https://mp.weixin.qq.com/s/BnCV2ZsB-hVuDJXgQqpC4A
C语言:--位域和内存对齐
位域
位域是指信息在保存时,并不需要占用一个完整的字节,而只需要占几个或一个二进制位。为了节省空间,C语言提供了一种数据结构,叫“位域”或“位段”。
“位域“是把一个字节中的二进位划分为几个不同的区域,并说明每个区域的位数,每个域有一个域名,允许在程序中按位域名进行操作。这样就可以把几个不同的对象用一个字节的二进制位域来表示。
位域的使用和结构成员的使用相同,其一般形式为:位域 变量名.位域名 位域允许用各种格式输出。
1. 在C中,位域可以写成这样(注:位域的数据类型一律用无符号的,纪律性)。
struct bitmap
{
unsigned a : 1;
unsigned b : 3;
unsigned c : 4;
}bit;
sizeof(bitmap) == 4;(整个struct的大小为4,因为位域本质上是从一个数据类型分出来的,在我们的例子中数据类型就是unsigned,大小为4,并且位域也是满足C 的结构体内存对齐原则的,等下我们会说到)。
2. 当然了位域也可以有空域。
struct bitmap
{
unsigned a:4;
unsigned :0; /*空域*/
unsigned b:4; /*从下一单元开始存放*/
unsigned c:4;
}
sizeof(bitmap) == 8;
3. 在这个位域定义中,a占第一字节的4位,后4位填0表示不使用,b从第二字节开始,占用4位,c占用4位。这里我们可以看到空域的作用是填充数据类型的剩下的位置,有时候我们只是想调整一下内存分配,则我们可以使用无名位域:
struct bitmap {
unsigned a:1;
unsigned :2;
unsigned b:3;
unsigned c:2;
};
sizeof(bitmap) == 4;
4. 如果一个位域的位的分配超过了该类型的位的总数,则从下一个单元开始继续分配,这个很好理解:
struct bitmap
{
unsigned a : 8;
unsigned b : 30;
unsigned c : 4;
};
sizeof(bitmap) == 12;
注意这个位域的大小是12而不是8,说明如果超了大小是立马从下一个单元开始分配。
位域的使用主要出现在如下两种情况:
(1)当机器可用内存空间较少而使用位域可以大量节省内存时。如,当把结构作为大数组的元素时。
(2)当需要把一结构或联合映射成某预定的组织结构时。例如,当需要访问字节内的特定位时。
当要把某个成员说明成位域时,其类型只能是int,unsigned int与signed int三者之一(说明:int类型通常代表特定机器中整数的自然长度。short类型通常为16位,long类型通常为32位,int类型可以为16位或32位.各编译器可以根据硬件特性自主选择合适的类型长度.
关于位域还需要提醒读者注意如下几点:
其一,位域的长度不能大于int对象所占用的字位数.例如,若int对象占用16位,则如下位域说明是错误的:
unsigned int x:17;
其二,由于位域的实现会因编译程序的不同而不同,在此使用位域会影响程序的可移植性,在不是非要使用位域不可时最好不要使用位域.
其三,尽管使用位域可以节省内存空间,但却增加了处理时间,在为当访问各个位域成员时需要把位域从它所在的字中分解出来或反过来把一值压缩存到位域所在的字位中.
其四,位域的位置不能访问,因些不能对位域使用地址运算符号&(而对非位域成员则可以使用该运算符).从而,即不能使用指向位域的旨针也不能使用位域的数组(因为数组实际上就是一种特殊的指针).另外,位域也不能作为函数返回的结果.
最后还要强调一遍:位域又叫位段(位字段),是一种特殊的结构成员或联合成员(即只能用在结构或联合中).
