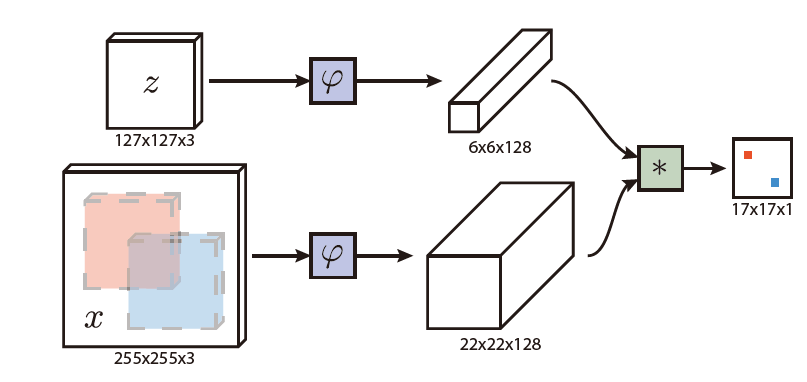
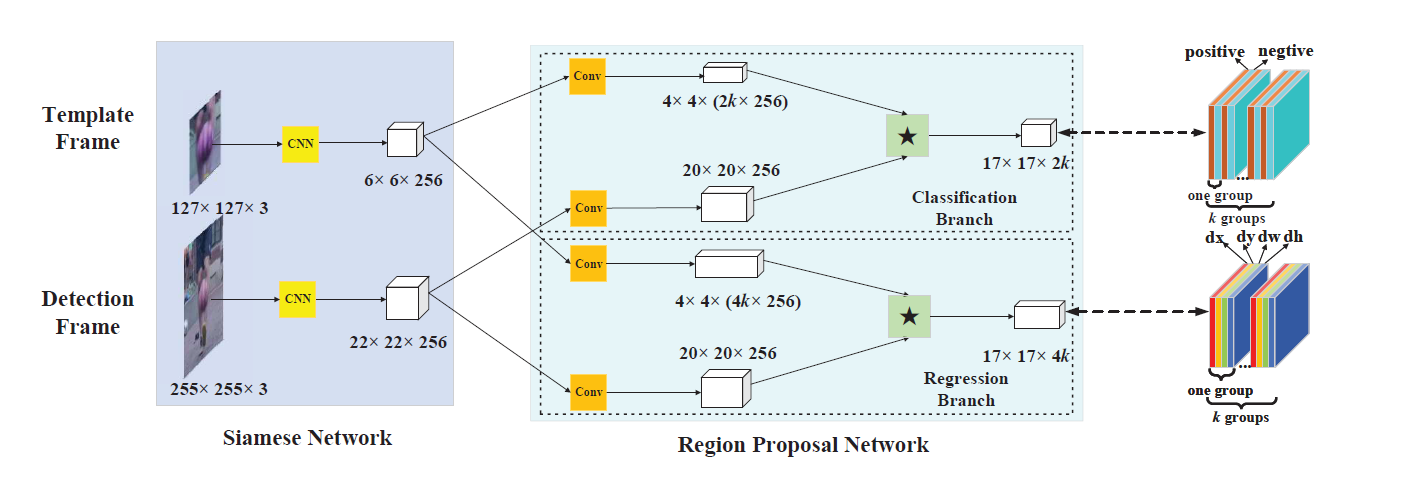
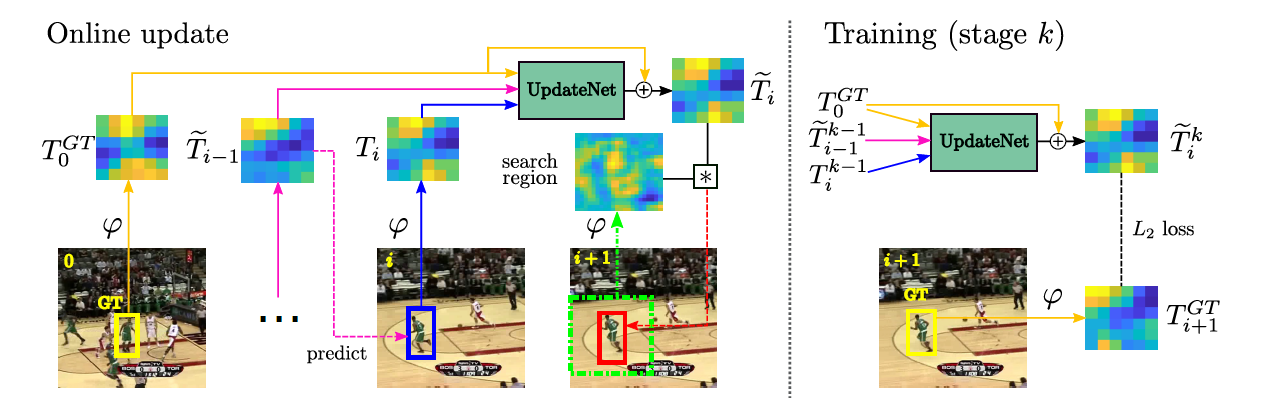
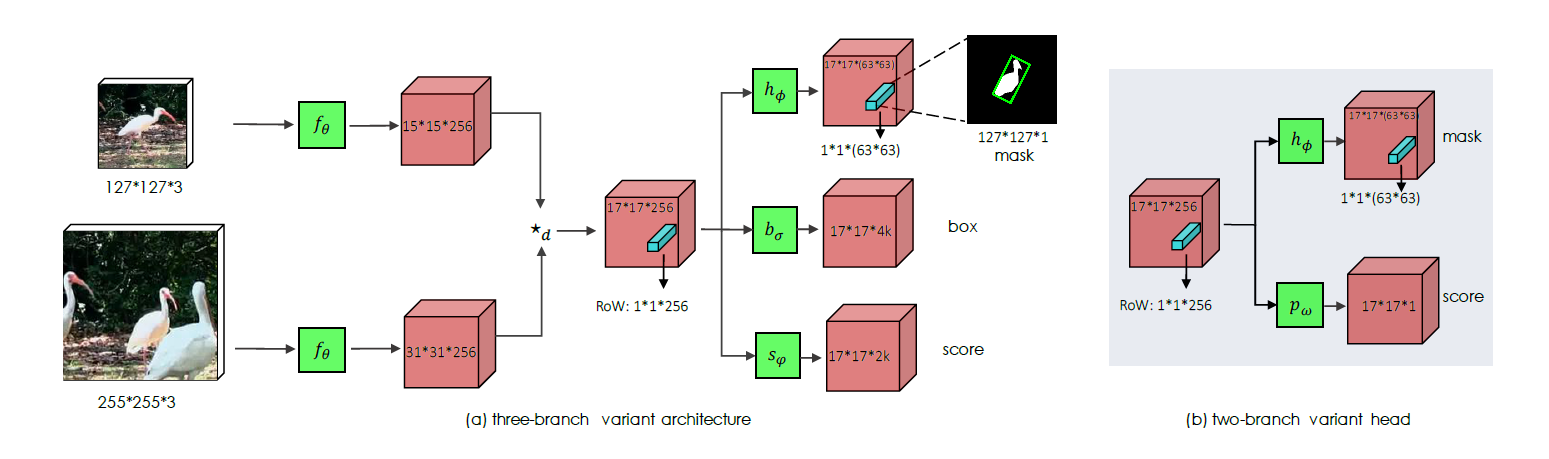
| (ImageNet)ILSVRC-VID |
The 2015 edition of ImageNet Large Scale Visual Recognition Challenge(ILSVRC). It contains 30 different classes of animals and vehicles. Training and validation sets together contain almost 4500 videos. |
百度网盘 请输入提取码 (baidu.com) fj43 ImageNet Large Scale Visual Recognition Competition (ILSVRC) (image-net.org) |
| ILSVRC-DET |
Object detection dataset |
链接:https://pan.baidu.com/s/1vsIVMOWvaIlgDIW40VJSoQ 提取码:Vw4Z |
| Youtube-BB |
The data set consists of 10.5 million human annotations on video frames. The data set contains 5.6 million tight bounding boxes around tracked objects in video frames. The data set consists of approximately 380,000 15-20s video segments extracted from 240,000 different publicly visible YouTube videos, automatically selected to feature objects in natural settings without editing or post-processing, with a recording quality often akin to that of a hand-held cell phone camera. All these video segments were human-annotated with high precision classifications and bounding boxes at 1 frame per second. The use of a cascade of increasingly precise human annotators ensures a measured label accuracy above 95% for every class and tight bounding boxes around the tracked objects. The objects tracked in the video segments belong to 23 different classes. |
https://research.google.com/youtube-bb/download.html |
| COCO |
118K/5K for train/val. It can used for object segmentation, recognition in context, superpixel stuff segmentation, 330K images(>200K labeled), 1.5 million object instances, 80 object categories, 91 stuff categories, 5 captions per image. 250000 people with keypoints. |
COCO - Common Objects in Context (cocodataset.org) |
| GOT-10k |
Generic Object Tracking Benchmark, A large, high-diversity, one-shot database for generic object tracking in the wild. The dataset contains more than 10,000 video segments of real-world moving objects and over 1.5 million manually labeled bounding boxes. The dataset is backboned by WordNet and it covers a majority of 560+ classes of real-world moving objects and 80+ classes of motion patterns. The dataset encourages the development of generic purposed trackers by following the one-shot rule that object classes between train and test sets are zero-overlapped. 它总共66G,比LaSOT小,比TrackingNet更小。但 目标类别很多,有额外的标注信息(bounding box / visible ratios等),丰富的运动轨迹信息。 train: 10000个视频序列,563个目标类别,87种运动模式(e.g. 跑,游泳,滑雪,爬行,骑车,跳水,骑马,冲浪) test: 180个视频序列,84个目标类别,32种运动模式 |
