一、随机森林是什么?
随机森林是一种多功能的机器学习算法,能够执行①回归和②分类的任务,
同时也是一种③数据降维手段,用于处理缺失值、异常值等
担任了集成学习中的重要方法,可以将④几个低效模型整合为一个高效模型
在随机森林中,我们将生成很多的决策树,并不像在CART模型中只生成唯一的树
1)分类 => 当在基于某些属性对一个新对象进行分类判别时,随机森林中的每一颗树都会给出自己的分类选择,并由此进行“投票”,森林整体的输出结果是的票数最多的分类选项
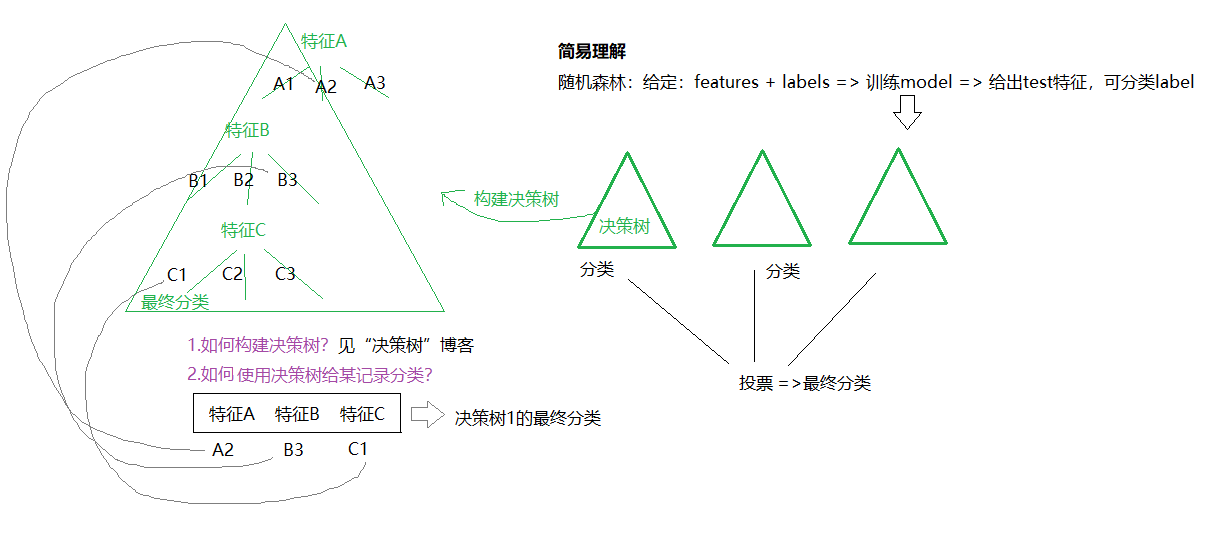
2)回归 => 而在回归问题中,随机森林的输出将会是所有决策树输出的平均值
随机森林现实意义:
现实情况下,一个数据集中往往有成百上千个特征,如何在其中选择比结果影响最大的那几个特征,以此来【缩减建立模型时特征数】是我们比较关心的问题。
这样的方法其实很多,比如主成分分析,lasso等等。不过这里我们学习的是用随机森林来进行特征筛选。
二、随机森林详细
1)随机森林生成方式
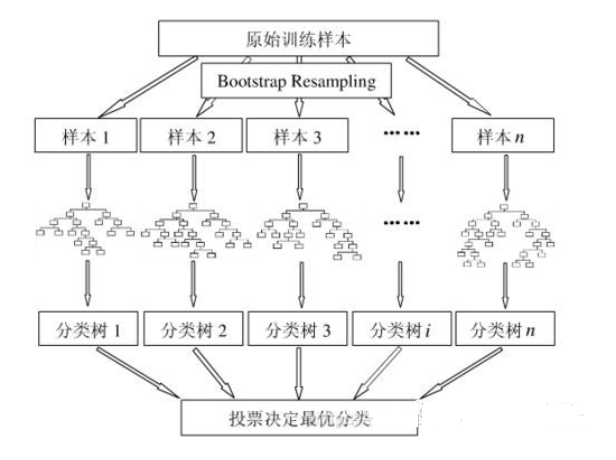
- 从样本集中通过bootstrap的方式产生n个样本。
- 假设样本特征数目为a,对n个样本选择a中的k个特征,用建立决策树的方式获得最佳分割点。
- 在CART每次branching的时候随机抽取一部分特征计算Gini impurity或均方误差来选择best split feature(RF作者使用的这种方法)
- 每棵树都是解决一部分问题的专家
- 重复m次,产生m棵决策树。
- 多数投票机制进行预测。
Q1.随机森林中的随机是什么意思?
