Twitter 工程师谈 JVM 调优
一. 调优需要关注的几个方面
内存调优
CPU 使用调优
锁竞争调优
I/O 调优
二. Twitter 最大的敌人:延迟
导致延迟的几个原因?
最大影响因素是 GC
其他的有:锁和线程调度、I/O、算法数据结构选取不当效率低
三. 内存性能调优
(1)内存占用调优
OutOfMemoryError 异常原因:可能真的数据量太大、可能要数据显示的太多、可能内存泄露
数据量太大观察及解决:
查看 GC 日志, 看 Full GC 前后内存变化, 变化不大说明确实数据量太大
尝试增加 JVM 的内存使用
考虑这些数据是否真的需要都在内存中吗? 可以考虑使用: LRU 算法换入换出等, 弱引用(Soft References)
数据臃肿(Fat data)
当你想做一些奇怪的事情时候回发生数据占用太大问题,比如:把整个社交图谱加载到单个 JVM 实例上、加载全部用户的元数据到单个 JVM 实例上
在 Twitter 这样大的规模下减少内部数据呈现工作
数据臃肿原因:
(1)对象头(JVM 对象头一般占用两个机器码,在 32-bit JVM 上占用 64bit, 在 64-bit JVM 上占用 128bit 即 16 bytes, 例如:new java.lang.Object() 占用 16 bytes; new byte[0] 占用 24 bytes) 更多对象头内容参考:http://blog.csdn.net/wenniuwuren/article/details/50939410
(2)填充补全
看个例子
public static class D {
byte d1;
}
public static class E extends D {
byte e1;
}
new D() 占用 24 bytes 空间, new E() 占用 32 bytes 空间。 具体空间计算参考:http://blog.csdn.net/wenniuwuren/article/details/50958892
现在一般是 64-bit 的 JVM,64-bit 的指针会导致 CPU 缓存相比 32-bit 指针减少很多, 所以建议 JVM 参数加入 -XX:+UseCompressedOops 采用指针压缩将 64-bit 指针压缩为 32-bit, 但是却又能使用 64-bit 的内存空间, 达到一举两得的作用。另外,建议最大堆小于 30G。
尽量别使用原始类型对象的包装类
在 Scala 2.7.7 中:Seq[Int] 存 Integer,Array[Int] 存 int, 第一个空间占用 (24 + 32*length) bytes,第二个空间占用 (24 + 4*length) bytes。
在 Scala 2.8 中修复了这个问题, 从这我们可以看出:
你不清楚你所使用类库的性能特征(比如能用 int 就用 int)
除非在性能分析工具下运行, 否则你可能永远不知道这个问题
Map 空间占用(Map footprints)
Guava MapMaker.makeMap() 占用 2272 bytes
MapMaker.concurrencyLevel(1).makeMap() 占用 352 bytes
小心使用 Thread Local
典型的问题在线程池 m*n 的资源相关,如 200 线程池使用了 50 个连接,最终有 10000 个连接缓存
考虑使用同步对象或者每次新建一个对象
四. 与延迟做斗争
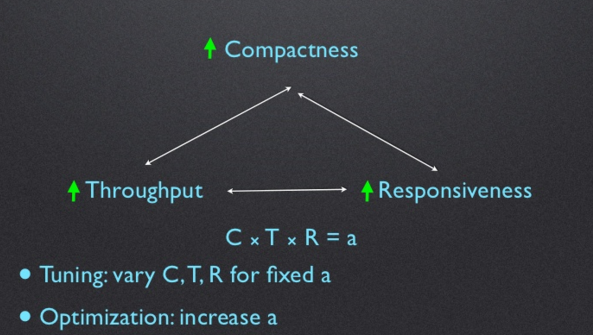
性能三角
图1:内存占用下降,延迟下降,吞吐量上升
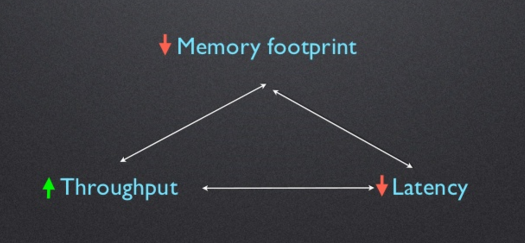
图2:压缩(Compactness,即减小内存占用)率上升,吐量上升,响应速度上升
新生代是如何工作的?