GOT-10k: Generic Object Tracking Benchmark (aitestunion.com) |
| YouTube-VOS |
A Large-Scale Benchmark for Video Object Segmentation. It can be used for Semi-supervised Video Object Segmentation and Video Instance Segmentation. It has 4000+ high-resolution YouTube videos, 90+ semantic categories, 7800+ unique objects, 190k+ high-quality manual annotations, 340+ minutes duration. |
YouTube-VOS Dataset - YouTube-VOS (youtube-vos.org) |
| DAVIS-2016 |
In each video sequence a single instance is annotated. 有两个度量分割准确率的主要标准:区域相似度(Region Similarity):区域相似度是掩膜 M 和真值 G 之间的 Intersection over Union 函数.轮廓精确度(Contour Accuracy):将掩膜Mask看成一系列闭合轮廓的集合,并计算基于轮廓的F度量,即准确率和召回率的函数. 即轮廓精确度是对基于轮廓的准确率和召回率的F度量. DAVIS是一个像素完美匹配标注的数据集. 它的目标是重建真实的视频场景,如摄像机抖动、背景混杂、遮挡以及其它复杂状况. DAVIS构成包括50个序列总共3455标注帧,视频帧率为24fps,1080p分辨率。 |
DAVIS: Densely Annotated VIdeo Segmentation (davischallenge.org) |
| DAVIS-2017 |
In each video sequence multiple instances are annotated. Semi-supervised and Unsupervised refer to the level of human interaction at test time, not during the training phase. In Semi-supervised, better called human guided, the segmentation mask for the objects of interest is provided in the first frame. In Unsupervised, better called human non-guided, no human input is provided. |
DAVIS: Densely Annotated VIdeo Segmentation (davischallenge.org) |
| OTB-50 |
其对应视频序列为其网站的前50个视频序列,其中Skating因标注对象不同,可以看作两个视频序列 |
Visual Tracker Benchmark (hanyang.ac.kr) |
| OTB-2013 |
其视频序列为对应作者在CVPR2013发表文章Wu Y, Lim J, Yang M H. Online object tracking: A benchmark [C]// CVPR, 2013.中的51个视频序列 |
|
| OTB-100 |
OTB100与OTB2015相同, 其对应视频序列为作者发表文章Wu Y, Lim J, Yang M H. Object tracking benchmark [J]. TPAMI, 2015.中的100个视频序列。其中Skating、Jogging因标注对象不同,分别看作两个视频序列。 |
|
| OTB-2015 |
同上 |
|
| VOT-13 |
The dataset comprises 16 short sequences showing various objects in challenging backgrounds.The sequences were chosen from a large pool of sequences using a methodology based on clustering visual features of object and background so that those 16 sequences sample evenly well the existing pool. The sequences were annotated by the VOT committee using axis-aligned bounding boxes. |
https://www.votchallenge.net/vot2013/index.html |
| VOT-14 |
