1、软件版本
jdk-7u80-linux-x64.tar.gz
hadoop-2.7.2.tar.gz
hbase-1.2.1-bin.tar.gz
2、集群配置
主机:Slave1.Hadoop IP地址:192.168.1.101
主机:Slave2.Hadoop IP地址:192.168.1.102
用户设置:系统用了GUI,新版非得建立一个账户。例如随便建一个jfz,密码1,但操作时使用root(密码root)直接进行,装好后重启,以后用SSH进root。
3、配置本地hosts
输入指令:
nano /etc/hosts192.168.1.100 Master.Hadoop
192.168.1.101 Slave1.Hadoop
192.168.1.102 Slave2.Hadoopping Master.Hadoop
ping Slave1.Hadoop
ping Slave2.Hadoop4、关闭防火墙
三台机器均关闭防火墙。
停止firewall:
systemctl stop firewalld.servicesystemctl disable firewalld.service5、Java安装
(1)卸载自带的OpenJDK v1.7:
java -version
yum remove java-1.7.0-openjdk(2) JDK安装:
在/usr下创建java文件夹,将jdk-7u80-linux-x64.tar.gz文件放到这个文件夹中。
使用以下指令进行解压
tar zxvf jdk-7u80-linux-x64.tar.gzrm jdk-7u80-linux-x64.tar.gznano /etc/profileexport JAVA_HOME=/usr/java/jdk1.7.0_80
export JRE_HOME=/usr/java/jdk1.7.0_80/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/binsource /etc/profilejava -version如果出现对应版本信息,则配置成功:java version "1.7.0_80"
6、SSH免密码登录
因为Hadoop需要通过SSH登录到各个节点进行操作,本集群用的是root用户,每台服务器都生成公钥,再合并到authorized_keys。
(1)修改sshd_config配置
CentOS默认没有启动SSH无密登录,去掉/etc/ssh/sshd_config其中2行的注释,每台服务器都要设置。
nano /etc/ssh/sshd_config
RSAAuthentication yes
PubkeyAuthentication yes(2)生成key
输入命令:
ssh-keygen -t rsa(3)合并key
合并公钥到authorized_keys文件,在Master服务器,进入/root/.ssh目录,通过SSH命令合并。
cat id_rsa.pub>> authorized_keys
ssh root@192.168.1.101 cat ~/.ssh/id_rsa.pub>> authorized_keys
ssh root@192.168.1.102 cat ~/.ssh/id_rsa.pub>> authorized_keys(4)拷贝key
把Master服务器的authorized_keys、known_hosts复制到Slave服务器的/root/.ssh目录。
scp authorized_keys known_hosts root@192.168.1.101:/root/.ssh
scp authorized_keys known_hosts root@192.168.1.102:/root/.ssh(5)检证免密登陆
ssh root@192.168.1.101
ssh root@192.168.1.102以后就不需要输入密码了。
7、Hadoop安装流程
(1)下载hadoop安装包
将下载“hadoop-2.7.2.tar.gz”文件上传至到/home/hadoop目录下。 注意:一定要在Linux下解压,否则执行权限问题很麻烦。
(2)解压压缩包
tar -xzvf hadoop-2.7.2.tar.gz(3)在/home/hadoop目录下创建目录
创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
mkdir -p tmp hdfs/name hdfs/data(4)配置core-site.xml
指令:
nano /home/hadoop/hadoop-2.7.2/etc/hadoop/core-site.xml<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.100:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>(5)配置hdfs-site.xml
指令:
nano /home/hadoop/hadoop-2.7.2/etc/hadoop/hdfs-site.xml<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.100:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>(6)配置mapred-site.xml
指令:
nano /home/hadoop/hadoop-2.7.2/etc/hadoop/mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.100:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.100:19888</value>
</property>
</configuration>(7)配置yarn-site.xml
指令:
nano /home/hadoop/hadoop-2.7.2/etc/hadoop/yarn-site.xml<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.1.100:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.100:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.100:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.1.100:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.1.100:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
</configuration>(8)配置hadoop-env.sh、yarn-env.sh的JAVA_HOME
配置/home/hadoop/hadoop-2.7.2/etc/hadoop目录下:
hadoop-env.sh、yarn-env.sh的JAVA_HOME,不设置的话,启动不了。
export JAVA_HOME=/usr/java/jdk1.7.0_80(9)配置slaves
nano /home/hadoop/hadoop-2.7.2/etc/hadoop/slaves192.168.1.101
192.168.1.102(10)传送Hadoop至其它节点
将配置好的Hadoop复制到各个节点对应位置上,通过scp传送:
scp -r /home/hadoop 192.168.1.101:/home/
scp -r /home/hadoop 192.168.1.102:/home/(11)启动Hadoop
在Master服务器启动hadoop,从节点会自动启动。
进入/home/hadoop/hadoop-2.7.2目录,初始化,输入命令:
bin/hdfs namenode -formatsbin/start-all.shHadoop环境变量配置,需要在/etc/profile 中添加HADOOP_HOME内容,之前已经配置过,所以这一步已经节省下来,那么可重启 source /etc/profile。
(12)验证Hadoop
jps运行成功结果:

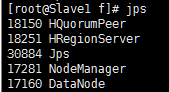
8、Hbase安装流程
(1)复制安装包至Master节点/home/hbase目录下
通过SFTP或是直接拷贝至Master节点,软件推荐在Linux下解压!
(2)解压压缩包
tar zxvf hbase-1.2.1-bin.tar.gz(3)添加到环境变量
将hbase添加到环境变量/etc/profile中,配环境变量方便使用指令:
nano /etc/profileexport HBASE_HOME=/home/hbase/hbase-1.2.1
export PATH=$HBASE_HOME/bin:$PATH
export HBASE_MANAGES_ZK=true
export HBASE_CLASSPATH=/home/hbase/hbase-1.2.1/conf(4)修改配置文件hbase-env.sh
nano /home/hbase/hbase-1.2.1/conf/hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_80(5)修改配置文件hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://192.168.1.100:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>Master.Hadoop,Slave1.Hadoop,Slave2.Hadoop</value>
</property>
<property>
<name>hbase.temp.dir</name>
<value>/home/hbase/hbase-1.2.1/tmp</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hbase/hbase-1.2.1/tmp/zookeeper</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
</configuration>(6)修改配置文件regionservers:
nano regionserversMaster.Hadoop
Slave1.Hadoop
Slave2.Hadoop(7)Hbase复制到从节点
差不多要成功了,别忘了最后一步!
scp -r /home/hbase/hbase-1.2.1 root@192.168.1.101:/home/hbase/
scp -r /home/hbase/hbase-1.2.1 root@192.168.1.102:/home/hbase/(8)验证Hbase
1、用jps命令看进程对不对。
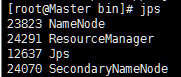
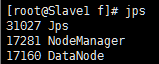
2、测试Web访问
http://Master.Hadoop:8088/
http://Master.Hadoop:50070/
http://Master.Hadoop:60010/