http://videolectures.net/icml09_dasgupta_langford_actl/
主动学习目的:
尽可能少的标注,获取尽可能好的训练结果

一般来说我们希望我们训练的模型能够对于natural distribution也就是说truly underlying distribution表现最好
对于数据集合的随机抽取标注能够做到这一点,但是对于主动学习比如上面的策略,我们会倾向选取靠近分类面的点,那么我们的训练集合的数据点就会集中在分类面两侧,也就是说随着我们主动学习策略不断迭代,我们选取的训练集合会离truly underlying distribution越来越远
我们真的需要对这样一个训练集合进行训练 optimize?
这就引出了Biased Sampling
The labeled points are not representative of the underlying distribution
提问: 这会是主动学习的本质带来的?主动学习是要选取choosing instance而不是随机选取instance
回答: 我们是要选取最有信息量的点,于此同时我们期望选取的训练集合能够在随机数据也就是truly underling distribution上表现最好,因此看上去这里有一些tradeoff或者说是conflict,因此我们这里就是要解决这个问题。

这里主动学习策略会误认为5%绿色是红色。。 但事实不是这样的
因此这里的主动学习算法不是consistant的
consistant的定义:
当你选取的点集趋近无穷的时候,对应的训练集合的训练出来的模型应该是趋近最优的
Even with infinitely many labels, converges to a classifier with 5%
error instead of the best achievable, 2.5%. Not consistent!
Adaptive query能否解决这个问题?
There are two distinct narratives for explaining how adaptive
querying can help.
Case I: Exploiting (cluster) structure in data
Case II: Efficient search through hypothesis space
Case I: Exploiting (cluster) structure in data
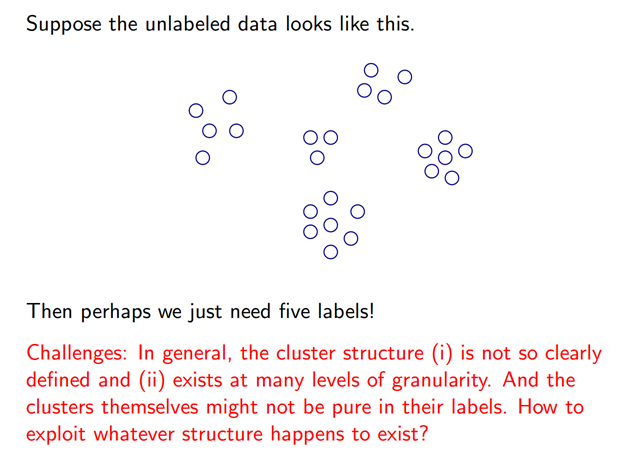
这里的问题是定义不清晰,聚类本身存在粒度问题,5个cluster,6个,7个。。。?
另外每个cluster内部的label可能是不一致的