The dataset comprises 25 short sequences showing various objects in challenging backgrounds. Eight sequences are from last year’s VOT2013 challenge (bolt, bicycle, david, diving, gymnastics, hand, sunshade, woman). The new sequences show complementary objects and backgrounds, for example a fish underwater or a surfer riding a big wave. The sequences were chosen from a large pool of sequences including the ALOV dataset using a methodology based on clustering visual features of object and background so that those 25 sequences sample evenly well the existing pool. |
https://www.votchallenge.net/vot2014/index.html |
| VOT-15 |
The dataset comprises 60 short sequences showing various objects in challenging backgrounds. The sequences were chosen from a large pool of sequences including the ALOV dataset, OTB2 dataset, non-tracking datasets, Computer Vision Online, Professor Bob Fisher’s Image Database, Videezy, Center for Research in Computer Vision, University of Central Florida, USA, NYU Center for Genomics and Systems Biology, Data Wrangling, Open Access Directory and Learning and Recognition in Vision Group, INRIA, France. The VOT sequence selection protocol was applied to obtain a representative set of challenging sequences. The dataset is automatically downloaded by the evaluation kit when needed, there is no need to separately download the sequences for the challenge. |
https://www.votchallenge.net/vot2015/index.html |
| VOT-16 |
The VOT2016 and VOT-TIR2016 datasets are available through the VOT toolkit. Download the latest version of the VOT toolkit and select either the VOT2016 or the VOT-TIR2016 challenge. The correct dataset will be automatically downloaded. The sequences of VOT2016 dataset are the same sequences of VOT2015 dataset. However, the GT of VOT2016 is more accurate than the GT of VOT2015 dataset which has an impact on the evaluation. The VOT-TIR2016 dataset was updated with new sequences. |
https://www.votchallenge.net/vot2016/index.html |
| VOT-17 |
The VOT-TIR2017 dataset is the same as the VOT-TIR2016 dataset and is also available through the dataset. |
https://www.votchallenge.net/vot2017/ |
| VOT-18 |
The VOT2018 and VOT-LT2018 datasets are available through the VOT toolkit. |
https://www.votchallenge.net/vot2018/ |
| VOT-19 |
同上 |
https://www.votchallenge.net/vot2019/ |
| VOT-2020 |
VOT2020对评价方式进行了一些修改,使得对目标跟踪的评价更加公正。VOT2020取消了重启,转而用intialization points来代替,每个序列中,在初始帧,结束帧以及每隔帧,都设置一个initialization point(anchor), 跟踪器从每个anchor处开始正向或反向运行。且旋转矩形框变成了mask |
https://www.votchallenge.net/vot2020/index.html |
| UAV123 |
