本系列会介绍OpenStack 企业私有云的几个需求:
- 自动扩展(Auto-scaling)支持
- 多租户和租户隔离 (multi-tenancy and tenancy isolation)
- 混合云(Hybrid cloud)支持
- 主流硬件支持、云快速交付 和 SLA 保证
- 大规模扩展性支持
- 私有云外围环境支持(包括支持CDN 、商业SDN控制器、防火墙和VPN/专线等)
- 良好的可使用性(用户和运维 Dashboard 等)
- 向上扩展性(PaaS 和 SaaS 等支撑)
- 企业数据中心IT环境支持(包括裸金属/Bare metal、F5 、GPU、跨云网络连通、租户计费、备份等支持)
- 行业解决方案
- 独立的服务,包括培训、运维等
内容比较多,很多东西也没有确定的内容。想到哪就写到哪吧。先从 GPU 支持开始。
1. 基础知识
1.1 VGA(图像显示卡),Graphics Card(图形加速卡),Video Card(视频加速卡),3D Accelerator Card 和 GPU(图形处理器)
对这些概念之前也没怎么了解,这次正好自己梳理一下。从一篇古老的文章中,找到所谓的显卡从 VGA 到 GPU 发展史:
- 第一代显卡:支持 256 色显示的 VGA Card,1988年。VGA Card的唯一功能就是输出图像,真正的图形运算全部依赖CPU,所以当微软 Windows 操作系统出现后,PC 的 CPU 就开始不堪重负了。
- 第二代显卡:Graphics Card,支持 Windows 图形加速,1991年,通过一颗专用的芯片来处理图形运算,从而将 CPU 部分解放了出来,让Windows界面运行起来非常流畅,从此图形化操作系统资源消耗大降、实用性大增。为了与单纯具备显示功能的 VGA Card 相区别,具备图形处理能的显卡被称为Graphics Card,也就是图形加速卡,它加速了Windows的普及,让PC走进了图形化界面时代。
- 第三代显卡:Video Card,支持视频加速,1994年。为了与单纯具备图形加速能力的 Graphics Card 相区别,具备视频辅助解码的显卡被称为 Video Card,也就是视频加速卡。
- 第四代显卡:3D Accelerator Card,1994年。后起之秀 NVIDIA 则凭借性能强大的单芯片TNT和TNT2系列显卡超越3DFX 从而脱颖而出。
- 第五代显卡:GPU 图形处理器,支持硬件T&L,1999年。GeForce 256是一款划时代的产品,NVIDIA 将其称为第一款GPU(Graphic Processing Unit,图形处理器),显示芯片上升到了与CPU(Center Processing Unit,中央处理器)同样的高度。GeForce 256是被作为一个图形处理单元(GPU)来设计的,GPU是一个单芯片处理器。它有完整的转换、光照、三角形设置和渲染引擎(分别为:Transform、Lighting、Setup、Rendering)等四种3D处理引擎,一些以前必须由CPU来完成的图形运算工作现在可以由GeForce256 GPU芯片独立完成,大多数情况下具有完整的传输和光照相引擎的GPU运算速度比CPU快2-4倍,同时也有效地减轻了CPU的浮点运算负担,减少了对CPU的依赖性。
- 未来的显卡:GPU 接管更多CPU的功能,支持更多的功能,包括几何着色、物理加速、高清解码、科学计算等。
简化一下:
- VGA Card:640×480分辨率彩色图形显示,单纯的输出图像
- Graphics Card:支持图形界面加速,减轻CPU负担
- Video Card:支持视频解码加速,减轻CPU负担
- 3D Accelerator Card:支持3D图形渲染,3D技术走向普及
- GPU:支持坐标转换和光源处理,消除3D渲染的瓶颈
1.2 GPU 与 CPU
