1. 下载好IDEA HADOOP SPARK
首先,配置IDEA, 在插件管理中使用IDEA在线库安装scala插件, 在在线库直接搜索即可;
其次,配置Maven选项, 将Maven添加到IDEA;
<mirrors>
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
</mirrors>
最后,将windows依赖覆盖原先的linux依赖, 如下图;
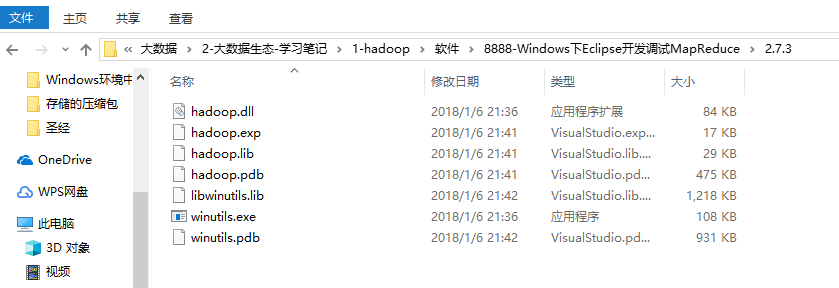
将其中的hadoop.dll 拷贝至 C:WindowsSystem32目录下
2. 向IDEA导入HADOOP jar包, 将本地hadoop下的, share目录中的五个文件夹导入, 如下图:
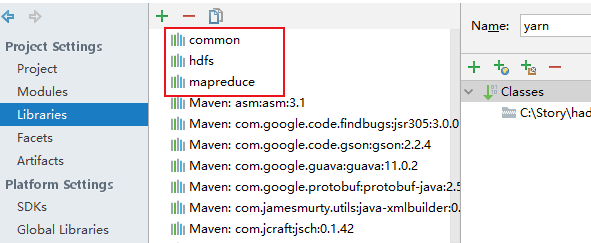
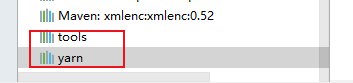
将配置文件放入resources后,运行一些测试程序后发现:

报错:
org.apache.hadoop.security.AccessControlException: Permission denied
解决: hadoop fs -chmod -R 755 /
另外: 在pom中需加入:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
最严重的如下, 因为我使用的mapred默认是yarn模式, 因此需要设置跨平台发送jar包:
Exception message: /bin/bash: line 0: fg: no job control
解决:
Configuration conf = new Configuration();
conf.set("mapred.remote.os","Linux");
conf.set("mapreduce.app-submission.cross-platform","true");
conf.set("mapred.jar","D:\WorkSpace\Web-DataAnalyze\pc\out\artifacts\pc\pc.jar");

终于能run了!!!
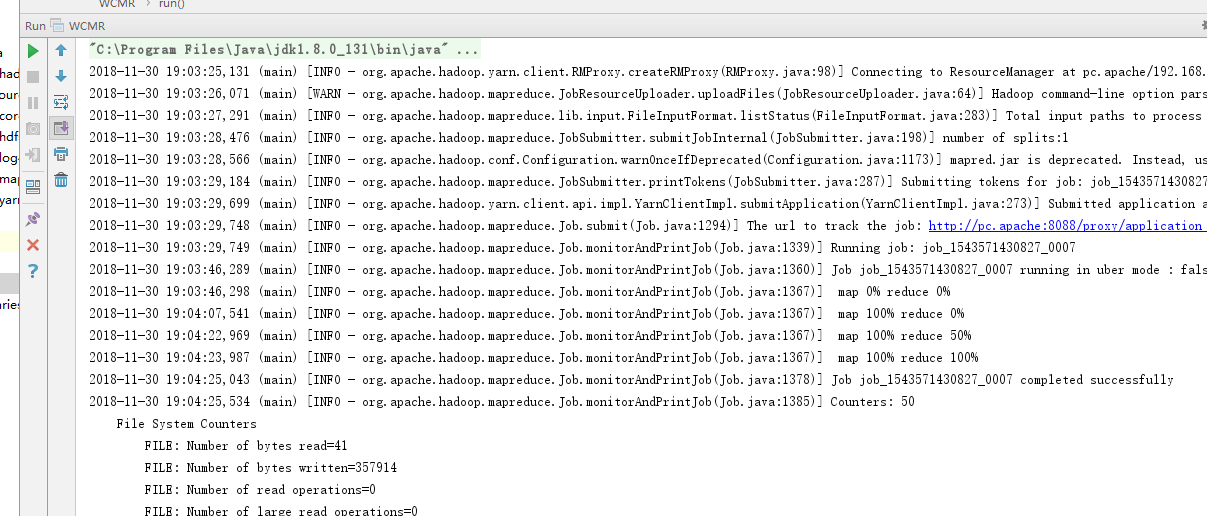
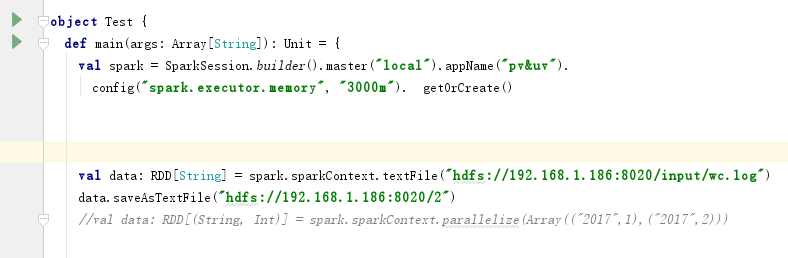
2. 测试SPARK, 在IDEA中建立SCALA工程, 并新建一个pom.xml转为Maven工程;
最后, 将 Spark项目下的jars导入IDEA即可, 完成测试;
3. Cannot run program "git"
yum install git
git --version