先来点理论基础
系统crash时,HPUX会尝试将物理内存(core)或是物理内存的部分的映像保存到dump设备上,这个dump设备是预先定义好的。然后,在紧接着的操作系统重起过程中,名为savecrash的工具被rc-script自动调用,将内存映像及当前kernel由dump设备拷贝到文件系统中。完成后,你就可以通过调试工具对其进行分析。如下图.
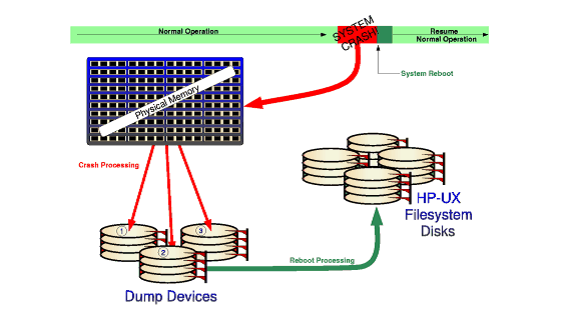
Crash事件 - Crash events
一个非正常的系统重起就叫做crash. 有很多原因会导致系统crash; 硬件的不正常工作,软件混乱甚至电源故障。 在一个正确配置的系统中,这些通常会导致一个crash dump被保存下来。操作系统记录每个crash事件的原因,通常每个CPU都会有一个crash事件。同一个CPU有多个事件也是可能的。
共有三种类型的Crash: PANIC, TOC and HPMC:
PANIC
PANIC类型的crash说明这是由HPUX 操作系统触发的(软件Crash事件). 我们将它分为直接panic与非直接panic(direct and indirect panics).
直接panic是由一个子系统在检测到一个不可恢复的错误时直接调用panic()核心进程,例如:
. panic ("wait_for_lock: Already own this lock!");
. panic ("m_free: freeing free mbuf");
. panic ("virtual_fault: on DBD_NONE page");
. panic ("kalloc: out of kernel virtual space");
非直接panic是由操作系统无法处理的陷阱中断引起。例如kernel试图访问一个非法地址,一个Data page fault(陷阱类型15,trap type 15)会被触发。陷阱处理机制会保存状态信息后调用panic()进程。它被称之为非直接panic是因为panic()进程是在稍晚于触发陷阱条件的时刻发生的。
例如:
. trap type 15, Data page fault
. trap type 18, Data memory protection fault
. trap type 6, Instruction page fault
TOC
TOC类型的crash是由一个Transfer-Of-Control序列触发的。
有三种方式触发一个TOC:
.由管理员主动触发的 (有些机器上有TOC按钮;有些机器上反复将电源开关三次,这么有才的设计黄金甲记得只在当年D/R系列的机器上有过;或是在控制台上敲TC命令,现在还活着的机器一般都是用的MP卡,敲CTRL+B进去后,再进CM,然后TC。没有准备好停机别试,别说我没提醒你)
. MC/SG触发 (无法与cmcld后台进程通讯时)
. Crash过程中触发的TOC.在多CPU系统中,如果一个CPU先开始一个Crash事件(比如说是因为Panic),那么其他的CPU会自动TOC.
通常在系统挂起时,你才会去手动触发一个TOC,这样,通过分析crash dump,可以有助于分析挂起的真正原因。
HPMC
HPMC类型的crash事件是因为发生了High Priority Machine Check,HPMC通常是由硬件故障引发的,比如说数据缓存校验错。发生HPMC并不总是意味着硬件损坏,需要通过分析HPMC tombstone 来确定真正的原因。软件故障是可以触发HPMC的,当然在生产系统中这极为罕见。
注意:在安腾平台术语的命名有些许不同:
HPMC = MCA (Machine Check Abort)
TOC = INIT
系统Crash时发生了什么?
