XML-RPC - Wikipedia https://en.wikipedia.org/wiki/XML-RPC
JSON-RPC - Wikipedia https://en.wikipedia.org/wiki/JSON-RPC
An example of a typical XML-RPC request would be:
<?xml version="1.0"?>
<methodCall>
<methodName>examples.getStateName</methodName>
<params>
<param>
<value><i4>40</i4></value>
</param>
</params>
</methodCall>
An example of a typical XML-RPC response would be:
<?xml version="1.0"?>
<methodResponse>
<params>
<param>
<value><string>South Dakota</string></value>
</param>
</params>
</methodResponse>
A typical XML-RPC fault would be:
<?xml version="1.0"?>
<methodResponse>
<fault>
<value>
<struct>
<member>
<name>faultCode</name>
<value><int>4</int></value>
</member>
<member>
<name>faultString</name>
<value><string>Too many parameters.</string></value>
</member>
</struct>
</value>
</fault>
</methodResponse>
kj'lk
Examples[edit]
In these examples, --> denotes data sent to a service (request), while <-- denotes data coming from a service. Although <-- is often called a response in client–server computing, depending on the JSON-RPC version it does not necessarily imply an answer to a request.
Version 2.0[edit]
Request and response:
--> {"jsonrpc": "2.0", "method": "subtract", "params": {"minuend": 42, "subtrahend": 23}, "id": 3}
<-- {"jsonrpc": "2.0", "result": 19, "id": 3}
Notification (no response):
--> {"jsonrpc": "2.0", "method": "update", "params": [1,2,3,4,5]}
Version 1.1 (Working Draft)[edit]
Request and response:
--> {"version": "1.1", "method": "confirmFruitPurchase", "params": [["apple", "orange", "mangoes"], 1.123], "id": "194521489"}
<-- {"version": "1.1", "result": "done", "error": null, "id": "194521489"}
Version 1.0[edit]
Request and response:
--> {"method": "echo", "params": ["Hello JSON-RPC"], "id": 1}
<-- {"result": "Hello JSON-RPC", "error": null, "id": 1}
jkl
This is a basic request to view the jCard details for a single user (based on their username). This message would be passed in a request within the "json" parameter e.g.
?json={"HEAD":{"service_type":"contacts","action_type":"view",
"sid":"80e5b8a8b9cbf3a79fe8d624628a0fe5"},"BODY":{"username":"jbloggs"}}
{
"HEAD" : {
"service_type" : "contacts",
"action_type" : "view",
"sid" : "80e5b8a8b9cbf3a79fe8d624628a0fe5"
},
"BODY" : {
"username" : "jbloggs"
}
}
This is a simple SOAPjr response with a HEAD.result that represents a success. The BODY contains a single jCard record. In a list "list" or "search" context this would contain an array of 0 or more jCard records.
{
"HEAD" : {
"result" : "1"
},
"BODY" : {
"email" : [
{
"type" : ["internet","pref"],
"value" : "spam@SOAPjr.org"
}
],
"fn" : "Joe Bloggs",
"kind" : "individual",
"n" : {
"family-name" : ["Bloggs"],
"given-name" : ["Joe"],
"value" : "Bloggs;Joe"
},
"org" : [
{
"organization-name" : "SOAPjr.org"
}
]
}
}
Remote procedure call - Wikipedia https://en.wikipedia.org/wiki/Remote_procedure_call
In distributed computing, a remote procedure call (RPC) is when a computer program causes a procedure (subroutine) to execute in a different address space (commonly on another computer on a shared network), which is coded as if it were a normal (local) procedure call, without the programmer explicitly coding the details for the remote interaction. That is, the programmer writes essentially the same code whether the subroutine is local to the executing program, or remote.[1] This is a form of client–server interaction (caller is client, executor is server), typically implemented via a request–response message-passing system. In the object-oriented programming paradigm, RPC calls are represented by remote method invocation (RMI). The RPC model implies a level of location transparency, namely that calling procedures is largely the same whether it is local or remote, but usually they are not identical, so local calls can be distinguished from remote calls. Remote calls are usually orders of magnitude slower and less reliable than local calls, so distinguishing them is important.
