tensorflow基于 Grammar as a Foreign Language实现,这篇论文给出的公式也比较清楚。
这里关注seq2seq.attention_decode函数,
- 主要输入
decoder_inputs,
initial_state,
attention_states,
这里可以主要参考 models/textsum的应用,textsum采用的多层双向lstm,
假设只有一层,texsum将正向 最后输出的state作为 attention_decode的输入initial_state
(不过很多论文认为用逆向最后的state可能效果更好)
对应decocer_inputs就是标注的摘要的字符序列id对应查找到的embedding序列
而attention_states是正向负向输出concatenate的所有outputs(hidden注意output和hidden是等同概念)
- 关于linear
首先注意到在attention_decode函数用到了一个linear这个定义在rnn_cell._linear函数
他的输入是 一个list 可能的输入是比如
[ [batch_size, lenght1], [batch_size_length2]]
对应一个list 2个数组
它的作用是内部定义一个数组 对应这个例子 [length1 + length2, output_size]
也就是起到将[batch_size, length1][batch_size, length2]的序列输入映射到 [batch_size, output_size]的输出
这个在attention机制最后会遇到
先看attention的公式
将encoder的hidden states表示为
(h 1 , . . . , h T A)
将decoder的hidden states表示为
(d 1 , . . . , d T B) := (h T A +1 , . . . , h T A +T B).

这里最后计算得到的
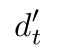
就是attention的结果 对应一个样本 就是长度为 atten_size的向量(就是所有attention输入向量按照第三个公式的线性叠加之后的结果)那么对应batch_size的输入 就是[batch_size, atten_size]的一个结果。
论文中提到后面会用到这个attention,
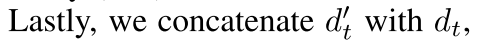
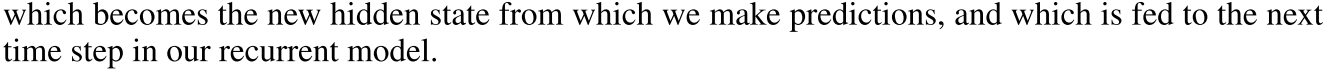
也就是说会concat attention的结果和原始hidden state的结果,那么如何使用呢,tf的做法
x = linear([inp] + attns, input_size, True)
# Run the RNN.
cell_output, state = cell(x, state)
就是说 inp是 [batch_size, input_size], attns [batch_size, attn_size] linear的输入对应 input_size
即在linear内部经过input和attns concate之后输出[batch_size, input_size]使得能够x作为输入继续进行rnn过程
- attention公式
继续看attention公式 ,不要考虑batch_size就是按照一个样本来考虑
第一个公式 对应3个举止 W1,W2都是[attn_size, atten_size]的正方形矩阵,h,d对应 [attent_size, 1]的向量
v对应[atten_size, 1]的矩阵,
那么就是线性叠加之后做非线性变化tanh([attn_size, 1])->[attn_size, 1]最后和v做dot得到一个数值 表示u(i,t)
即对应第i个attention向量在decode的t时刻时候应该的权重大小,
第二个公式表示使用softmax做归一化得到权重向量概率大小。
第三个公式上面已经分析。
- tensorflow中attention的实现
- 步骤1
这里第一个问题是我们按照batch操作所以对应处理的不是一个样本而是一批batch_size个样本。
那么上面的操作就不能按照tf.matmul来执行了,因为[batch_size, x, y][y, 1]这样相乘是不行的
tf的做法是使用1by1 convolution来完成,主要利用1by1 + num_channels + num_filters
关于conv2d的使用特别是配合1by1,num_channels, num_filters 这里解释的非常清楚
http://stackoverflow.com/questions/34619177/what-does-tf-nn-conv2d-do-in-tensorflow
# To calculate W1 * h_t we use a 1-by-1 convolution, need to reshape before.
hidden = array_ops.reshape(
attention_states, [-1, attn_length, 1, attn_size])
hidden_features = []
v = []
attention_vec_size = attn_size # Size of query vectors for attention.
for a in xrange(num_heads):
k = variable_scope.get_variable("AttnW_%d" % a,
[1, 1, attn_size, attention_vec_size])
hidden_features.append(nn_ops.conv2d(hidden, k, [1, 1, 1, 1], "SAME"))
v.append(
variable_scope.get_variable("AttnV_%d" % a, [attention_vec_size]))
atention_vec_szie == attn_size
attn_size 对应 num_channels (num_channels个位置相乘加和 dot)
attention_vec_size 对应 num_filters
刚好这个conv2d的对应就是batch_size版本的attention的第一个公式里面的 W1 * h_t
Conv2d输出[batch_size, atten_length, 1, attention_vec_size]
- def attention(query)的分析
attention(query)的输入是rnn上一步输出的state
输出 attns = attention(state)对应 [batch_size, attn_size]的矩阵
对应当前步骤需要用到的attention
def attention(query):
"""Put attention masks on hidden using hidden_features and query."""
ds = [] # Results of attention reads will be stored here.
if nest.is_sequence(query): # If the query is a tuple, flatten it.
query_list = nest.flatten(query)
for q in query_list: # Check that ndims == 2 if specified.
ndims = q.get_shape().ndims
if ndims:
assert ndims == 2
query = array_ops.concat(1, query_list)
for a in xrange(num_heads):
with variable_scope.variable_scope("Attention_%d" % a):
y = linear(query, attention_vec_size, True)
y = array_ops.reshape(y, [-1, 1, 1, attention_vec_size])
# Attention mask is a softmax of v^T * tanh(...).
s = math_ops.reduce_sum(
v[a] * math_ops.tanh(hidden_features[a] + y), [2, 3])
a = nn_ops.softmax(s)
# Now calculate the attention-weighted vector d.
d = math_ops.reduce_sum(
array_ops.reshape(a, [-1, attn_length, 1, 1]) * hidden,
[1, 2])
ds.append(array_ops.reshape(d, [-1, attn_size]))
return ds
首先目前默认都是用state_is_tuple=True选项(这样效率更高,后面state_is_tupe=False将会depreciated)
前面已经说过tf实现的state对应两个(cell_state, hidden_state)
所以这里nest_issequence是True 对应最后处理后query 就是 [batch_size, 2 * input_size]
y = linear(query, attention_vec_size, True)
y = array_ops.reshape(y, [-1, 1, 1, attention_vec_size])
对应W2dt的计算
hidden_features[a] + y 则注意是 W2dt累加到 所有的hi(attn_length个)
a对应[batdh_size, attn_length]
Reshape[batch_size, atten_length, 1, 1]
Hidden [batch_size, atten_length, 1, atten_size]
最终返回 [batch_size, attn_size]