从上面的介绍我们知道,GPU 表示 Graphics Processing Unit,即图像处理单元。一开始的时候GPU 主要用于 3D 游戏的渲染,但是现在GPU已经广泛用于加速计算性负载,比如金融模型计算、科学研究以及石油和天然气开发等。从架构上看,CPU 是由若干核(core)和许多的缓存(cache memory)组成,因此CPU可以并行处理若干线程。相对地,GPU是由几百个核组成,因此可以并发处理数千个线程。尽管 GPU 的内核数目远远超过 CPU,但是它的每个核的处理能力远小于CPU的核,而且不具有现代操作系统的所需要的一些特性,GPU 并不合适用于处理普通的计算。它们更多地用于计算消耗性操作,比如视频处理和物理仿真等。这个文档 中包含了目前支持 GPU 的应用列表。
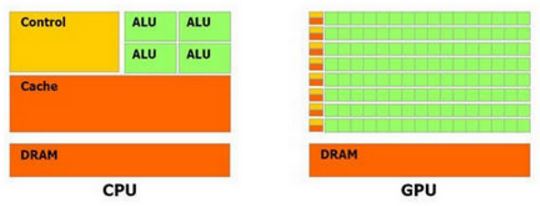
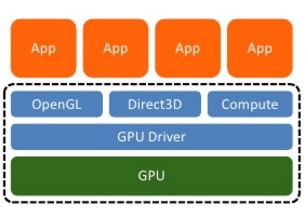
(GPU 和 CPU 对比) (GPU 应用软件栈)
注:Direct3D(简称:D3D)是微软公司在Microsoft Windows操作系统上所开发的一套3D绘图编程界面,是DirectX的一部分,目前广为各家显卡所支持。与OpenGL同为电脑绘图软件和电脑游戏最常使用的两套绘图编程界面之一。
1.3 在虚机内使用 GPU 的几种方式 (GPU 虚拟化)
1.3.1 集中 GPU 虚拟化实现技术
(1)API Remoting (远程API)
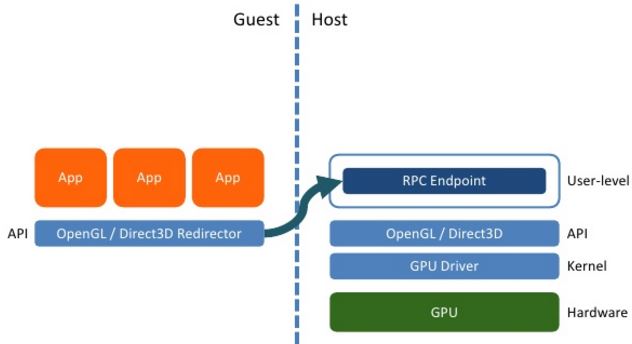
远程API 方法分为前端和后端两个部分。前端以动态库的形式被虚拟机中的CUDA程序加载,后端则是运行在宿主机中的一个程序。在这种机制下,首先由前端将虚拟机中的CUDA API重写,将API的名称和相应参数传递给后端。然后后端为前端每个CUDA应用程序创建一个进程,在该进程中转 换来自前端重写后的API,获得API的名称和参数,接着使用宿主机上真实的GPU硬件设备执行相应的API,最后将 API执行结果返回给前端。
这种方法需要进行大量虚拟机与宿主机之间的数据传输,导致GPU虚拟化的性能严重下降。在CUDA程序规模较小时,这些GPU虚拟化框架的性能下降并不太明显。但在进行实际应用中的高性能计算时性能下降非常明显。
Parallels Desktop 所使用的技术和该技术非常接近。
(2) Device Emulation (GPU 设备仿真)

在客户机中提供一个仿真虚拟GPU,客户机上应用对它的调用都会被仿真层转化为对Hypervisor上物理 GPU 的调用。
(3) 两种 Pass-through (透传)
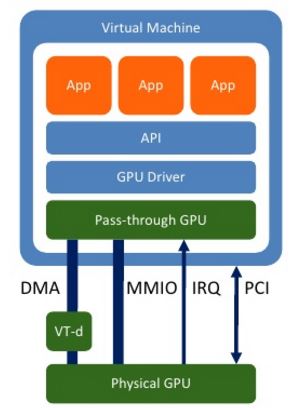
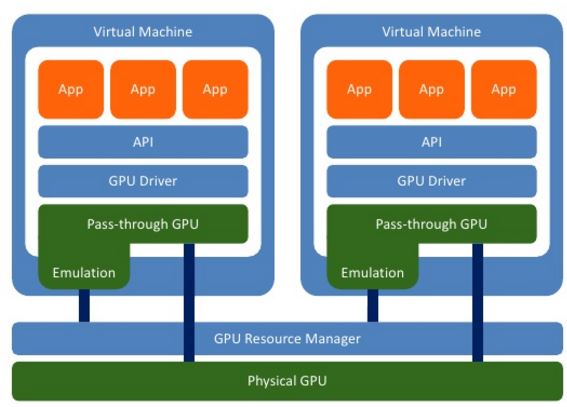
(Fixed pass-through:固定透传,一个 GPU 只能给一个虚机使用) (Mediated pass-through:中介式透传,一个 GPU 可以给多个虚机使用)
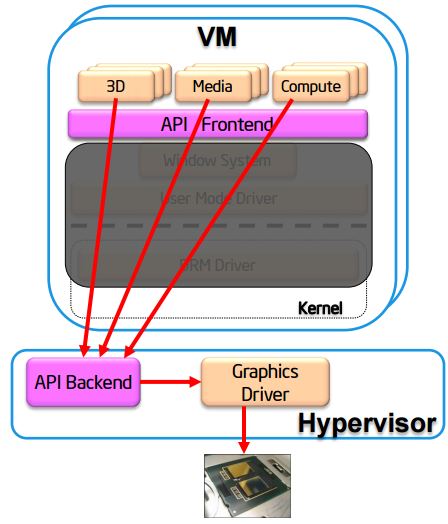
(4)全虚拟化
全虚拟化方案中,每个虚机拥有一个虚拟的GPU实例,多个虚机共享一个物理 GPU。下图是 Intel 的 GPU 全虚拟化示意图:
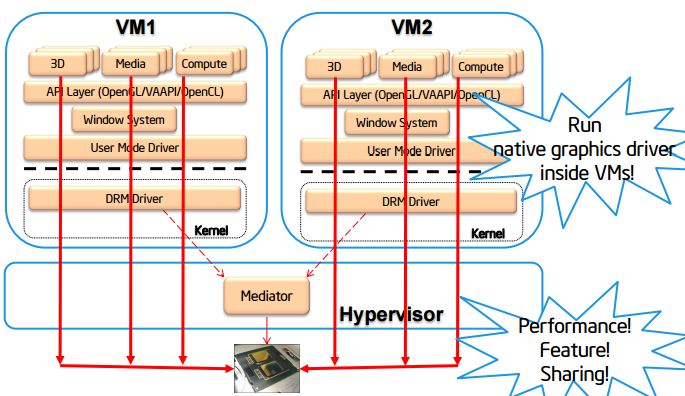
1.3.2 Intel 实现的 GPU 虚拟化
Intel 有如下几种 GPU 虚拟化技术:

三者之间的比较:

第三个最先进,它支持 GPU 全虚拟化,以及在多个虚机之间共享一个物理GPU。目前已经在 Xen 中完整地支持该技术(XenGT 项目)。但是在 KVM 中,KVMGT 是在 KVM 内的实现,但是直到 2014/12月 Intel 才出一个 KVMGT 版本,目前仍然处于初级阶段(资料来源)。

1.3.3 Nvidia 实现的 GPU 全虚拟化