simple is better - JSON-RPC https://www.simple-is-better.org/rpc/
谁能用通俗的语言解释一下什么是 RPC 框架? - 知乎 https://www.zhihu.com/question/25536695
- 首先,要解决通讯的问题,主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有交换的数据都在这个连接里传输。连接可以是按需连接,调用结束后就断掉,也可以是长连接,多个远程过程调用共享同一个连接。
- 第二,要解决寻址的问题,也就是说,A服务器上的应用怎么告诉底层的RPC框架,如何连接到B服务器(如主机或IP地址)以及特定的端口,方法的名称名称是什么,这样才能完成调用。比如基于Web服务协议栈的RPC,就要提供一个endpoint URI,或者是从UDDI服务上查找。如果是RMI调用的话,还需要一个RMI Registry来注册服务的地址。
- 第三,当A服务器上的应用发起远程过程调用时,方法的参数需要通过底层的网络协议如TCP传递到B服务器,由于网络协议是基于二进制的,内存中的参数的值要序列化成二进制的形式,也就是序列化(Serialize)或编组(marshal),通过寻址和传输将序列化的二进制发送给B服务器。
- 第四,B服务器收到请求后,需要对参数进行反序列化(序列化的逆操作),恢复为内存中的表达方式,然后找到对应的方法(寻址的一部分)进行本地调用,然后得到返回值。
- 第五,返回值还要发送回服务器A上的应用,也要经过序列化的方式发送,服务器A接到后,再反序列化,恢复为内存中的表达方式,交给A服务器上的应用
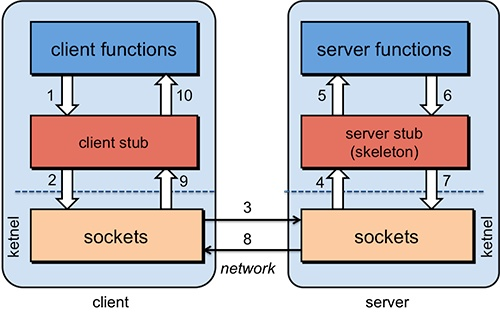
Remote Procedure Calls https://www.cs.rutgers.edu/~pxk/417/notes/03-rpc.html
Implementing remote procedure calls
Several issues arise when we think about implementing remote procedure calls.
How do you pass parameters?
Passing by value is simple: just copy the value into the network message. Passing by reference is hard. It makes no sense to pass an address to a remote machine since that memory location likely points to something completely different on the remote system. If you want to support passing by reference, you will have to send a copy of the arguments over, place them in memory on the remote system, pass a pointer to them to the server function, and then send the object back to the client, copying it over the reference. If remote procedure calls have to support references to complex structures, such as trees and linked lists, they will have to copy the structure into a pointerless representation (e.g., a flattened tree), transmit it, and reconstruct the data structure on the remote side.
How do we represent data?
On a local system there are no data incompatibility problems; the data format is always the same. With RPC, a remote machine may have different byte ordering, different sizes of integers, and a different floating point representation.
For example, big endian representation stores the most significant bytes of a multi-byte integer in low memory. Little endian representation stores the most significant bytes of an integer in high memory. Many older processors, such as Sun SPARCs and the Motorola 680x0s used big endian storage. Most Intel systems implemented little endian storage, which led to the dominance of this format. Many other architectures use a bi-endian format, where the processor can be configured at boot time to operate in either little endian or big endian mode. Examples of these processors are ARM, MIPS, PowerPC, SPARC v9, and Intel IA–64 (Itanium).
