
如何使用XPATH定位元素(史上最清晰的讲解)
目录
动态WEB元素
XPATH SELENIUM选择器
绝对路劲和相对路径
绝对路径
相对路径
使用XPATH为元素定位
1.标签,属性,值
2.CONTAINS
3. STARTS-WITH
4. CHAINED XPATH DECLARATIONS
5. XPATH WITH “OR” STATEMENT
6. XPATH WITH “AND” STATEMENT
7. XPATH TEXT
8. ANCESTOR
9. FOLLOWING
10. CHILD
11. PRECEDING
12. FOLLOWING-SIBLING
13. DESCENDANT
14. PARENT
15. LOCATE AN ELEMENT INSIDE ARRAY OF ELEMENT
动态WEB元素
我们编写自动化测试脚本的时候我们通常更加喜欢用id, name, class, etc来定位元素,但是有时候我们发现我们在html文本中找不到这些定位,这种情况我们将就只能使用更加灵活的定位方法,这种定位方法是针对相对复杂且位置多变的web元素。
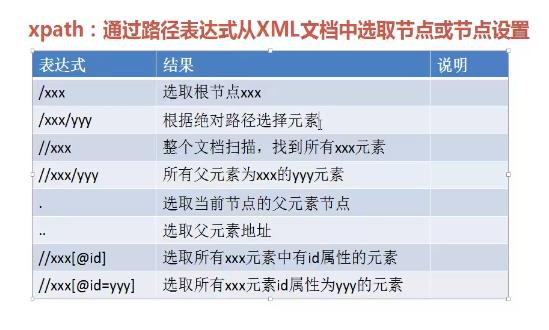
XPATH SELENIUM选择器
通过使用xml表达路径,我们可以找到网页上的任何一个元素,一些基本的Xpath 选择器如下:
语法: //标签名@[@s属性=‘value’]
举例: //input[@id=‘user-message’]
你也可以使用class name link_text,以及其他属性来定位
绝对路径和相对路径
其实从测试工程师的角度来看绝对路径和相对路径的差别特别简单
绝对路径
- 绝度路径是一种直接定义到元素的方法
- 以斜线“/”开始,“ /”代表着从根目录寻找
举例:/html/body/div[2]/div/div[2]/div[1]/div[2]/form/div/input

相对路径
1.一般从HTML的中间部门随即开始
2.以双斜线开始“//”,“//”代表可以从html 中的任何一处开始寻找元素
3.比绝对路径要短
举例://div[@class=‘form-group’]//input[@id=‘user-message’]
//input[@type='send text'] //label[@id='clkBtn'] //input[@value='SEND'] //*[@class='swtestacademy'] --> "*" means, search "swtestacademy" class for all tags. //a[@href='http://www.swtestacademy.com/'] //img[@src='cdn.medianova.com/images/img_59c4334feaa6d.png']
CONTAINS
这是一个非常便利的xpath选择器,甚至有的时候它能就自动化测试工程师的一条命,当一个元素的属性是动态的,你就有必要在一些场景中使用 contains()
举例://input[contains(@id,‘er-messa’)]
//*[contains(@name,'btnClk')] -->查找name属性的值包含”btnClk“的元素 //*[contains(text(),'here')] -->查找文本里包含‘here’的元素 //*[contains(@href,'swtestacademy.com')] -->查找链接里包含‘swtestacademy’的元素
STARTS-WITH
这个方法是针对一个属性是以什么开头的,不管元素的属性是不是动态变化的你都可以去使用这个方法
举例://input[starts-with(@id,‘user’)]

CHAINED DECLARATION
我们可以使用多个相对路径去定位一个元素用”//“分开
举例://div[@class=‘formgroup’]//input[@id=‘user-message’]
“OR”
利用这种方法的时候,我们使用两个条件语句例如A 和 B 并且通常返回一个集合
举例://[@id=‘user-message’ or @class=‘form-control’]

AND
利用这种方法的时候,我们使用两个条件语句例如A 和 B 并且通常返回一个集合
举例://[@id=‘user-message’ and @class=‘form-control’]
TEXT
我们可以通过一个元素的文本内容来找到它
举例://label[text()=‘Enter message’]
ANCESTOR
首先查找到在ancestor声明之前的那个元素,然后将这个元素设为顶端节点,最后查找这个节点内所有符合规则的元素
- 第一步,找到class是‘container-fluid’的元素
- 第二步,查找在这个元素里面的所有div
举例://[@class=‘container-fluid’]//ancestor::div

你可以选择通过div层级个数选择特定的div组
/*[@class=’container-fluid’]//ancestor::div[1] .//*[@class=’container-fluid’]//ancestor::div[2] .//*[@class=’container-fluid’]//ancestor::div[3] .//*[@class=’container-fluid’]//ancestor::div[4] .//*[@class=’container-fluid’]//ancestor::div[5]
FOLLOWING
用于定位已给的父类节点之后的元素。首先找到following声明之前的元素(following前面以双斜线隔开的元素),并将这个元素设置为顶端节点然后找到在这个节点之后的所有元素(与ancestor分开,ancestor是顶端节点里,following是顶端节点后)
- 第一步,标签名是form, id是‘gettotal’
- 第二步,开始查找这个元素后面的所有标签名为input的所有元素
举例://form[@id=‘gettotal’]//following::input

CHILD
查找当前节点的所有子节点
举例://nav[@class=‘fusion-main-menu’]//ul[@id=‘menu-main’]/child::li
同时,你还可以通过给定下标选择特定的li元素 li[1],li[2]

PRECEDING
查找当前节点之前的所有节点,假如我们要查找所有标签名为li的元素,首先我们选定最底部的元素,然后用preceding::li
举例://img[contains(@src,‘cs.mailmuch.co’)]//preceding::li

当然,你可以使用[1],[2]来选择这些集合里的特定元素
FOLLOWING-SIBLING
查找当前节点的之后的
举例://[@class=’col-md-6 text-left’]/child::div[2]//[@class=’panel-body’]//following-sibling::li
DESCENDANT
查找并返回当前元素的所有后代元素
举例://nav[@class=‘fusion-main-menu’]//[@id=‘menu-main’]//descendant::li
PARENT
返回当前节点的所有父类节点
举例://*[@id=’get-input’]/button//parent::form
在一个元素集合里定位一个元素
比如在Trivago 网站,我们查找关键词”Antalya“,然后用xpath找到第一个Odamax酒店
第一步:通过使用text方法我们可以找到所有Odamax酒店
//span[contains(text(),‘odamax’)]
(//span[contains(text(),‘odamax’)])[1]
你也可以继续查找相关酒店的价格元素
(//span[contains(text(),’odamax’)])[1]/following-sibling::strong[@class=’deals__price’]