http://www.cs.toronto.edu/~hinton/science.pdf
High-dimensional data can be converted to low-dimensional codes by training a multilayer neural
network with a small central layer to reconstruct high-dimensional input vectors. Gradient descent
can be used for fine-tuning the weights in such ‘‘autoencoder’’ networks, but this works well only if
the initial weights are close to a good solution. We describe an effective way of initializing the
weights that allows deep autoencoder networks to learn low-dimensional codes that work much
better than principal components analysis as a tool to reduce the dimensionality of data.
D
imensionality reduction facilitates the
classification, visualization, communi-
cation, and storage of high-dimensional
data. A simple and widely used method is
principal components analysis (PCA), which
finds the directions of greatest variance in the
data set and represents each data point by its
coordinates along each of these directions. We
describe a nonlinear generalization of PCA that
uses an adaptive, multilayer encoder network to
transform the high-dimensional data into a
low-dimensional code and a similar decoder
network to recover the data from the code.
Fig. 1.Pretraining consists of learning a stack of restricted Boltzmann machines (RBMs), eachhaving only one layer of feature detectors. Thelearned feature activations of one RBM are usedas the ‘‘data’’ for training the next RBM in the stack. After the pretraining, the RBMs are‘‘unrolled’’ to create a deep autoencoder, which is then fine-tuned using backpropagation oferror derivatives.
Starting with random weights in the twonetworks, they can be trained together byminimizing the discrepancy between the orig-inal data and its reconstruction. The requiredgradients are easily obtained by using the chainrule to backpropagate error derivatives firstthrough the decoder network and then throughthe encoder network (1). The whole system is called an autoencoderand is depicted in Fig. 1.
It is difficult to optimize the weights innonlinear autoencoders that have multiplehidden layers (2–4). With large initial weights,autoencoders typically find poor local minima;with small initial weights, the gradients in theearly layers are tiny, making it infeasible totrain autoencoders withmany hidden layers. If the initial weights are close to a good solution,gradient descent works well, but finding suchinitial weights requires a very different type ofalgorithm that learns one layer of features at atime. We introduce this pretraining procedurefor binary data, generalize it to real-valued data,and show that it works well for a variety of data sets.
An ensemble of binary vectors (e.g., im-ages) can be modeled using a two-layer net-work called a restricted Boltzmann machine (RBM) (5,6) in which stochastic, binary pixelsare connected to stochastic, binary featuredetectors using symmetrically weighted con-nections. The pixels correspond toBvisible[units of the RBM because their states are observed; the feature detectors correspond to hidden units. A joint configuration (v,h) of the visible and hidden units has an energy (7) given by
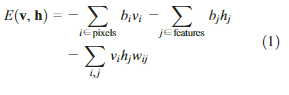
where
v
i
and
h
j
are the binary states of pixel
i
and feature
j
,
b
i
and
b
j
are their biases, and
w
ij
is the weight between them. The network as-
signs a probability to every possible image via
this energy function, as explained in (
8
).
The probability of a training image can be raised by adjusting the weights and biases to lower theenergy of that image and to raise the energy ofsimilar, confabulated images that the network would prefer to the real data.