2. 内存对齐:
1. 说到位域就不得说下内存对齐的东西,其实内存对齐也很简单,只是不同的编译器实现不一样,至于为什么要内存对齐,这个要从CPU的基本工作原理说起,但是首先要明白,无论我们是否内存对齐,CPU大多数情况都是能正常工作的(前提:对于大多数IA32指令都可以这么说,但是部分指令,如SSE多媒体指令这些就不行,这些指令有特殊内存对齐要求,比如16字节对齐,任何不满足内存对齐的地址访问储存器都是会导致异常,对于这些指令,编译器必须在编译的时候采取强制内存对齐)。
实现内存对齐可以提高CPU的性能,比如处理器能一次取出8个字节,这个时候必须要求数据地址要8字节对齐,这个是和CPU和储存器的外围电路决定的,在内存对齐的情况下,CPU从储存器取出这8个字节只需要一个时钟周期,但是如果这个地址不是8字节对齐,那么CPU可能就需要两个时钟周期才能取出这8个字节。
对于IA32,每个栈帧都惯例16字节对齐,编译器一般也会那么做,但是对于数据类型不同的编译器表现可能不一样,对于Windows(VC编译器),任何K字节的基本对象的地址都必须是K的倍数(比如对于int,必须4字节对齐,对于double,必须8字节对齐),这很大程度上提高了储存器和CPU的工作性能,但是对存储空间的浪费比较严重;对于Linux,惯例是8字节数对齐4字节边界(比如double可以4字节对齐)。对于Windows好Linux,数据类型long double都有4字节对其的要求,对于GCC,long double分配12字节(虽然它只占10字节大小)。
所以我们有一般规则:
struct X{char a;float b;int c;double d;unsigned e;};sizeof(X) == 32;
内存对齐状况应该是下面这个样子:
struct X{char a; // 1 byteschar padding1[3]; // 3 bytesfloat b; // 4 bytesint c; // 4 byteschar padding2[4]; // 4 bytesdouble d; // 8 bytesunsigned e; // 4 byteschar padding3[4]; // 4 bytes};sizeof(X) == 32;
(其中最后的4个字节的填充是因为规则4,看下面)。
2. 如果自定义数据类型含有位域,则内存对齐满足以下原则:
1. 如果相邻的位域的数据类型相同,则按照分配位的大小来,详情看我上面写的位域的第5个情况。
2. 如果相邻的位域的数据类型不相同,则不同编译器实现不一样,有些编译器选择不压缩。
3. 如果位域不连续,中间含非位域,则按标准数据类型大小划分,比如:
struct bitmap{unsigned a : 2;int b;unsigned c : 3;};sizeof(bitmap) == 12;
3. 另外可以通过添加#pragma pack(n)来强制改变内存分配情况,比如在VC编译器中:
struct bitmap
{
unsigned a;
double c;
};
sizeof(bitmap) == 16;
加了#pragma pack(4),则强制内存对齐4字节,再测试下其大小:
struct bitmap{unsigned a;double c;};sizeof(bitmap) == 12;
当然,如果#pragma pack(n)的n大于本身数据类型的宽度,则按数据类型的宽度来分配:
struct bitmap{double c;int k;int m;};sizeof(bitmap) == 16 != 32
4. 自定义类型(C结构体,C++聚合类)的最后的内存对齐,是按照自定义类型内的最大类型的宽度来的,比如上面那个例子去掉int m:
struct bitmap
{
double c;
int k;
};
sizeof(bitmap) == 16
必须以double进行8字节对齐(VC编译器)。
https://mp.weixin.qq.com/s/Wd2PKMKrRcF7brjX4N_L9w
什么是内存对齐?Go 是否有必要内存对齐?