The problem was dealt with in the IP protocol suite by forcing everyone to use big endian byte ordering for all 16 and 32 bit fields in headers (hence the use of htons and htonlfunctions). For RPC, we need to come up with a “standard” encoding for all data types that can be passed as parameters if we are to communicate with heterogeneous systems. ONC RPC, for example, uses a format called XDR (eXternal Data Representation) for this process. These data representation formats can use implicit or explicit typing. With implicit typing, only the value is transmitted, not the name or type of the variable. ONC RPC’s XDR and DCE RPC’s NDR are examples of data representations that use implicit typing. With explicit typing, the type of each field is transmitted along with the value. The ISO standard ASN.1 (Abstract Syntax Notation), JSON (JavaScript Object Notation), Google Protocol Buffers, and various XML-based data representation formats use explicit typing.
What machine and port should we bind to?
We need to locate a remote host and the proper process (port or transport address) on that host. One solution is to maintain a centralized database that can locate a host that provides a type of service. This is the approach that was proposed by Birell and Nelson in their 1984 paper introducing RPC. A server sends a message to a central authority stating its willingness to accept certain remote procedure calls. Clients then contact this central authority when they need to locate a service. Another solution, less elegant but easier to administer, is to require the client to know which host it needs to contact. A name server on that host maintains a database of locally provided services.
What transport protocol should be used?
Some implementations allow only one to be used (e.g. TCP). Most RPC implementations support several and allow the user to choose.
What happens when things go wrong?
There are more opportunities for errors now. A server can generate an error, there might be problems in the network, the server can crash, or the client can disappear while the server is running code for it. The transparency of remote procedure calls breaks here since local procedure calls have no concept of the failure of the procedure call. Because of this, programs using remote procedure calls have to be prepared to either test for the failure of a remote procedure call or catch an exception.
What are the semantics of remote calls?
The semantics of calling a regular procedure are simple: a procedure is executed exactly once when we call it. With a remote procedure, the exactly once aspect is quite difficult to achieve. A remote procedure may be executed:
- 0 times if the server crashed or process died before running the server code.
- once if everything works fine.
- once or more if the server crashed after returning to the server stub but before sending the response. The client won’t get the return response and may decide to try again, thus executing the function more than once. If it doesn’t try again, the function is executed once.
- more than once if the client times out and retransmits. It is possible that the original request may have been delayed. Both may get executed (or not).
RPC systems will generally offer either at least once or at most once semantics or a choice between them. One needs to understand the nature of the application and function of the remote procedures to determine whether it is safe to possibly call a function more than once. If a function may be run any number of times without harm, it is idempotent(e.g., time of day, math functions, read static data). Otherwise, it is a nonidempotent function (e.g., append or modify a file).
What about performance?
A regular procedure call is fast: typically only a few instruction cycles. What about a remote procedure call? Think of the extra steps involved. Just calling the client stub function and getting a return from it incurs the overhead of a procedure call. On top of that, we need to execute the code to marshal parameters, call the network routines in the OS (incurring a mode switch and a context switch), deal with network latency, have the server receive the message and switch to the server process, unmarshal parameters, call the server function, and do it all over again on the return trip. Without a doubt, a remote procedure call will be much slower. We can easily expect the overhead of making the remove call to be thousands of times slower than a local one. However, that should not deter us from using remote procedure calls since there are usually strong reasons for moving functions to the server.
What about security?
This is definitely something we need to worry about. With local procedures, all function calls are within the confines of one process and we expect the operating system to apply adequate memory protection through per-process memory maps so that other processes are not privy to manipulating or examining function calls. With RPC, we have to be concerned about various security issues:
-
Is the client sending messages to the correct remote process or is the process an impostor?
-
Is the client sending messages to the correct remote machine or is the remote machine an impostor?
-
Is the server accepting messages only from legitimate clients? Can the server identify the user at the client side?
-
Can the message be sniffed by other processes while it traverses the network?
-
Can the message be intercepted and modified by other processes while it traverses the network from client to server or server to client?