所有新对象分配在 Eden 代,因为新生代 GC 有压缩,所以内存分配用指针碰撞
当 Eden 满的时候,进行一次 stop-the-world 的 Minor GC,存活下来的放到 Survivor
经过几次 Minor GC,还存活下来的对象会被提升(tenured)到老年代
理想化得新生代操作
Eden 代足够容纳超过一组并发的请求和响应对象(这样没有 stop-the-world,吞吐量会比较高)
每个 Survivor 空间足够容纳活跃对象和有年龄的对象(减少过早提升到老年代)
提升阈值正好能让存活时间长的对象早点提升到老年代(给 Survivor 腾出空间)
从新生代开始调优
打印详细 GC 日志, 如开启 JVM 参数:-XX:+PrintGCDetails,-XX:+PrintGCDateStamps,-XX:+PrintHeapAtGC,-XX:+PrintTenuringDistribution 等等...
关注 Survivor 大小,设置合适的 Survivor 大小
关注提升阈值,使长期存活对象快速提升到老年代
(1)-XX:+PrintHeapAtGC
Heap after GC invocations=1 (full 0): par new generation total 943744K, used 54474K [0x0000000757000000, 0x0000000797000000, 0x0000000797000000) eden space 838912K, 0% used [0x0000000757000000, 0x0000000757000000, 0x000000078a340000) from space 104832K, 51% used [0x00000007909a0000, 0x0000000793ed2ae0, 0x0000000797000000) to space 104832K, 0% used [0x000000078a340000, 0x000000078a340000, 0x00000007909a0000) concurrent mark-sweep generation total 1560576K, used 0K [0x0000000797000000, 0x00000007f6400000, 0x00000007f6400000) concurrent-mark-sweep perm gen total 159744K, used 38069K [0x00000007f6400000, 0x0000000800000000, 0x0000000800000000) }
(2)-XX:+PrintTenuringDistribution
Desired survivor size 53673984 bytes, new threshold 4 (max 6) - age 1: 9165552 bytes, 9165552 total - age 2: 2493880 bytes, 11659432 total - age 3: 6817176 bytes, 18476608 total - age 4: 36258736 bytes, 54735344 total : 899459K->74786K(943744K), 0.0654030 secs] 1225769K->401096K(2504320K), 0.0657530 secs] [Times: user=0.55 sys=0.00, real=0.07 secs]
CMS 调优
CMS 收集器需要更多的内存, 尽量多分配就对了
减少碎片、避免 Full GC
-XX:CMSInitiatingOccupancyFraction=n n一般设置为 75-80(太早启动降低吞吐量,太晚启动导致 concurrent mode failed)
响应速度还是太慢?
Minor GC 时有太多存活对象,尝试减少新生代空间,减少 Survivor 空间,减少晋升阈值
太多线程。尝试找到最小的并发层次或者增加更多 JVM 实例
尝试使用 volatile 而不是 synchronized 减少锁竞争,尝试使用 Atomic* 的原子类
用分配 slab 应对 CMS 的碎片问题
Apache 的 Cassandra 内部使用 slab 分配。每个 slab 大小为 2MB,使用 CAS 复制 byte[] 到里面,使用 Cassandra 前开销为 30-60 秒每小时, 使用后在3天零十小时开销 5 秒。
使用分配 slab 的方式有一些局限性:在缓存满的时候才把缓存内容写进磁盘,而且对象需要转化为二进制等问题
原文出处 http://www.slideshare.net/aszegedi/everything-i-ever-learned-about-jvm-performance-tuning-twitter/2-Everything_I_everlearned_about_JVMperformance