跟 Intel 的情况差不多,Nvidia K1/K2 GPU 也有 GPU 全虚拟化技术,但是目前也是不支持 KVM,而是只支持几家主流的虚拟化软件比如 Hyper-V 和 VMware 等(资料来源)。
1.4 透传(Pass-through)技术
从上面的介绍可以看出,目前主要的 GPU厂商包括 Intel 和 Nvidia 的全虚拟化方案主要还是针对某几种商业虚拟化软件比如 Hyper-V 和 VMware 等,对于 KVM 的支持要么没有,要么还处于早期阶段。鉴于 KVM 在 OpenStack 计算虚拟化层的地位,OpenStack Nova 支持的也只是 GPU 透传给客户机。QEMU/KVM GPU 透传主要有两种实现方式。
1.4.1 两种实现方式
(1)pci-assign 方式
主流地,QEMU/KVM 使用 PCI Assign 技术将KVM主机上的一个 PCI 设备比如 GPU 和 网卡等直接分配给一个虚机。这技术需要 Intel VT-d 或者 AMD IOMMU 硬件支持。下面是一个 Intel 平台上的实现步骤的例子:
# Boot kernel with 'intel_iommu=on' # Unbind driver from the device and bind 'pci-stub' to it echo "168c 0030" > /sys/bus/pci/drivers/pci-stub/new_id echo 0000:0b:00.0 > /sys/bus/pci/devices/0000:0b:00.0/driver/unbind echo 0000:0b:00.0 > /sys/bus/pci/drivers/pci-stub/bind # Then just run sudo qemu-system-i386 -m 1024 -device pci-assign,host=0b:00.0,rombar=0 -enable-kvm -kernel $KERNEL -hda $DISK -boot c -append "root=/dev/sda rw"
(2) VFIO 方式
VFIO 在 Linux kernel3.6/qemu1.4 以后支持,目前只支持 PCI 设备。VFIO 是一套用户态驱动框架,提供两种基本服务:向用户态提供设备访问接口 和 向用户态提供配置IOMMU 接口。 它第一次向用户态开放了 IOMMU 接口,能完全在用户态配置 IOMMU,将 DMA 地址空间映射进而限制在进程虚拟地址空间之内。
VFIO 可以用于实现高效的用户态驱动。在虚拟化场景可以用于 PCI 设备透传。通过用户态配置IOMMU接口,可以将DMA地址空间映射限制在进程虚拟空间中,这对高性能驱动和虚拟化场景device passthrough尤其重要。相对于传统方式,VFIO对UEFI支持更好。VFIO 技术实现了用户空间直接访问设备。无须root特权,更安全,功能更多。
它对环境有如下要求:
- AMD-Vi or Intel VT-d capable hardware
- Linux 3.6+ host
- CONFIG_VFIO_IOMMU_TYPE1=m
- CONFIG_VFIO=m
- CONFIG_VFIO_PCI=m
- modprobe vfio-pci
- Qemu 92e1fb5e+ (1.3 development tree)
1.4.2 透传技术的局限性
透传技术能带来几乎和物理设备同等的性能,但是它也带来了一些局限性。设备透传带来的一个问题体现在实时迁移方面。实时迁移 是指一个 VM 在迁移到一个新的物理主机期间暂停迁移,然后又继续迁移,该 VM 在这个时间点上重新启动。实时迁移是在一个物理主机网络上支持负载平衡的一个很好的特性,但使用透传设备时它会产生问题。PCI 热插拔(有几个关于它的规范)就是需要解决的一个问题。PCI 热插拔允许 PCI 设备从一个给定内核进出,这很理想 — 特别是将 VM 迁移到新主机上的管理程序时(设备需要在这个新管理程序中拔出然后再插入)。当设备被模拟(比如虚拟网络适配器)时,模拟提供一个抽象层以抽象物理硬件。这样,一个虚拟网络适配器可以在该 VM 内轻松迁移(这个 VM 还得到 Linux® 绑定驱动程序的支持,该驱动程序支持将多个逻辑网络适配器绑定到相同的接口上)。