-
Is the protocol subject to replay attacks? That is, can a malicious host capture a message an retransmit it at a later time?
-
Has the message been accidentally corrupted or truncated while on the network?
链接:https://www.zhihu.com/question/25536695/answer/221638079
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
本地过程调用
RPC就是要像调用本地的函数一样去调远程函数。在研究RPC前,我们先看看本地调用是怎么调的。假设我们要调用函数Multiply来计算lvalue * rvalue的结果:
1 int Multiply(int l, int r) {
2 int y = l * r;
3 return y;
4 }
5
6 int lvalue = 10;
7 int rvalue = 20;
8 int l_times_r = Multiply(lvalue, rvalue);
那么在第8行时,我们实际上执行了以下操作:
- 将 lvalue 和 rvalue 的值压栈
- 进入Multiply函数,取出栈中的值10 和 20,将其赋予 l 和 r
- 执行第2行代码,计算 l * r ,并将结果存在 y
- 将 y 的值压栈,然后从Multiply返回
- 第8行,从栈中取出返回值 200 ,并赋值给 l_times_r
以上5步就是执行本地调用的过程。(20190116注:以上步骤只是为了说明原理。事实上编译器经常会做优化,对于参数和返回值少的情况会直接将其存放在寄存器,而不需要压栈弹栈的过程,甚至都不需要调用call,而直接做inline操作。仅就原理来说,这5步是没有问题的。)
远程过程调用带来的新问题
在远程调用时,我们需要执行的函数体是在远程的机器上的,也就是说,Multiply是在另一个进程中执行的。这就带来了几个新问题:
- Call ID映射。我们怎么告诉远程机器我们要调用Multiply,而不是Add或者FooBar呢?在本地调用中,函数体是直接通过函数指针来指定的,我们调用Multiply,编译器就自动帮我们调用它相应的函数指针。但是在远程调用中,函数指针是不行的,因为两个进程的地址空间是完全不一样的。所以,在RPC中,所有的函数都必须有自己的一个ID。这个ID在所有进程中都是唯一确定的。客户端在做远程过程调用时,必须附上这个ID。然后我们还需要在客户端和服务端分别维护一个 {函数 <--> Call ID} 的对应表。两者的表不一定需要完全相同,但相同的函数对应的Call ID必须相同。当客户端需要进行远程调用时,它就查一下这个表,找出相应的Call ID,然后把它传给服务端,服务端也通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。
- 序列化和反序列化。客户端怎么把参数值传给远程的函数呢?在本地调用中,我们只需要把参数压到栈里,然后让函数自己去栈里读就行。但是在远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数。甚至有时候客户端和服务端使用的都不是同一种语言(比如服务端用C++,客户端用Java或者Python)。这时候就需要客户端把参数先转成一个字节流,传给服务端后,再把字节流转成自己能读取的格式。这个过程叫序列化和反序列化。同理,从服务端返回的值也需要序列化反序列化的过程。
- 网络传输。远程调用往往用在网络上,客户端和服务端是通过网络连接的。所有的数据都需要通过网络传输,因此就需要有一个网络传输层。网络传输层需要把Call ID和序列化后的参数字节流传给服务端,然后再把序列化后的调用结果传回客户端。只要能完成这两者的,都可以作为传输层使用。因此,它所使用的协议其实是不限的,能完成传输就行。尽管大部分RPC框架都使用TCP协议,但其实UDP也可以,而gRPC干脆就用了HTTP2。Java的Netty也属于这层的东西。
所以,要实现一个RPC框架,其实只需要把以上三点实现了就基本完成了。
Call ID映射可以直接使用函数字符串,也可以使用整数ID。映射表一般就是一个哈希表。
序列化反序列化可以自己写,也可以使用Protobuf或者FlatBuffers之类的。
网络传输库可以自己写socket,或者用asio,ZeroMQ,Netty之类。