https://mp.weixin.qq.com/s/NE6Y2TVxrl-cpY-36puQcQ
CPU 访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问。比如 32 位的 CPU,字长为 4 字节,那么 CPU 访问内存的单位也是 4 字节。
这么设计的目的,是减少 CPU 访问内存的次数,加大 CPU 访问内存的吞吐量。比如同样读取 8 个字节的数据,一次读取 4 个字节那么只需要读取 2 次。
下面我们来看看,编写程序时,变量在内存中是否按内存对齐的差异。假设我们有如下结构体:
struct Foo {
uint8_t a;
uint32_t b;
}
示意图如下:
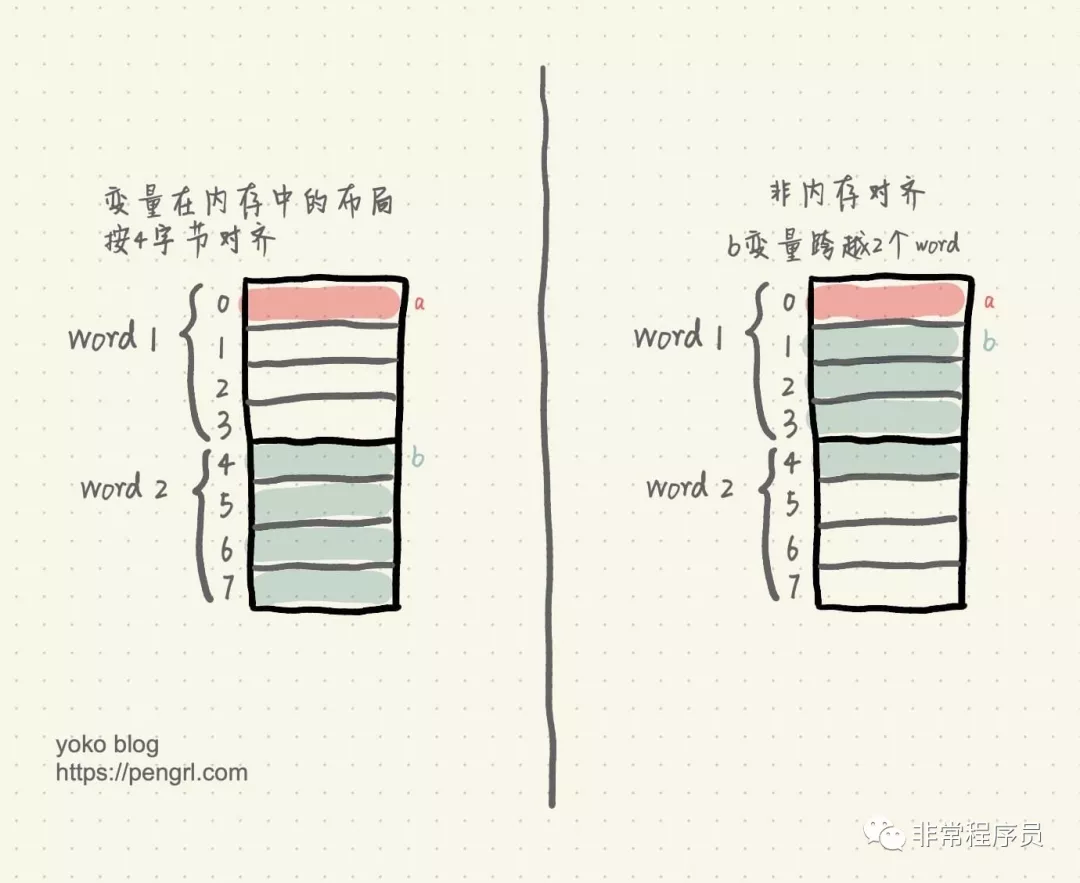
内存对齐
我们假设 CPU 以 4 字节为单位读取内存。
如果变量在内存中的布局按 4 字节对齐,那么读取 a 变量只需要读取一次内存,即 word1;读取 b 变量也只需要读取一次内存,即 word2。
而如果变量不做内存对齐,那么读取 a 变量也只需要读取一次内存,即 word1;但是读取 b 变量时,由于 b 变量跨越了 2 个 word,所以需要读取两次内存,分别读取 word1 和 word2 的值,然后将 word1 偏移取后 3 个字节,word2 偏移取前 1 个字节,最后将它们做或操作,拼接得到 b 变量的值。
显然,内存对齐在某些情况下可以减少读取内存的次数以及一些运算,性能更高。
另外,由于内存对齐保证了读取 b 变量是单次操作,在多核环境下,原子性更容易保证。
但是内存对齐提升性能的同时,也需要付出相应的代价。由于变量与变量之间增加了填充,并没有存储真实有效的数据,所以占用的内存会更大。这也是一个典型的空间换时间的应用场景。
好,本篇文章就到这里,后面会再写一篇文章介绍编写 c 程序时,如何开关内存对齐,以及控制内存按多少字节对齐。