更详细的介绍,可以阅读文档 http://www.linux-kvm.org/images/b/b4/2012-forum-VFIO.pdf。
1.5 公有云上的 GPU 支持
(1)阿里云 GPU 物理机,用于高新能计算
阿里云(来源)为高性能计算提供带 GPU 的物理机,配置如下:
- 双路Xeon E5-2650v2 2.6GHz
- 128G 内存
- Raid5 13T 数据盘
- K40M x2 GPU
该物理机的单机峰值计算能力可达每秒11万亿次单精度浮点运算。
(2)Amazon GPU 虚拟机,可用于 3D 应用程序流、机器学习、视频编码和其他服务器端图形 或 GPU 计算工作等负载,包括 Linux GPU 虚机和 Windows GPU 虚机。虚拟机配置如下:
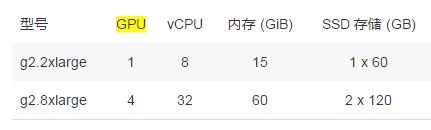 (资料来源)
(资料来源)
2. OpenStack Nova(QEMU/KVM) 对 GPU 的支持
OpenStack 官网的 https://wiki.openstack.org/wiki/Pci_passthrough 文章说明了 Nova 对 GPU 的支持。本章节就从配置和代码等角度来分析Nova是如何支持 GPU 透传的。
2.1 环境准备
可以使用 lspci 命令来获取 GPU PCI 设备:
# lspci -nn | grep NVI 85:00.0 VGA compatible controller [0300]: NVIDIA Corporation GK104GL [GRID K2] [10de:11bf] (rev a1) 86:00.0 VGA compatible controller [0300]: NVIDIA Corporation GK104GL [GRID K2] [10de:11bf] (rev a1)
输出中各个值的说明:
| 输出值 | 含义 | 详细解释 |
| "85:00.0" 和 “86::00.0” | 以 ”bus:slot.func“ 格式来唯一标识一个 PCI 功能设备 |
唯一定位一个 PCI 设备的虚拟功能,可以是一个物理设备,也可以是一个多功能设备的功能设备,一个多功能设备可以最多有8个功能。
|
| ”0300“ | PCI 设备类型 | 指 PCI 设备的类型,来自不同厂商的同一类设备的类型码可以是相同的。 |
| “10de” | 供应商识别字段(Vendor ID) | 该字段用一标明设备的制造者。一个有效的供应商标识由 PCI SIG 来分配,以保证它的唯一性。Intel 的 ID 为 0x8086,Nvidia 的 ID 为 0x10de |
| “11bf” | 设备识别字段(Device ID) | 用以标明特定的设备,具体代码由供应商来分配。本例中表示的是 GPU 图形卡的设备 ID。 |
| “a1” | 版本识别字段(Revision ID) | 用来指定一个设备特有的版本识别代码,其值由供应商提供 |
下图说明了 PCI 域、总线、设备等概念之间的联系(lspci 的输出没有标明域,但对于一台 PC 而言,一般只有一个域,即0号域。):
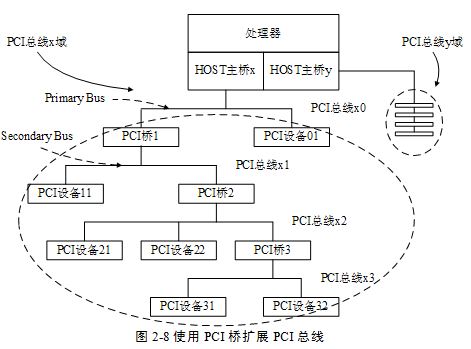 (来源)
(来源)
2.2 KVM主机和Nova 配置
2.2.1 修改 Nova 配置
| 节点 | 配置文件 | 需要修改的配置 | 说明 |
