map
- 类似其它语言中的哈希表或字典,以key-value形式存储数据
- key必须是支持==或!=比较运算的类型,不可以是函数、map或slice
- Map通过key查找value比线性搜索快很多
- Map使用make()创建,支持:=这种简写方式
- make([keyType]valueType,cap),cap表示容量,可省略
- 超出容量时会自动扩容,但尽量提供一个合理的初始值
- 使用len()获取元素个数
- 键值对不存在时自动添加,使用delete()删除某键值对
- 使用for range对map和slice进行迭代
字典(map)它能存储的不是单一值的集合,而是键值对的集合。
什么是键值对?它是从英文 key-value pair 直译过来的一个词。顾名思义,一个键值对就代表了一对键和值。注意,一个“键”和一个“值”分别代表了一个从属于某一类型的独立值,把它们两个捆绑在一起就是一个键值对了。
在 Go 语言规范中,应该是为了避免歧义,他们将键值对换了一种称呼,叫做:“键 - 元素对”。我们也沿用这个看起来更加清晰的词来讲解。
Go 语言的字典类型其实是一个哈希表(hash table)的特定实现,在这个实现中,键和元素的最大不同在于,键的类型是受限的,而元素却可以是任意类型的。
哈希表中最重要的一个过程:映射
可以把键理解为元素的一个索引,我们可以在哈希表中通过键查找与它成对的那个元素。键和元素的这种对应关系,在数学里就被称为“映射”,这也是“map”这个词的本意,
哈希表的映射过程就存在于对键 - 元素对的增、删、改、查的操作之中。
package main
import (
"fmt"
)
func main() {
aMap := map[string]int{
"one": 1,
"two": 2,
"three": 3,
}
k := "two"
v, ok := aMap[k]
if ok {
fmt.Printf("The element of key %q: %d
", k, v)
} else {
fmt.Println("Not found!")
}
}
比如,我们要在哈希表中查找与某个键值对应的那个元素值,那么我们需要先把键值作为参数传给这个哈希表。哈希表会先用哈希函数(hash function)把键值转换为哈希值。
哈希值通常是一个无符号的整数。一个哈希表会持有一定数量的桶(bucket),我们也可以叫它哈希桶,这些哈希桶会均匀地储存其所属哈希表收纳的键 - 元素对。
因此,哈希表会先用这个键哈希值的低几位去定位到一个哈希桶,然后再去这个哈希桶中,查找这个键。由于键 - 元素对总是被捆绑在一起存储的,所以一旦找到了键,就一定能找到对应的元素值。随后,哈希表就会把相应的元素值作为结果返回。
映射过程的第一步就是:把键值转换为哈希值。
在 Go 语言的字典中,每一个键值都是由它的哈希值代表的。也就是说,字典不会独立存储任何键的值,但会独立存储它们的哈希值。
Go 语言字典的键类型不可以是函数类型、字典类型和切片类型。
Go 语言规范规定,在键类型的值之间必须可以施加操作符==和!=。换句话说,键类型的值必须要支持判等操作。由于函数类型、字典类型和切片类型的值并不支持判等操作,所以字典的键类型不能是这些类型。
var badMap2 = map[interface{}]int{
"1": 1,
[]int{2}: 2, // 这里会引发panic。
3: 3,
}
另外,如果键的类型是接口类型的,那么键值的实际类型也不能是上述三种类型,否则在程序运行过程中会引发 panic(即运行时恐慌)。
声明 & 默认值
// 声明 var m map[string]string
map的声明的时候默认值是nil ,此时进行取值,返回的是对应类型的零值(不存在也是返回零值)。
// bool 的零值是false var m map[int]bool a, ok := m[1] fmt.Println(a, ok) // false false // int 的零值是0 var m map[int]int a, ok := m[1] fmt.Println(a, ok) // 0 false
初始化
map数据类型初始化:两种方式:map[string]string{}或make(map[string]string)
// 声明之后必须初始化,才能使用
m = make(map[string]int)
m = map[string]int{}
// 声明并初始化 <= 注意这里是 := 不是 =
m := make(map[string]int)
m := map[string]int{1:1}
向未初始化的map赋值引起 panic: assign to entry in nil map.
