- 初始化的选取很重要,random_uniform的效果远远好于random_normal, 是否有bias对效果影响很小
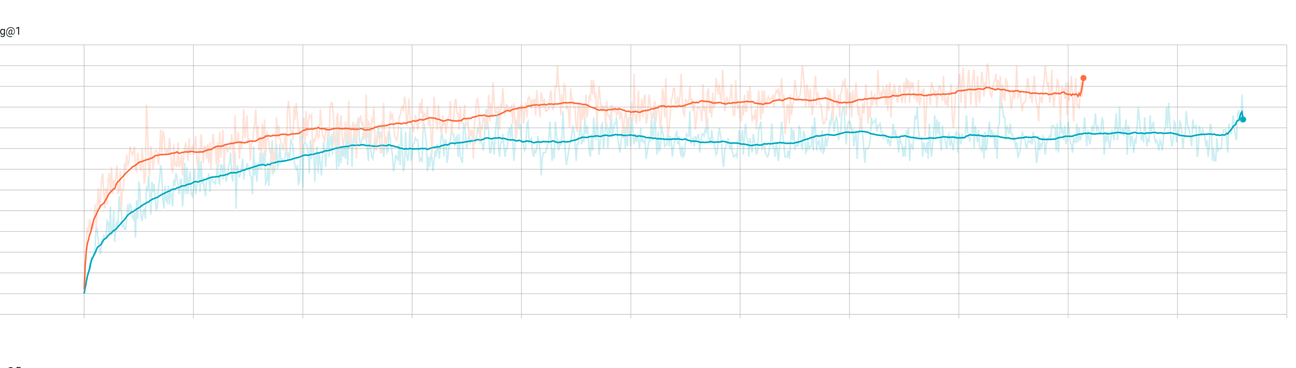
红色是random_uniform初始化,对比random_normal初始化的蓝色, 曲线表示ndcg@1
-
文本端使用更复杂的建模能够提升效果特别针对flickr长序列数据,对应短关键词数据效果没有这么明显
实验表明逆向lstm,采用向量累加表示文本效果好于正向lstm
lstm相对收敛慢但是后来居上 多次迭代后效果超过bow模型
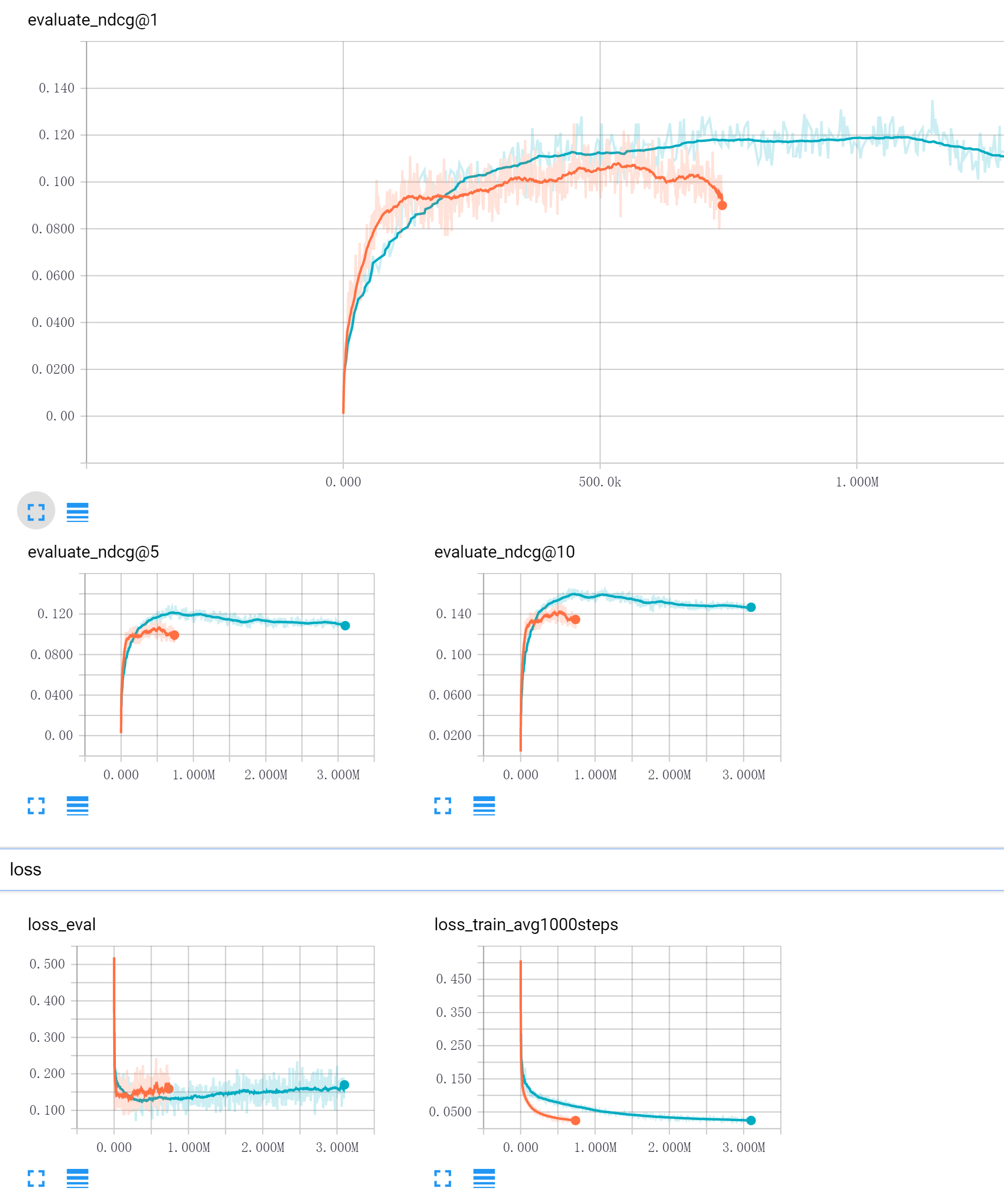
红色bow模型,蓝色rnn模型
值得注意的是 相对bow模型 rnn的 trainloss 下降要慢很多 但是测试集合效果要好, metric结果多轮之后也明显变好,top1的准确率(召回)可以达到约12%