这篇文章最初发布在RT-Thread官方论坛中,最近准备整理放到博客中来让更多人一起探讨学习。
2012年9月28日星期五
前言:
母语能力有限
概述:
这篇文字和大家分享一下今晚对RT-Thread的内存管理——小内存管理算法的理解。若有不对的地方请大家丢砖。
正文:
分析的源码文件mem.c
主要的几个函数:
1、rt_system_heap_init
2、rt_malloc
3、rt_free
4、plug_holes
armcc编译器中的初始化内存的方式:
rt_system_heap_init((void*)&Image$$RW_IRAM1$$ZI$$Limit, (void*)STM32_SRAM_END);
接触RTT半年以来,对这里的第一个参数是又爱又恨,爱它的神秘怪僻,恨它的怪僻神秘。
extern int Image$$RW_IRAM1$$ZI$$Limit;
从这里可以看得出它是火星人还是地球人。不错这样的声明我们大概能知道的是仅仅只是一个变量而已。不过它的定义在何处?我纠结到昨天晚上才见到它真实的面貌(这还多亏aozima的指点)。这是一个链接器导出的符号,代表ZI段的结束(科普:假如芯片的RAM有32Kbyte,那么通常我们的程序没有占用完全部的RAM,且ARMCC的链接器会将ZI段排在RAM已使用的RAM区域中的最后面。所以ZI段的后面就是程序未能使用到的RAM区域)。关于这种奇怪的符号都可以在MDK的帮助文档中找到!
第二个参数就是整个RAM的结束地址。所以从这两个参数上可以知道传递进去的是内存的管理区域。
rt_system_heap_init
这个函数是对堆进行初始的过程,堆的大小由传进来的起始地址(begin_addr)和结束地址(end_addr)决定。当然如果我们还要考虑内存对齐,这样一来,我们能使用的堆大小就不一定完全等于(end_addr - begin_addr)了。
rt_uint32_t begin_align = RT_ALIGN((rt_uint32_t)begin_addr, RT_ALIGN_SIZE);
rt_uint32_t end_align = RT_ALIGN_DOWN((rt_uint32_t)end_addr, RT_ALIGN_SIZE);
这两句进一步对传递的起始地址后结束地址进行对齐操作了,有可能在起始地址上往后偏移几个字节以保持在对齐的地址上,也有可能在结束地址的基础上往前偏移几个字节以保持在对齐地址上。所以这里就有可能被扣掉一点点的内存。但是这往往是很小的一点点,通常小到几个字节,也许刚好是一个都没有被扣掉。
if ((end_align > (2 * SIZEOF_STRUCT_MEM)) && ((end_align - 2 * SIZEOF_STRUCT_MEM) >= begin_align)) { /* calculate the aligned memory size */ mem_size_aligned = end_align - begin_align - 2 * SIZEOF_STRUCT_MEM; }
这部分是计算最大可分配的内存区域,?????,为什么说是最大‘可’分配的内存区域呢?因为还将被继续扣除一部分内存,这部分被扣除的内存是用来放置内存管理算法所要用的数据结构。越精巧的算法当然是效率更高,浪费的也最少。
RTT扣掉了2个数据结构的尺寸,因为RTT有一个heap_ptr和一个heap_end这两个标记,分别表示堆的起始和结束。mem_size_aligned就是整个可操作的区域尺寸。
RTT的内存管理用到的数据结构非常的精简。
struct heap_mem { /* magic and used flag */ rt_uint16_t magic; rt_uint16_t used; rt_size_t next, prev; };
总共占用了2+2+2xcpu字长(8个字节)=12个字节。其中magic字段用以标记一个合法的内存块,used字段标记这个堆内存块是否被分配,next字段指向当前这个堆内存块的末尾后1个字节(不说成是下一个可分配块,是因为也许next指向了末尾),prev指向当前这个内存块的前一个有效内存块的数据结构起始处,否则指向自身(最前面那个内存块)。所以可以看出这个设计思路是把整个内存块用链表的形式组织在一起。当然我们使用的next和prev只是相对于起始地址heap_ptr的偏移量,而不是真正在通常列表中看到的指针。
接着标记了第一块可分配的内存块,这个内存块把mem_size_aligned个字节大小划分出来,留下SIZEOF_STRUCT_MEM个字节的大小用来刚好放置heap_end,在前SIZEOF_STRUCT_MEM个字节中也就是最前面的SIZEOF_STRUCT_MEM个字节用来放置heap_ptr(堆内存的头指针)。其中第一个可分配点就是从heap_ptr开始的,heap_prt的next指向了heap_end(也就是mem_size_aligned +
SIZEOF_STRUCT_MEM),大致的初始时候的布局如下图所示:
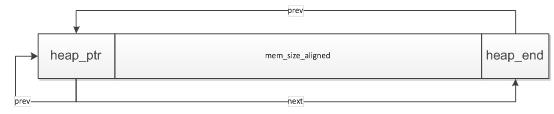
最后让lfree指向当前活动的可分配的内存块,这样可以迅速找到最进被释放的内存块上。一般只要之前分配的内存块被释放后,lfree就尽量分配靠前的内存区域,也就是优先从前往后寻找可分配的内存块。
rt_malloc
首先对申请的尺寸做对齐处理,但是这个对齐操作只会有可能比实际分配的尺寸要大一点。
for (ptr = (rt_uint8_t *)lfree - heap_ptr; ptr < mem_size_aligned - size; ptr = ((struct heap_mem *)&heap_ptr[ptr])->next)
循环查找从当前lfree所指向的区域开始,查找一块能够满足区域的内存块。
if ((!mem->used) && (mem->next - (ptr + SIZEOF_STRUCT_MEM)) >= size)