| 控制(API)节点 | /etc/nova/nova.conf | 添加配置项:pci_alias={"vendor_id":"10de", "product_id":"11bf", "name":"a1"} | 这是为了在 Nova flavor 中可以很方便的使用 alias的需要而添加的。 |
| 计算节点 | /etc/nova/nova.conf |
添加配置项:pci_passthrough_whitelist=[{ "vendor_id":"10de","product_id":"11bf"}]
|
并不是一个 计算节点上的所有 PCI 设备都运行被分配给客户机,云管理员可以使用该配置项来指定可以分配的 PCI 设备的范围。
在 Nova 中,PCI 设备可以分为几类:1、普通的 PCI 设备 2. SR-IOV PF 设备 3. SR-IOV VF 设备。通常 SR-IOV PF 设备都是不可以直接分配给客户机的,因此,该配置项是来指定可以分配的 “普通 PCI 设备”以及 “SR-IOV VF” 的范围。
|
| Nova scheduler 节点 | /etc/nova/nova.conf |
scheduler_available_filters=nova.scheduler.filters.all_filters
scheduler_available_filters=nova.scheduler.filters.pci_passthrough_filter.PciPassthroughFilter
修改配置项:scheduler_default_filters=RamFilter,ComputeFilter,AvailabilityZoneFilter,
ComputeCapabilitiesFilter,ImagePropertiesFilter,PciPassthroughFilter
|
增加 PciPassthroughFilter
|
2.2.2 Nova 步骤
(1)创建一个 nova flavor 并设置属性。本例子中直接设置已有 m1.small 的属性:
nova flavor-key m1.small set "pci_passthrough:alias"="a1:1"
其中,
- "pci_passthrough:alias" 是固定的 key 字符串,用于指定该 flavor 对 PCI 设备的需求
- "a1:1" 的格式是 'alias_name_x:count, alias_name_y:count, ... ' ,可以指定多个,每个 alias_name 由 pci_alias 配置项中的 ”name“ 指定。
(2)使用该 flavor 创建一个虚机
nova boot --image new1 --key_name test --flavor m1.small 123
(3)待虚机变为可用状态后,登录,使用 lspci 命令查看 GPU 设备
nova ssh --private 123 -i test.pem
2.3 Nova PCI 相关代码分析
2.3.1 Nova 资源申请过滤、资源申请和状态周期性汇报流程
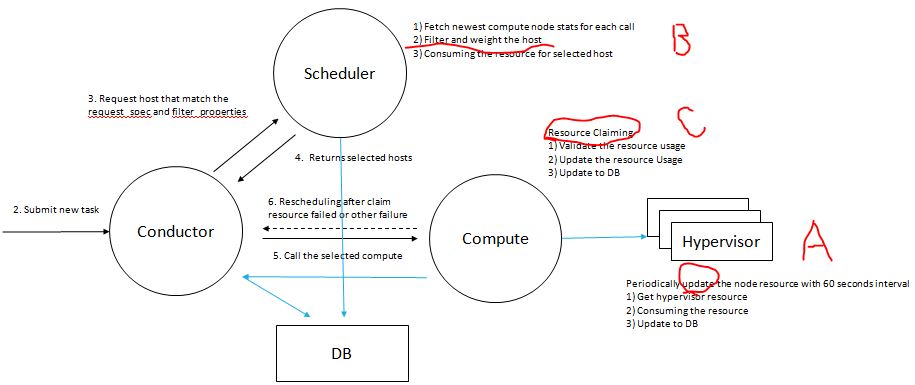
A: KVM 计算节点上的 PCI 设备状态的获取
nova-compute 的 resource_tracker 周期性地获取 KVM 计算节点的 PCI 状态并写进数据库:
2016-02-03 03:20:58.191 INFO nova.compute.resource_tracker [req-5da1fbd0-3f97-4a88-83be-51f938b60860 None None] Final resource view: name=hkg02kvm002ccz023 phys_ram=32204MB used_ram=25088MB phys_disk=314GB used_disk=240GB total_vcpus=24 used_vcpus=4 pci_stats=<nova.pci.stats.PciDeviceStats object at 0x7f4e60d32910>