package main
import (
"fmt"
)
func main() {
// 声明之后必须初始化,才能使用
// 声明并初始化 <= 注意这里是 := 不是 =
var m map[string]int
m["helo"] = 2
fmt.Println(m)
}
输出:
panic: assignment to entry in nil map
goroutine 1 [running]:
main.main()
D:/GOWORK/src/study/main.go:13 +0x2e
未初始化的map是nil:
未初始化的map是nil,它与一个空map基本等价,只是nil的map不允许往里面添加值。(A nil map is equivalent to an empty map except that no elements may be added)
因此,map是nil时,取值是不会报错的(取不到而已),但增加值会报错。
其实,还有一个区别,delete一个nil map会panic,但是delete 空map是一个空操作(并不会panic)(这个区别在最新的Go tips中已经没有了,即:delete一个nil map也不会panic)
通过fmt打印map时,空map和nil map结果是一样的,都为map[]。所以,这个时候别断定map是空还是nil,而应该通过map == nil来判断。
Request中的Form字段就是如此,在没有直接或间接调用ParseForm()时,Form其实是nil,但是,你如果println出来,却是map[],可能有些困惑。通过跟踪源码可以发现,Form根本没有初始化。而在FormValue()方法中会判断Form是否为nil,然后决定是否调用ParseForm()方法,当然,你也可以手动调用ParseForm()方法。
package main
import (
"fmt"
"reflect"
)
func main() {
var m1 map[string]int
m1 = make(map[string]int)
m2 := make(map[string]int)
fmt.Println(m1, m2)
m1["chen"] = 88888
m2["chen"] = 88888
fmt.Println(m1, m2)
fmt.Println(reflect.DeepEqual(m1, m2))
}
输出:
map[] map[]
map[chen:88888] map[chen:88888]
true
package main
import (
"fmt"
"reflect"
)
func main() {
var m1, m2 map[string]int
m1 = make(map[string]int)
fmt.Println(m1, m2)
m1["chen"] = 88888
m2["chen"] = 88888
fmt.Println(m1, m2)
fmt.Println(reflect.DeepEqual(m1, m2))
}
输出: ----m2 是nil,增加值会报错。无法向m2中添加数据
map[] map[]
panic: assignment to entry in nil map
goroutine 1 [running]:
main.main()
D:/GOWORK/src/study/main.go:14 +0xb1
package main
import (
"fmt"
)
func main() {
m := make(map[interface{}]interface{})
m[1] = 56
m["str"] = "dfsdf"
for k, v := range m {
fmt.Println(k, v)
}
}
输出:
1 56
str dfsdf
key与value的限制
key一定要是可比较的类型(可以理解为支持==的操作):

如果是非法的key类型,会报错:invalid map key type xxx
golang为uint32、uint64、string提供了fast access,使用这些类型作为key可以提高map访问速度。[runtime/hashmap_fast.go]
value可以是任意类型。
新增 & 删除 & 更新 & 查询
package main
import (
"fmt"
)
func main() {
m := make(map[string]string)
// 新增
m["name"] = "咖啡色的羊驼"
// 删除,key不存在则啥也不干
delete(m, "name")
// 更新
m["name"] = "咖啡色的羊驼2"
// 查询,key不存在返回value类型的零值
i := m["name"] // 三种查询方式,
i, ok := m["name"]
//_, ok := m["name"]
fmt.Println(i, ok)
}
输出:
