105 return ''.join(comment_list[1:]) 106 107 def cut_text(self, all_text): 108 '找到评价中重要关键词' 109 jieba.analyse.set_stop_words('stop_words.txt') 110 text_tags = jieba.analyse.extract_tags(all_text, topK=30) 111 return text_tags 112 113 114 def main(): 115 temp = Downloader() 116 temp.fetch_data() 117 b = analyze() 118 all_text = b.get_all_text('data.csv') 119 text_tags = b.cut_text(all_text) 120 print(text_tags) 121 122 123 if __name__ == "__main__": 124 main()
运行截图:最近新闻出现最多的关键字为:防疫,疫情,工作
