爬虫spider流程示意图
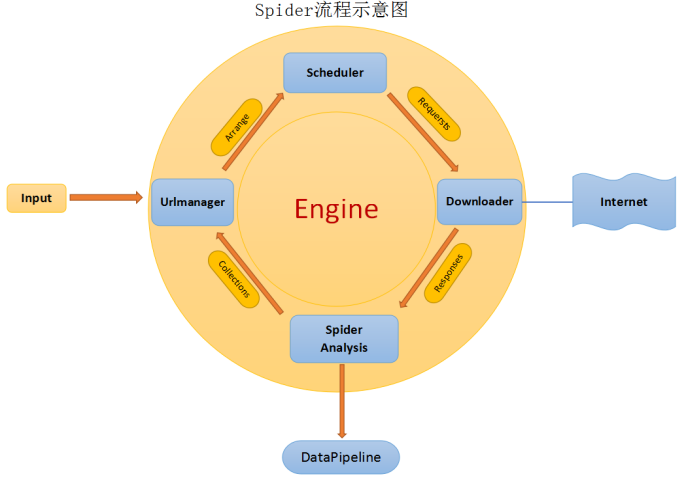
根据以上流程简单实现爬虫功能,只是一种简单的做事风格,实际更复杂,不做具体讨论。
1. 目录
2. engine.py
# encoding=utf-8
import os
from spider.scheduler import Scheduler
def read_urls(file_path):
with open(file_path, 'r+', encoding='utf-8') as fp:
lines = fp.readlines()
return [line.strip() for line in lines if line.strip()]
def engine():
path = os.path.dirname(__file__) + '/urls.txt'
urls = read_urls(path)
htmls = Scheduler.download(urls)
data = Scheduler.analysis(htmls)
Scheduler.storage(data)
if __name__ == '__main__':
engine()
3. scheduler.py
# encoding=utf-8
from spider.downloader import Download
from spider.analysis import Analysis
from spider.storage import Storage
class Scheduler:
def __init__(self):
pass
@staticmethod
def download(urls):
urls = urls if isinstance(urls, list) else [urls]
htmls = []
# 下载
for url in urls:
htmls.append((url, Download.get(url)))
return htmls
@staticmethod
def analysis(_tuple):
"""[(url, html), (url, html)]"""
# 解析
data = []
for url, html in _tuple:
data.append(Analysis.parse(url, html))
return data
@staticmethod
def storage(data):
# 存储
for params in data:
Storage.storage(params)
4. downloader.py
# encoding=utf-8
import requests
class Download:
"""
1. 高效爬取
2. 常见反反爬虫手段
3. 数据量的问题:并发, 分布式
"""
def __init__(self):
pass
@staticmethod
def get(url, headers={}):
html = requests.get(url, headers=headers)
return html.text
@staticmethod
def post(url, data={}, headers={}):
html = requests.post(url, data=data, headers=headers)
return html.text
@staticmethod
def get_headers(params):
"""..."""
return params
5. storage.py
# encoding=utf-8
import hashlib
import pymysql
class Storage:
table = 'spider'
def __init__(self):
pass
@staticmethod
def storage(params):
"""
insert or update params
:param params:
:return:
"""
sql_util = SqlUtil('127.0.0.1', 3306, 'root', '123456', 'mysql')
_id = Storage.url2md5(url=params['url'])
if sql_util.exists(Storage.table, _id):
sql_util.update(Storage.table, where={'id': _id}, dict_value=params)
else:
sql_util.insert(Storage.table, params)
@staticmethod
def url2md5(url):
if isinstance(url, str):
url = url.encode('utf-8')
m2 = hashlib.md5()
m2.update(url)
return m2.hexdigest()
6. urls.txt
https://www.cnblogs.com/sui776265233/p/9719463.html