- 如何评估语言模型 (<<speech and language processin>>)
Perplexity
一个语言模型表现更好好就是说它在测试集合表现更好,也就是说使得测试数据能有更高产生概率(assign a higher score to test data)
在这个基础上表征了这一特征,perplextiy越低则表示测试数据产生概率越高。

N起归一作用,在这里避免了长度偏见,较长句子会使得概率较小一些。
考虑
If P(w1,w2) = 1/16 (N = 2)
Then PP(W) = 4
If P(w1w2,w3,w4) = 1/16 (N = 4)
Then PP(W) = 2
如果使用ChainRule来表示

更进一步如果是bigram的语言模型

考虑如果是一个uingram语言模型,词典对应 (1,2,3,….10) 每个出现概率是1/10
那么PP(W) = 10


在一个数据集合(wall street journal)训练unigram,bigram,trigram三种语言模型,在测试集合上对应的Perplexity表现是

Perplexity和信息论的关系
考虑一个数据对应可以用8bit编码,那么对应的perplexity是256。
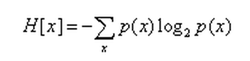
H[x] = 8
类似上面 p(x) = 1/256

信息熵

Entropy rate (per-word entropy)


根据Shannon-McMillan-Breiman theorem

交叉熵

同样根据Shannon-McMillan-Breiman theorem


这里本质上就是 perplexity 就是 交叉熵的指数形式 exp of cross entropy

根据perplexity和交叉熵的关系,更小的perplexity从某种意义表明当前模型是更加接近产生测试数据集合的真实模型。