当这块内存区域没有被使用,且这块内存区域扣掉头部数据结构SIZEOF_STRUCT_MEM后的大小满足所需分配的大小那么就可以使用这个内存块来分配。
if (mem->next - (ptr + SIZEOF_STRUCT_MEM) >= (size + SIZEOF_STRUCT_MEM + MIN_SIZE_ALIGNED))
如果这个即将被分配的内存块除了能分配给当前尺寸后,还余下的有足够的空间能够组织成下一个可分配点的话,那么将对余下的部分组织成下一个可分配点。也就是将多余的空间划出来组织成一个新的可分配区域然后链接到链表中。
否则把当前这个内存块标记为已分配状态used=1。如果当前被分配的内存块是lfree指向的内存块,那么调整lfree,以让其指向下一个可分配的点。
if (mem == lfree) { /* Find next free block after mem and update lowest free pointer */ while (lfree->used && lfree != heap_end) lfree = (struct heap_mem *)&heap_ptr[lfree->next]; RT_ASSERT(((lfree == heap_end) || (!lfree->used))); }
之后将得到的内存点返回,这个时候不是返回这个可分配点的其实地址,而是返回这个可分配点的起始地址偏移一个数据结构尺寸的地址,因为每个可分配的内存块都在其前面有一个用于管理内存所需用到的一个数据结构(链表,魔数,used等信息)。
return (rt_uint8_t *)mem + SIZEOF_STRUCT_MEM;
如果当前这个循环从lfree开始查找,第一次没有找到合适的内存块,那么继续往后找,循环的判断条件是只要next小于mem_size_aligned - size就或许能找到一个合适尺寸的内存块。否则将分配失败,返回NULL。这里虽然分配的size小于可分配的区域,但是由于多次分配释放等过程产生了内存碎片,真正连续可用的空间并非这么多。
rt_free
调用这个函数是释放之前分配的堆内存。所以使用rt_malloc函数返回的内存块地址如果需要释放的时候,就需要调用rt_free。由于在rt_malloc和rt_free的外面使用者来说,是不知道这个内存地址的前面有一个管理数据结构的,所以在rt_free的时候需要往前偏移SIZEOF_STRUCT_MEM个字节,用以找到数据结构的起点。
mem = (struct heap_mem *)((rt_uint8_t *)rmem - SIZEOF_STRUCT_MEM);
接着将这个内存块标记为未被分配的状态。
mem->used = 0; mem->magic = 0;
如果释放的内存地址在lfree的前面,那么将lfree指向当前释放的内存块上。
if (mem < lfree) { /* the newly freed struct is now the lowest */ lfree = mem; }
最后调用plug_holes函数进行一些附加的优化操作,这个优化操作是必不可少以及体现整个内存分配算法核心价值的地方(先卖个关子,等我慢慢道来)。
plug_holes
这个函数的作用就是合并当前这个内存点的前后紧接着的已经被释放的内存块。这样一来就可以解决内存碎片问题。
nmem = (struct heap_mem *)&heap_ptr[mem->next];
if (mem != nmem && nmem->used == 0 && (rt_uint8_t *)nmem != (rt_uint8_t *)heap_end) { /* if mem->next is unused and not end of heap_ptr, combine mem and mem->next */ if (lfree == nmem) { lfree = mem; } mem->next = nmem->next; ((struct heap_mem *)&heap_ptr[nmem->next])->prev = (rt_uint8_t *)mem - heap_ptr; }
这是看其后面的内存点是否可以被合并,合并其后的内存块的时候只需要调整当前内存块的next值。其次还需要调整当前内存块后的内存块的下一个内存块的prev字段(这里有点绕口,其实就好比普通列表中的p->next->next->prev),使其指向当前本身的内存块(好比p->next->next->prev = p)。
pmem = (struct heap_mem *)&heap_ptr[mem->prev];
if (pmem != mem && pmem->used == 0) { /* if mem->prev is unused, combine mem and mem->prev */ if (lfree == mem) { lfree = pmem; } pmem->next = mem->next; ((struct heap_mem *)&heap_ptr[mem->next])->prev = (rt_uint8_t *)pmem - heap_ptr; }
这是合并当前内存块前面的已被释放的内存块,先取出前面的内存块,然后调整前一个内存块的next指向当前内存块的next所指的地方,接着将当前内存块的下一个内存块的prev字段指向当前内存款的前一个内存块(好比p->next->prev = p->prev)。
这样两大步就可以将当前释放的内存块的前后两个已经被释放的内存块给合并成一个大的内存块。从而避免了碎片问题,提高了内存分配的可靠性。
2012年9月28日3时16分46秒
感谢各位网友的支持,如果想得到最新的文章资讯请关注我的微信公众号:鹏城码夫 (微信号:rocotona)