103个视频序列,由专业的高级的无人机稳定可控的相机捕获,高度5~25meters;12个视频序列,由价格比较低的无人机不稳定的相机捕获,这些序列拥有低的质量和分辨率,还包含合理的噪声,并完全手工标注。第三,8个合成的视频序列,由我们提出的UAV模拟器。目标随着预先定义的轨迹移动,使用Unreal Game Engine rendered,同时自动标注在30fps,同时也可以获得目标mask/segmentation |
https://cemse.kaust.edu.sa/ivul/uav123 |
| UAV20L |
UAV123中相对于初始帧的bbox大小和纵横比变化非常显著。此外,因为相机被固定在无人机上,所以相机可以随着物体而移动,导致了一个较长的跟踪序列,这也标志着与静态跟踪系统的不同)。因为航空跟踪都是长序列,所以我们把它切割成子序列,以确保数据集保持合理的困难程度。 其中有一个子集用于长序航空跟踪,叫做(UAV20L) |
同上 |
| LaSOT |
We have compiled a large-scale dataset by gathering 1400 sequences with 3.52 million frames form YouTube under Creative Commonns licence. 它是一个long-term tracking ,这个数据集有1400个视频序列,每个视频平均有2512帧,最短的视频也有1000帧,最长的包含11397帧。分为70个类别,每个类别由二十个视频序列组成。更重要的是,它考虑了视觉外观和自然语言的联系,不仅标注了bbox而且增加了丰富的自然语言描述,旨在鼓励对于跟踪,结合视觉和自然语言特征的探索。这里提供1400个句子描述。 Large-scale: 1,550 sequences with more 3.87 millions frames High-quality: Manual annotation with careful inspection in each frame Category balance: 85 categories with each containing twenty (70 classes) or ten (15 classes) sequences Long-term tracking: An average video length of around 2,500 frames (i.e., 83 seconds) Comprehensive labeling: Providing both visual and lingual annotation for each sequence Flexible Evaluation Protocol: Evaluation under three different protocols: no constraint, full-overlap and one-shot |
LaSOT - Large-scale Single Object Tracking (stonybrook.edu) |
| TrackingNet |
这个数据集采用一种方法将现有的大规模的目标检测的数据集利用到目标跟踪上(YouTubeBB稀疏标注)。也就是说,是视频目标检测YT-BB的子集,大约1.1T,收集了30643个视频片段,平均时长为16.6s。We provide more than 30K videos with more than 14 milliondense bounding box annotations. In addition, we introduce a new benchmark composed of 500 novel videos, modeled with a distribution similar to our training dataset.(evaluating more than 20 trackers) (i)尽管目标跟踪取得了相当大的成功,但它仍然是一个挑战。当前的跟踪器在已经建立的数据集,如OTB、VOT基准上表现的很好,然而,这些数据集大部分是相对小的,并且不能完全代表在野外跟踪目标所遇到的挑战。 (ii)目前基于深度的跟踪器经常受限,一般使用目标分类的预训练模型或者使用目标检测的数据集训练,如ImageNet Videos,或者使用小型的数据集来训练,这些都是一些限制因素。 (iii)因为经典的跟踪器依赖手工特征并且因为存在的跟踪数据集小,当前用于训练和测试的数据之间并没有明确的区分。 基于这些,本文提出了TrackingNet数据集,它有以下优势: (1)大规模的训练集使得专门针对跟踪的深度设计的发展成为可能 (2)目标跟踪数据集的特殊性使得新的结构更关注连续帧之间的时间上下文信息。当前大规模的目标检测数据集没有及时提供密集标注的数据,也就是并不是每一帧都做标注 (3)TrackingNet通过在YouTube视频上采样来表示真实世界的场景 因此,TrackingNet视频包含了丰富的目标类别的分布,并且我们强制在训练和测试之间共享这些类别。最后我们在一个具有目标类别和运动的相似分布的隔离的测试集上进行评估跟踪器的性能。 贡献: TrackingNet是针对目标跟踪的第一个大规模的数据集。我们分析了其特征、属性、和独特性,当和其他数据集比起来时。另外我们还提供不同的技术从粗糙的标注生成密集的标注。 |
TrackingNet (tracking-net.org) |
| NfS |