- 随机采样:随机森林在计算每棵树时,从全部训练样本(样本数为n)中选取一个可能有重复的、大小同样为n的数据集进行训练(即booststrap采样)。
- 特征选取的随机性:在每个节点随机选取所有特征的一个子集,用来计算最佳分割方式。
2)随机森林的优点
- 表现性能好,与其他算法相比有着很大优势。
- 随机森林能处理很高维度的数据(也就是很多特征的数据),并且不用做特征选择。
- 在训练完之后,随机森林能给出哪些特征比较重要。
- 训练速度快,容易做成并行化方法(训练时,树与树之间是相互独立的)。
- 在训练过程中,能够检测到feature之间的影响。
- 随机森林算法有很强的抗干扰能力(具体体现在6,7点)。所以当数据存在大量的数据缺失,用RF也是不错的。
- 对于不平衡数据集来说,随机森林可以平衡误差。当存在分类不平衡的情况时,随机森林能提供平衡数据集误差的有效方法。
- 如果有很大一部分的特征遗失,用RF算法仍然可以维持准确度。
- 随机森林抗过拟合能力比较强(虽然理论上说随机森林不会产生过拟合现象,但是在现实中噪声是不能忽略的,增加树虽然能够减小过拟合,但没有办法完全消除过拟合,无论怎么增加树都不行,再说树的数目也不可能无限增加的。)
- 随机森林能够解决分类与回归两种类型的问题,并在这两方面都有相当好的估计表现。(虽然RF能做回归问题,但通常都用RF来解决分类问题)。
- 在创建随机森林时候,对generlization error(泛化误差)使用的是无偏估计模型,泛化能力强。
3)随机森林的缺点
- 随机森林在解决回归问题时,并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续的输出。当进行回归时,随机森林不能够做出超越训练集数据范围的预测,这可能导致在某些特定噪声的数据进行建模时出现过度拟合。(PS:随机森林已经被证明在某些噪音较大的分类或者回归问题上回过拟合)。
- 对于许多统计建模者来说,随机森林给人的感觉就像一个黑盒子,你无法控制模型内部的运行。只能在不同的参数和随机种子之间进行尝试。
- 可能有很多相似的决策树,掩盖了真实的结果。
- 对于小数据或者低维数据(特征较少的数据),可能不能产生很好的分类。(处理高维数据,处理特征遗失数据,处理不平衡数据是随机森林的长处)。
- 比决策树算法更复杂,计算成本更高。
- 由于其本身的复杂性,它们比其他类似的算法需要更多的时间来训练
PS:最后几个重要的点
1. RF采用多个决策树的投票机制来改善决策树。
2. 为什么不能用全样本去训练m棵决策树?
答:全样本训练忽视了局部样本的规律,对于模型的泛化能力是有害的(如果有m个决策树,那就需要m个一定数量的样本集来训练每一棵树)
3.产生n个样本的方法,采用Bootstraping法,这是一种又放回的抽样方法,产生n个样本。
4.最终采用Bagging的策略来获得,即多数投票机制。
适用于:抹平异常值
三、极限森林定义
数据集:极限森林和随机森林类似,但是在每一个决策树的采样上不同,RF是随机采取训练样例的部分数据,而极限森林中每一个决策树都采用原始训练集;
特征选取:同时,RF在每一个决策树上,都会选取最优特征值划分点,而极限森林会随机选取一个特征值来进行划分。
优点
- 规模大。
由于随机选择了特征值的划分点位,而不是最优点位,这样会导致生成的决策树的规模一般会大于RF所生成的决策树
- 泛化能力好。
适用于:不知哪个特征重要
四、sklearn代码和参数解释
#-*-coding:gb2312-*- import numpy as np import sklearn.datasets as dt from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier,ExtraTreesClassifier from sklearn.model_selection import train_test_split,cross_val_score if __name__ == '__main__': data = dt.load_iris(True) # 有4个特征 ,If True, returns ``(data, target)`` train_data,train_label = data[0],data[1] # # Code Text # train_data 待划分的样本特征集合 # train_label 待划分的样本标签 # test_size 若在0~1之间,为测试集样本数目与原始样本数目之比;若为整数,则是测试集样本的数目。 # random_state 随机数种子 # x_train 划分出的训练集数据(返回值) # x_test 划分出的测试集数据(返回值) # y_train 划分出的训练集标签(返回值) # y_test 划分出的测试集标签(返回值) # x_train,x_test,y_train,y_test = train_test_split(train_data,train_label,test_size=0.2,random_state=1024) # DecisionTree tree = DecisionTreeClassifier(criterion='entropy') print(cross_val_score(tree,x_train,y_train,cv=10).mean()) # cv: 交叉验证折数或可迭代的次数 # RandomForest # n_estimators确定用于构造的树的个数 # 要在可承受的内存/时间内选取尽可能大的 n_estimators rf = RandomForestClassifier(n_estimators=128,criterion='entropy') # 2^x 以2的次方吞吐,对cpu资源利用好,不浪费 64 -> 一次64字节 print(cross_val_score(rf,x_train,y_train,cv=10).mean()) # ExtraForest ef = ExtraTreesClassifier(n_estimators=128,criterion='entropy') print(cross_val_score(ef,x_train,y_train,cv=10).mean()) # 特征太少体现不出区别
随机森林的分类学习器为RandomForestClassifier,回归学习器为RandomForestRegressor
RandomForestClassifier( n_estimators=10, criterion=’gini’, max_depth=None,min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’,max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None)
参数解释:
控制bagging框架的参数
- estimators:随机森林中树的棵树,即要生成多少个基学习器(决策树)。
- boostrap:是否采用自助式采样生成采样集。
- obb_score:是否使用袋外数据来估计模型的有效性。
控制决策树的参数
- criterion:选择最优划分属性的准则,默认是"gini",可选"entropy"。
- max_depth:决策树的最大深度
- max_features:随机抽取的候选划分属性集的最大特征数(属性采样)
- min_samples_split:内部节点再划分所需最小样本数。默认是2,可设置为整数或浮点型小数。
- min_samples_leaf:叶子节点最少样本数。默认是1,可设置为整数或浮点型小数。
- max_leaf_nodes:最大叶子结点数。默认是不限制。
- min_weight_fraction_leaf:叶子节点最小的样本权重和。默认是0。
- min_impurity_split:节点划分最小不纯度。
其他参数:
- n_jobs:并行job的个数
- verbose:是否显示任务进程
可调用方法:
- predict_proba:计算预测的概率值
- predict(x):预测
- predict_log_proba(x):计算出预测的对数概率值
可调用的属性:
- estimators_:列出决策树参数
- feature_importances_:列出变量重要性
- n_features:
- n_outputs_:
- obb_score_:袋外数据测试效果
- obb_prediction_:袋外数据预测结果