咖啡色的羊驼2 true
如果是非法的key类型,会报错:invalid map key type xxx
几种类型的比较:
arr1 := []int{1,2,3,4}
arr2 := []int{1,2,3,4}
切片不可以arr1 == arr2,会报错invalid operation: arr1 == arr2 (slice can only be compared to nil)
切片只可以与nil比较,判断是否为nil,不可以直接用“==”比较,但可以借助于reflect.DeepEqual(arr1, arr2)比较,返回true或false,此外map也可以通过reflect.DeepEqual(m1, m2)比较
package main
import (
"fmt"
"reflect"
)
func main() {
arr1 := []int{1, 2, 3, 4}
arr2 := []int{1, 2, 3, 4}
//fmt.Println(arr1 == arr2) //invalid operation: arr1 == arr2 (slice can only be compared to nil)
fmt.Println(reflect.DeepEqual(arr1, arr2))
}
结构体比较
不同结构的结构体不可以比较,但同一类型的实例值是可以比较的。
两个 struct完全相等, 意味着里面的所有变量的值都完全相等
type Person struct {
Name, Country string
}
hits := make(map[Person]int)
判断key是否在map中
if _, ok := map[key]; ok {
//存在进行相应操作
}
遍历
需要强调的是map本身是无序的,在遍历的时候并不会按照你传入的顺序,进行传出。
正常遍历:
package main
import (
"fmt"
)
func main() {
m := make(map[string]string)
// 新增
m["name"] = "咖啡色的羊驼"
// 删除,key不存在则啥也不干
delete(m, "name")
// 更新
m["name"] = "咖啡色的羊驼2"
m["tool"] = "火车"
// 查询,key不存在返回value类型的零值
i := m["name"] // 三种查询方式,
i, ok := m["name"]
//_, ok := m["name"]
fmt.Println(i, ok)
for k, v := range m {
fmt.Println(k, v)
}
}
有序输出:
package main
import (
"fmt"
"sort"
)
func main() {
m := make(map[string]string)
// 新增
m["name"] = "咖啡色的羊驼"
// 删除,key不存在则啥也不干
delete(m, "name")
// 更新
m["name"] = "咖啡色的羊驼2"
m["tool"] = "火车"
m["method"] = "交通工具"
// 查询,key不存在返回value类型的零值
i := m["name"] // 三种查询方式,
i, ok := m["name"]
//_, ok := m["name"]
fmt.Println(i, ok)
for k, v := range m {
fmt.Println(k, v)
}
var keys []string
// 把key单独抽取出来,放在数组中
for k, _ := range m {
keys = append(keys, k)
}
// 进行数组的排序
sort.Strings(keys)
// 遍历数组就是有序的了
for _, k := range keys {
fmt.Println(k, m[k])
}
}
输出:
咖啡色的羊驼2 true
name 咖啡色的羊驼2
tool 火车
method 交通工具
method 交通工具
name 咖啡色的羊驼2
tool 火车
函数传参
Golang中是没有引用传递的,均为值传递。这意味着传递的是数据的拷贝。
那么map本身是引用类型,作为形参或返回参数的时候,传递的是值的拷贝,而值是地址,扩容时也不会改变这个地址。
package main
import (
"fmt"
)
// 改变map的函数
func changeM(m map[int64]int64) {
fmt.Printf("m 函数开始时地址是:%p
", m)
var max = 5
for i := 0; i < max; i++ {
m[int64(i)] = 2
}
fmt.Printf("m 在函数返回前地址是:%p
", m)
}
func main() {
var m map[int64]int64
m = make(map[int64]int64, 1)
fmt.Printf("m 原始的地址是:%p
", m)
changeM(m)
fmt.Printf("m 改变后地址是:%p
", m)
fmt.Println("m 长度是", len(m))
fmt.Println("m 参数是", m)
}
输出:
m 原始的地址是:0xc0000c0450
m 函数开始时地址是:0xc0000c0450
m 在函数返回前地址是:0xc0000c0450
m 改变后地址是:0xc0000c0450
m 长度是 5
m 参数是 map[0:2 1:2 2:2 3:2 4:2]
map的基础数据结构 & 图
type hmap struct {
count int //元素个数
flags uint8
B uint8 //扩容常量
noverflow uint16 //溢出 bucket 个数
hash0 uint32 //hash 种子
buckets unsafe.Pointer //bucket 数组指针
oldbuckets unsafe.Pointer //扩容时旧的buckets 数组指针
nevacuate uintptr //扩容搬迁进度
extra *mapextra //记录溢出相关
}
type bmap struct {
tophash [bucketCnt]uint8
// Followed by bucketCnt keys
//and then bucketan Cnt values
// Followed by overflow pointer.
}
说明:每个map的地层结构是hmap,是有若干个机构为bmap的bucket组成的数组,每个bucket可以存放若干个元素(通常是8个),那么每个key会根据hash算法归到同一个bucket中,当一个bucket中的元素超过8个的时候,hmap会使用extra中的overflow来扩展存储key。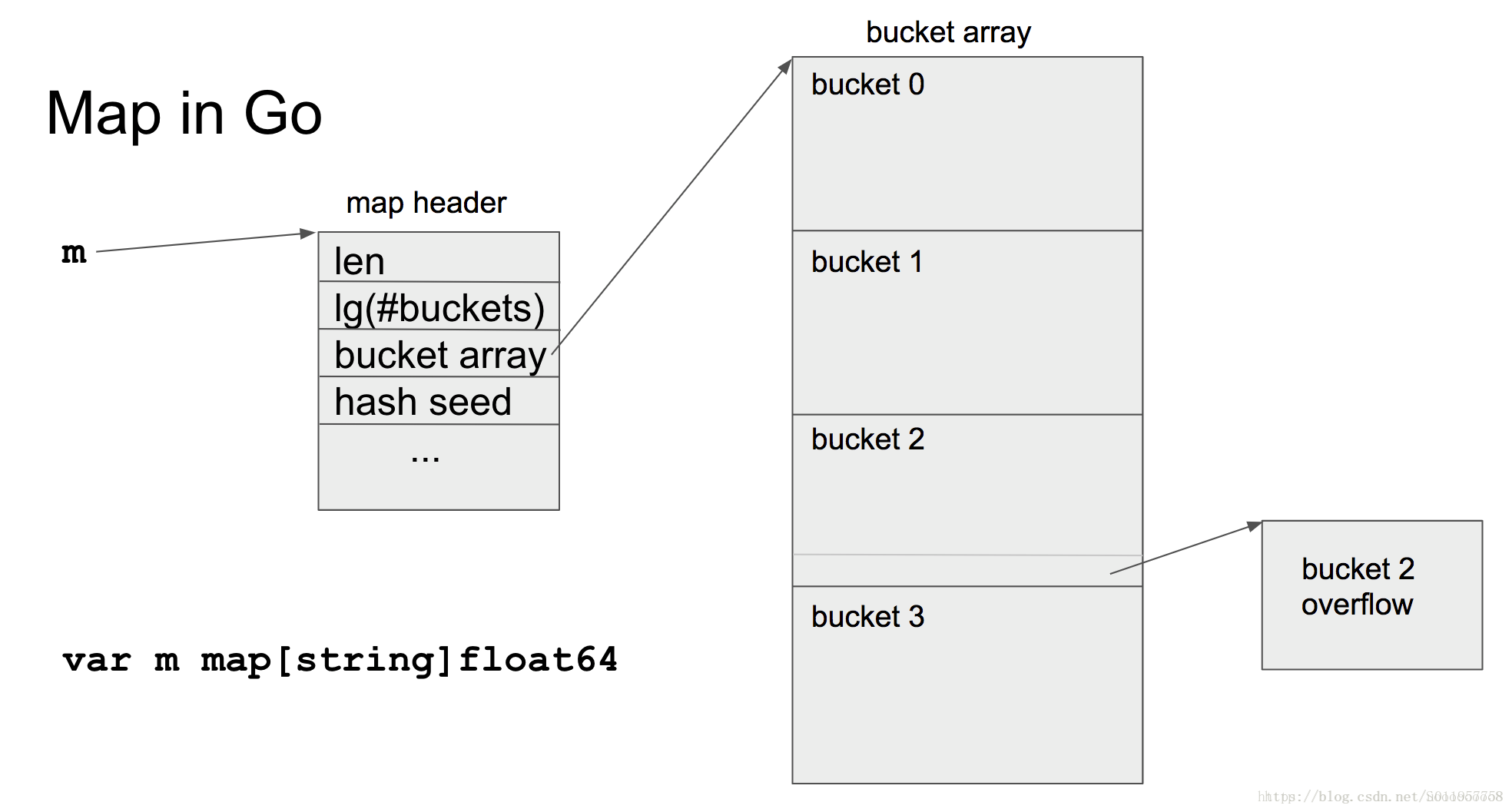
map的hash值计算
那么具体key是分配到哪个bucket呢?也就是bmap中的tophash是如何计算?
golang为每个类型定义了类型描述器_type,并实现了hashable类型的_type.alg.hash和_type.alg.equal
type typeAlg struct {
// function for hashing objects of this type
// (ptr to object, seed) -> hash
hash func(unsafe.Pointer, uintptr) uintptr
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
具体实现文件:go/1.10.3/libexec/src/runtime/hashmap.go:
// tophash calculates the tophash value for hash.
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (sys.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
return top
}
func main() {
test := map[int]int {1:1}
var s sync.RWMutex
go func() {
i := 0
for i < 10000 {
s.Lock()
test[1]=1
s.Unlock()
i++
}
}()
go func() {
i := 0
for i < 10000 {
s.Lock()
test[1]=1
s.Unlock()
i++
}
}()
time.Sleep(2*time.Second)
fmt.Println(test)
}
sync.Map的原理介绍:sync.Map里头有两个map一个是专门用于读的read map,另一个是才是提供读写的dirty map;优先读read map,若不存在则加锁穿透读dirty map,同时记录一个未从read map读到的计数,当计数到达一定值,就将read map用dirty map进行覆盖。
package main
import (
"fmt"
"sync"
"time"
)
func main() {
test := sync.Map{}
test.Store(1, 1)
go func() {
i := 0
for i < 10000 {
test.Store(1, 3)
i++
}
}()
go func() {
i := 0
for i < 10000 {
test.Store(1, 2)
i++
}
}()
time.Sleep(time.Second)
fmt.Println(test.Load(1))
}
map在golang里头是只增不减的一种数组结构,他只会在删除的时候进行打标记说明该内存空间已经empty了,不会回收的。所以要回收map还是需要设为nil