类 nova.pci.stats.PciDeviceStats 的实现在 /nova/pci/stats.py 文件中。其数据格式为:
| [{"count": 5, "vendor_id": "8086", "product_id": "1520", "extra_info":'{}'}],
也就是每一种由配置项 pci_passthrough_whitelist 所指定的可分配给虚机的 PCI 设备的可用数目。
B: Nova scheduler 使用 DB 中的 PCI 设备状态数据来过滤出能满足请求所要求的PCI资源的计算节点
用户使用某个配置了 PCI 设备需求的 Nova flavor 来创建虚机
-> nova-api 读取所使用的 flavor 的 ”pci_passthrough:alias“ 属性的值,该值指定了所使用的 PCI 设备的属性和数量,其数据形式为 ”| [{"count": 1, "vendor_id": "8086", "product_id": "1520",}].“
-> nova-scheduler 的 PciPassthroughFilter 匹配每个 KVM host 保存在数据库中的 pci_stats 和该 request 所要求的 PCI 资源,来确定每个 host 能不能满足虚机所要求的 PCI 设备的需求。如果不能满足,则返回 false;能满足则返回 true,表明该 host 满足了该 filter 的要求。
def host_passes(self, host_state, spec_obj): """Return true if the host has the required PCI devices.""" pci_requests = spec_obj.pci_requests if not pci_requests: return True if not host_state.pci_stats.support_requests(pci_requests.requests): LOG.debug("%(host_state)s doesn't have the required PCI devices" " (%(requests)s)", {'host_state': host_state, 'requests': pci_requests}) return False return True
C: PCI 设备管理和分配
Nova 使用类 ResourceTracker 来统一管理计算节点上的所有资源,包括资源发现(discover)、声明(claim)、分配(allocate)和释放(free)等操作。PCI 设备也是受管理资源的一种。类似其它资源,PCI 资源的信息也是永久保存在数据库中,这也方便使用者来查询这些信息。PCI 设备包括如下几种状态:available/claimed/allocated/deleted/removed。
PCI 资源分配的基本步骤:
(a)创建虚机:调用 def _build_instance(self, context, request_spec, filter_properties, requested_networks, injected_files, admin_password, is_first_time,node, instance, image_meta, legacy_bdm_in_spec) 方法
(b)claim PCI 资源:调用 resourceTracker.instance_claim(context, instance, limits) 方法来 claim 资源,包括内存、磁盘、numa 和 PCI 设备等。如果 claim 失败,则支持跑出错误。