现在你知道Crash事件的不同类型了(panic,toc,HPMC).咱们看看系统是如何处理这些事件的。处理这些事件需要OS与硬件的配合,例如PDC(firmware)与IVA(Interruption Vector Table,系统kernel中的中断矢量表)等等。这些接口使得硬件可以在发生故障时触发软件入口程序来记录、分析、修复错误。
这里写的有些东东在第一遍读的时候可能觉得有点深,你可以先略过它,重点是先抓住概念。因为Dump分析总是由crash事件开始,了解系统是如何处理crash事件、哪些重要信息被保存以及保存在哪里是值得的。
我们将crash事件分为两类:硬件crash事件和软件crash事件。
硬件crash事件
硬件crash事件可以是HPMC,LPMC,或是TOC.HPMC/LPMC通常是由于硬件工作不正常或是特定类型的总线错误引起。另一方面,TOC通常是由管理员在系统软件卡在某个错误状态时触发。
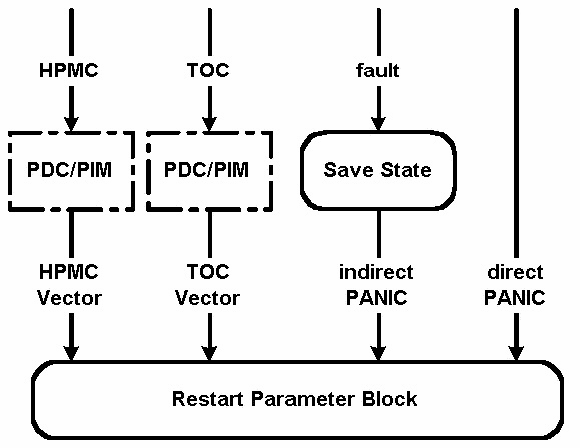
硬件crash事件出现时,CPU立刻执行到相应的PDC(firmware)入口处; 与HPMC/LPMC对应的是PDCE_CHECK, 与TOC对应的是PDCE_TOC. 具体的实现过程与CPU相关,大致上来说它们将CPU的状态(通用、控制、地址、中断等各种寄存器)保存到PIM(Processor Internal
Memory )中。然后CPU再返回到操作系统中的相应入口处;HPMC_Vector 或是TOC_Vector. 这些入口分别定义在IVA (Interruption Vector Table) 和Page Zero的MEM_TOC. (黄按:我的理解是HPMC vector在IVA中,TOC vector在Page Zero中某处。Page Zero无上下文可供参考,望文生义可能是OS管理的第一块内存,存放一些特殊的信息)
在kernel中进入相应入口处,生成一个crash事件的相应记录。操作系统通过一个系统调用PDC_PIM来将由PIM中读取的CPU状态信息写入一个数据结构RPB(Restart Parameter
Block ),这个数据结构有用于分析crash的相关信息。例如,RPB中的PC(Program Counter)就指示HPMC/TOC发生时,哪一个程序正在执行。相关信息保存完毕后,操作系统开始将物理内存中的信息保存到dump设备上。
软件crash事件
软件crash事件在panic()过程被调用时发生。这可能是直接panic,也可能是间接panic. 对于一个软件crash事件,PDC和PIM完全不会被引入(不相关)。
因此,panic()过程做的第一件事情是将CPU状态保存到RPB中。 触发Panic的CPU会使其他CPU进行TOC操作,使它们在故障点附近停止继续工作。这对查找panic的原因有重要意义。
Panic()过程实际是调用名为panic_save_register_state()的子过程来保存CPU状态信息,所以RPB结构中的rp(return pointer)实际上是指向panic()过程。pcoq (instruction address)被清零,防止回溯到panic发生以前,因为当前时间点才是有意义的。因为panic_save_register_state()是一个子过程,所以RPB结构中的sp(stack
Pointer)与panic()的是一样的.
对于一个直接panic,RPB中包含调用panic()过程的程序的CPU状态。换句话说,RPB中包含错误发生最近时间点时的信息,而且与调用panic()的程序有相同的上下文。所以对直接panic的分析就从RPB开始。
对于一个非直接panic,RPB中包含的上下文是陷阱的处理程序(trap handler),所以它并不直接反映故障时的CPU状态。非直接panic通常是操作系统遇到无法处理的陷阱条件的结果。陷阱处理程序在调用panic()之前需要保存CPU状态信息,它把这些状态信息保存在一个save_state数据结构中。 所以对一个非直接panic来说,save_state数据结构中的信息是最接近故障点的。对非直接panic的Dump分析要从save_state数据结构开始。
panic()过程保存CPU状态后,开始将物理内存的内容写到dump设备上。
PIM Tombstone
Process Internal Memory 或是说PIM是CPU中的一个存储空间,在HPMC/LPMC或TOC发生时被置位,包含有错误参数与CPU型号相关的区域。不同的CPU有不同的PIM,PDC_PIM过程用来访问PIM。
不同的系统有不同的方式来访问PIM信息。有些系统可以通过pdcinfo程序在线访问PIM信息,这样有助于收集HPMC tombstone数据进行分析。脚本/sbin/init.d/pdcinfo自动在系统启动过程中运行pdcinfo命令将tombstones保存在/var/tombstones目录下。最多可以保存100个文件。“ts99”是最新的一个文件,“ts98”是次新的,依此类推… “ts0”就是最旧的。
从dump分析的角度来看,尤其是HPMC/TOC,RPB结构应该是PIM中寄存器状态的拷贝。在个别情况下RPB结构中的值看起来好像’不对’. 如果这样的话,从PIM中寄存器状态开始分析。一些有趣的寄存器如下:
gr02 Return Pointer (rp)
gr30 Stack Pointer (sp)
cr17 Interruption Instruction Address Space Queue (pcsq)
cr18 Interruption Instruction Address Offset Queue (pcoq)
cr19 Interruption Instruction Register (iir)
cr20 Interruption Space Register (isr)
cr21 Interruption Offset Register (ior)
cr22 Interruption Processor Status Word (ipsw)
cr23 External Interrupt Request Register (eirr)
cr15 External Interrupt Enable Mask (eirr)
Save state structure
save_state数据结构又中断处理程序和陷阱处理程序用来暂时存储CPU状态,然后这些处理程序就可以放心地使用CPU寄存器。这也允许处理程序通过将save_state中的值恢复到CPU寄存器中来返回中断现场。 save_state 数据结构通常在ICS(Interrupt Control Stack)或是kernel stack中申请空间。
大部分寄存器的值被保存下来。但是,有些寄存器因为在中断返回后没什么关联,所以不进行保存。这样处理的目的是因为中断和陷阱处理器经常会被执行,只保存必要的信息对提高性能很重要。
RPB structure
每一个crash事件会产生相应的RPB数据结构来包含HPMC、TOC、Panic时的CPU状态。这些状态信息帮助我们理解当时正在发生什么,也提供了一个回溯的起点。RPB数据结构的空间是在kernel的静态数据空间中预先分配好的。
不像save_state数据结构,RPB中保存的信息更完整,包括了所有的寄存器信息。例如
cr16 interval timer 保存在RPM中,save_state structure中就没有。这是因为这个操作是在crash过程中,不会带来性能的问题。
Crash event flowchart
如何配置Dump设备
要理解下述过程你需要对LVM有些基础的概念。下面是用到的缩写:
VG = Volume Group
LV = Logical Volume
PV = Physical Volume
选择 dump设备
Dump设备是硬盘上的卷用来在系统crash时保存整个内存映像。所有指定的Dump设备累加的空间应该比物理内存要大一点才能确保保存完整的映像。要确认物理内存的大小,可以:
# dmesg | grep Physical
Physical:524288 KB ,lockable:386672 KB ,available:454144 KB
在11.00以后可以用crashconf(1M):
# crashconf | grep Total
Total pages on system: 131072
Total pages included in dump: 30832
(以‘页’为单位,一‘页’总是4KB大小)
NOTE: 在添加物理内存后增加dump空间的大小很重要。
以前dump设备的大小最大为2GB或者更精确地说:dump LV必须在一个PV的前2GB空间内。HPUX11.0以后支持大于4GB的dump设备。
重要的是由IO接口卡,而不是硬盘本身决定是否这个硬盘可以支持4GB以上的Dump. (黄按:很老的文档了,我打赌现在还能运行的系统里已经没有上述所说的限制了)
一个用来做交换区的设备也可以被用来做dump设备,这样可以节约磁盘空间,但是有两个负面的影响:
1) 如果主交换设备(通常是 /dev/vg00/lvol2)被配置为dump设备,系统重起时需要更长的时间。
原因: 系统启动过程中,如果发现有dump存在,需要将它写在文件系统中
(通过rc 命令 savecrash).如果dump设备也是主交换设备,那savecrash就不可以在后台工作因为正常启动过程swap上的内容可能会被覆盖。
2) 如果savecrash没成功 (比如说用来保存crash dump的文件系统满了),你还有机会在系统启动结束后重新尝试保存(-r 选项用来重新保存)。 交换设备可能会因为“swapping”操作覆盖掉部分,那dump可能就不能用了。
你可以通过修改控制文件来调整savecrash和 swapon. (man savecrash/core -w option)
配置步骤
生成一个用来做dump的LV
你可以指定最多32个dump设备,每一个都必须连续,就是说数据块是一个挨一个的。
这是通过lvcreate命令的-C y参数实现的。
坏块重定位必须被关闭 (–r n):
# lvcreate -L <size in MB> -n lvdump -C y –r n /dev/vg00
你可以通过lvdisplay命令来检查LV的参数
# lvdisplay /dev/vg00/lvdump | grep Allocation
Allocation strict/contiguous
# lvdisplay /dev/vg00/lvdump | grep Bad
Bad block off
用来做dump的LV上当然不能有文件系统。
激活LV,告诉系统使用它做dump. 传统的dump LV必须在vg00,用lvlnboot命令设为dump device. 要激活新的dump设备需要重起系统。
显示当前配置:
# lvlnboot -v
Boot Definitions for Volume Group /dev/vg00:
Physical Volumes belonging in Root Volume Group:
/dev/dsk/c0t6d0 (10/0.6.0) -- Boot Disk
/dev/dsk/c0t5d0 (10/0.5.0)
Root: lvol1 on: /dev/dsk/c0t6d0
Swap: lvol2 on: /dev/dsk/c0t6d0
No Dump Logical Volume configured
用 -d 参数指定dump设备:
# lvlnboot -d lvol2 /dev/vg00
# lvlnboot -d lvdump /dev/vg00
检查:
# lvlnboot -v | grep dump
Dump: lvol2 on: /dev/dsk/c0t6d0, 0
Dump: lvdump on: /dev/dsk/c0t6d0, 1
如果配置正确,重起系统使之生效。重起后,message buffer中会列出有效的dump 设备。
# dmesg | grep DUMP
Logical volume 64, 0x2 configured as DUMP
Logical volume 64, 0x9 configured as DUMP
如果你想将一个dump设备用做其他用途,可以使用lvrmboot命令.只有最后添加的dump设备可以被去除。
# lvrmboot -d lvdump /dev/vg00
NOTE:如果使用超过一个传统的dump设备,系统kernel(/stand/vmunix)中需要设置一个参数。这个参数默认是设置了的。
# strings /stand/vmunix | grep "dump lvol"
dump lvol
从HPUX 11.0开始可以在线增加dump设备,不再需要重起。这些dump LV一定不可以用lvlnboot-d 命令来设置,而应使用crashconf(1M). 你也可以指定VG00以外的LV来做dump. 配置步骤与增加额外的swap设备类似。
步骤如下:
在/etc/fstab增加一行,如下例:
/dev/vg01/lvdump / dump defaults 0 0
然后运行crashconf -a 激活,用crashconf 验证.
细节可参考crashconf(1m)和fstab的man page.
NOTE: 如果你有dump设备,并且不用来做swap,确保最后加入该设备。这将确保它被最先用到(dump使用的顺序是由后往前),这样最大限度地避免dump被写到一个swap设备上,这将延缓系统重起的过程,上面解释过原因。
NOTE:经常会有这样的问题:“为什么dump LV不像/,stand和swap那样做mirror?”
# lvlnboot -v
Boot Definitions for Volume Group /dev/vg00:
Physical Volumes belonging in Root Volume Group:
/dev/dsk/c0t6d0 (10/0.6.0) -- Boot Disk
/dev/dsk/c0t5d0 (10/0.5.0) -- Boot Disk
Root: lvol1 on: /dev/dsk/c0t6d0
/dev/dsk/c0t5d0
Swap: lvol2 on: /dev/dsk/c0t6d0
/dev/dsk/c0t5d0
Dump: lvol2 on: /dev/dsk/c0t6d0, 0
Dump: lvdump on: /dev/dsk/c0t6d0, 1
答案是:dump是一个低级的过程,跳过了LVM层。而mirror显然是在LVM层实现的。操作系统的实现实际上是记录了硬盘的硬件地址,与开始、结束的位置而已。这也是为什么dump区必须严格连续的原因。