这个数据集包含了100个数据集,每个视频序列都是手工标注,9个挑战属性。We propose the first higher frame rate video dataset (called Need for Speed - NfS) and benchmark for visual object tracking. The dataset consists of 100 videos (380K frames) captured with now commonly available higher frame rate (240 FPS) cameras from real world scenarios. All frames are annotated with axis aligned bounding boxes and all sequences are manually labelled with nine visual attributes - such as occlusion, fast motion, background clutter, etc. Our benchmark provides an extensive evaluation of many recent and state-of-the-art trackers on higher frame rate sequences. We ranked each of these trackers according to their tracking accuracy and real-time performance. One of our surprising conclusions is that at higher frame rates, simple trackers such as correlation filters outperform complex methods based on deep networks. This suggests that for practical applications (such as in robotics or embedded vision), one needs to carefully tradeoff bandwidth constraints associated with higher frame rate acquisition, computational costs of real-time analysis, and the required application accuracy. Our dataset and benchmark allows for the first time (to our knowledge) systematic exploration of such issues. |
The Need for Speed Dataset (ci2cv.net) |
| LTB35 |
长跟踪数据集:LTB35共35个序列,平均每个序列目标消失12次,平均每40帧目标消失一次。 |
https://amoudgl.github.io/tlp/ |
| OxUvA |
长跟踪数据集:We introduce a new video dataset and benchmark to assess single-object tracking algorithms. Benchmarks have enabled great strides in the field of object tracking by defining standardized evaluations on large sets of diverse videos. However, these works have focused exclusively on sequences only few tens of seconds long, and where the target object is always present. Consequently, most researchers have designed methods tailored to this "short-term" scenario, which is poorly representative of practitioners' needs. Aiming to address this disparity, we compile a long-term, large-scale tracking dataset of sequences with average length greater than two minutes and with frequent target object disappearance. This dataset is the largest ever for single object tracking: it comprises 366 sequences for a total of 14 hours of video, 26 times more than the popular OTB-100. We assess the performance of several algorithms, considering both the ability to locate the target and to determine whether it is present or absent. Our goal is to offer the community a large and diverse benchmark to enable the design and evaluation of tracking methods ready to be used "in the wild". |
Long-term Tracking (oxuva.github.io) |