(c)分配 PCI 资源:调用 self._update_usage_from_instance(context, self.compute_node, instance_ref) 来将资源标记为占用。该函数中,会调用 self.pci_tracker.update_pci_for_instance(context, instance) 来将 PCI 设备的状态保存到 pci_tracker。
2.3.2 虚机创建
(1)将 pci resource manager 分配好的 PCI 设备后加入到 guest中:
if virt_type in ('xen', 'qemu', 'kvm'): for pci_dev in pci_manager.get_instance_pci_devs(instance): guest.add_device(self._get_guest_pci_device(pci_dev))
def _get_guest_pci_device(self, pci_device): dbsf = pci_utils.parse_address(pci_device['address']) dev = vconfig.LibvirtConfigGuestHostdevPCI() dev.domain, dev.bus, dev.slot, dev.function = dbsf # only kvm support managed mode if CONF.libvirt.virt_type in ('xen', 'parallels',): dev.managed = 'no' if CONF.libvirt.virt_type in ('kvm', 'qemu'): dev.managed = 'yes' return dev
然后再调用 xml = conf.to_xml() 方法得到 guest 的 libvirt xml。一个分配的 PCI 设备的 Libvirt XML 定义示例如下:
<hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x86' slot='0x00' function='0x0'/> </source> <alias name='hostdev0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/> </hostdev>
(2)虚机完成启动后,登录它,再使用 lspci 就可以看到该透传的 GPU 了
这是 Cirros 客户机中的输出:
$ lspci -k ... 00:05.0 Class 0100: 1af4:1001 virtio-pci 00:06.0 Class 0300: 10de:11bf 00:07.0 Class 00ff: 1af4:1002 virtio-pci
这是 Ubuntu 客户机中的输出:
ubuntu@ubuntu-gpu:~$ lspci -nn
...
00:06.0 VGA compatible controller [0300]: NVIDIA Corporation GK104GL [GRID K2] [10de:11bf] (rev a1)
(3)在主机上查看两个 GPU 的状态,可以看出已分配和未分配的状态是不同的
stack@hkg02kvm002ccz023:~/logs$ readlink /sys/bus/pci/devices/0000:85:00.0/driver #这是已经分配给虚机的 ../../../../../../bus/pci/drivers/pci-stub stack@hkg02kvm002ccz023:~/logs$ readlink /sys/bus/pci/devices/0000:86:00.0/driver #这是未分配给虚机的 ../../../../../../bus/pci/drivers/vfio-pci
参考链接: