attention的本质
通过计算Query和一组Key的相似度(或者叫相关性/注意力分布),来给一组Value赋上权重,一般地还会求出这一组Value的加权和。

一个典型的soft attention如下公式所示:

先用Query求出分别和一组Key计算相似度,计算相似度的方法有很多种,常用的有点乘、perceptron
然后用softmax归一化,得到每个Key对应的概率分布α(或者叫权重),即attention
由于Key和Value是一一对应的,再用α对Value做加权求和,得到加权和
Seq2Seq模型中attention的应用
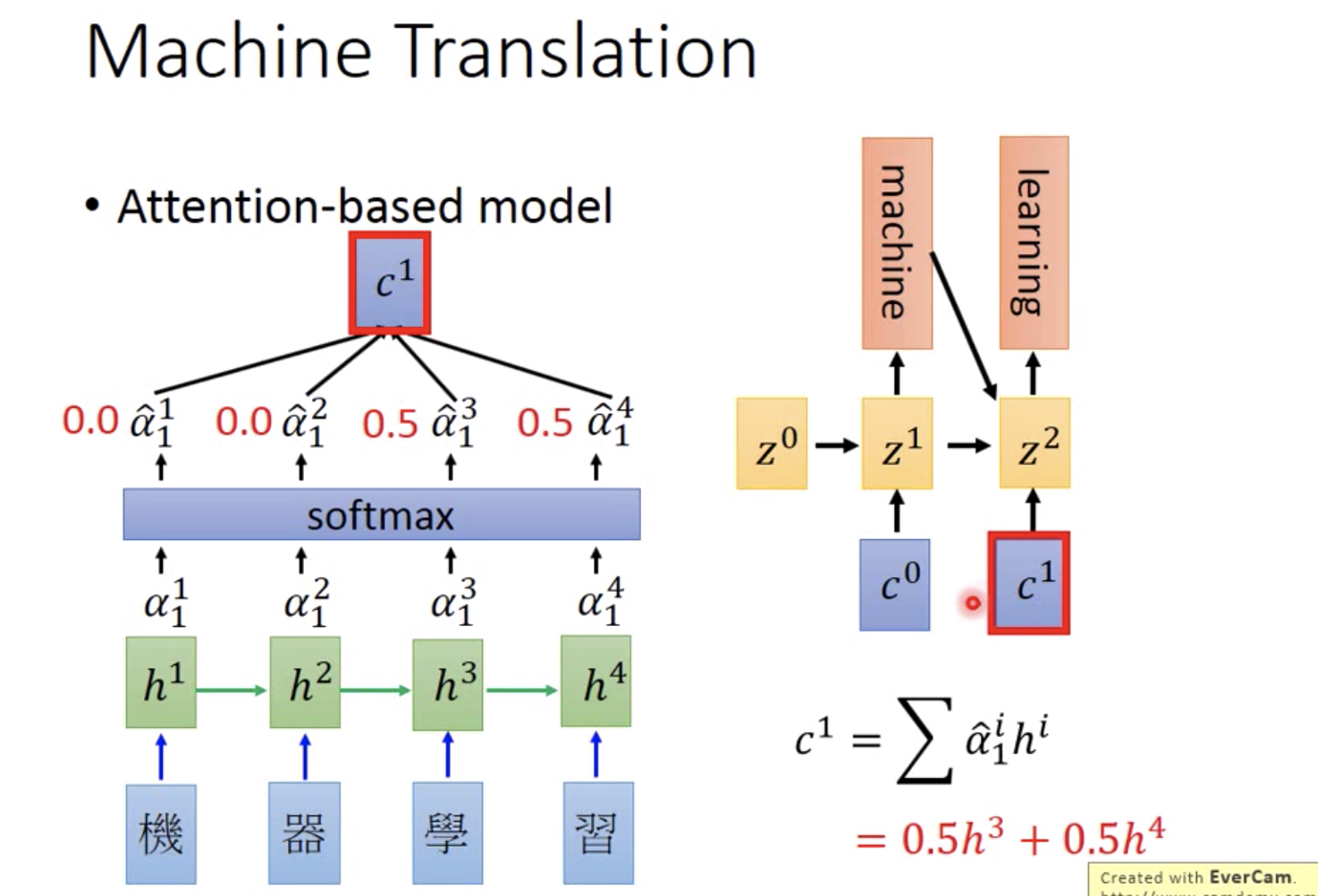
在Seq2Seq模型中,Key = Value = encoder hidden state(即h),而 Query = decoder hidden state(即z)
其实际的含义也很好理解:通过计算当前decode出来的hidden state和encode时的hidden state的关系,给原来所有的encode的hidden state加一个权重,然后求加权和,相当于计算当前输出词对每个输入词的相关性,用这个相关性做加权求和,得到最终的hidden state。
(上图刚好没有计算Q、K、V的过程,计算顺序是这样的:z0、h -> α0 -> c0 -> z1 ... ..., 其中 z0 作为第一个decoder hidden state是随机初始化的)
(上图machine指向z2的箭头实际上应该是z1指向z2的)
计算机视觉中attention的应用
Transformer中Self-attention的应用
先给出Transformer中attention的计算公式:

![]()
这里Q、K采用了Scaled Dot-Product Attention,分母就是一个归一化超参。整个形式和常规的attention是一样的。
所谓self-attention就是 Query = Key = Value。等等,Query是一个向量,Key和Value是一组向量,怎么能相等呢?
其实是这样的,Query也可以是一组向量,只不过这时候这组向量的每个向量分别去和Key、Value计算attention(这个操作可以并行!),所以最后加权和得到的不是一个向量,而是一组向量,和Query中的每个向量分别对应。下图可以方便理解这一过程:
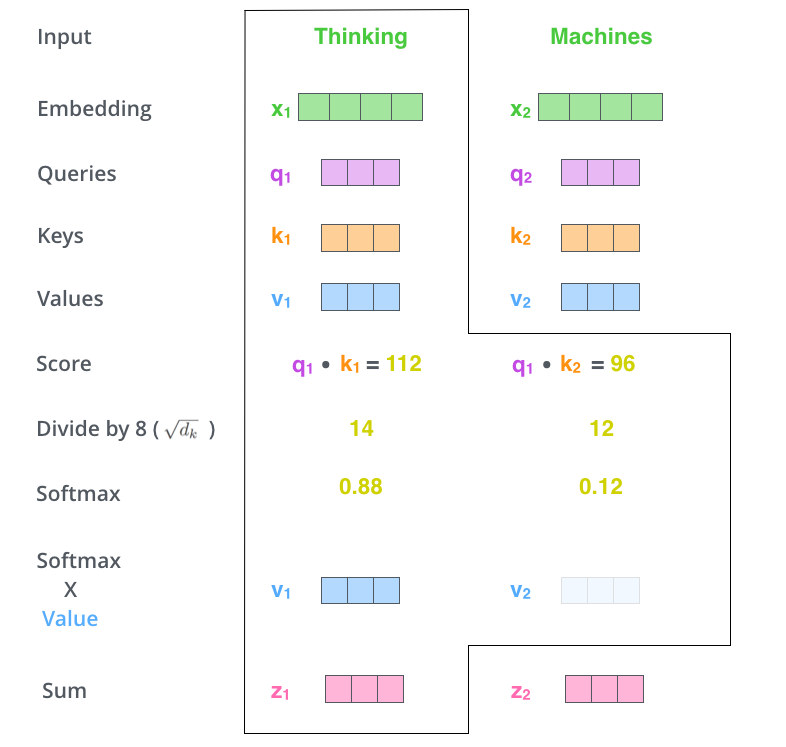
而在Transformer中,输入的Q、K、V就是word embedding序列,输出的是hidden state序列,与每一个word是一一对应的。
不难理解,整个self-attention的过程实际上是一个词序列中的每个词分别与这个序列中的每个词计算attention,所以形成了全连接的形式,每个词与每个词都通过attention直接联系在了一起,所以解决了long-term dependency的问题。而且可以并行计算,这也对提升RNN的性能有很大帮助。
Graph Attention Networks
从Transformer中我们发现,position embedding其实是非常重要的,因为attention机制和RNN、CNN不同,不包含任何position的信息,所以在做序列任务时需要专门处理position的信息。
但了解GNN的同学会发现,在做node aggregate的过程中,一个节点的邻节点是无序的;而attention机制刚好又非常适合做aggregate操作。因此,用attention做Graph Neural Network会是一个非常好的点,因此就有了Graph Attention Networks。
参考:
https://www.cnblogs.com/robert-dlut/p/8638283.html (自然语言处理中的自注意力机制)
https://blog.csdn.net/qq_41664845/article/details/84969266 (图解Transformer)
https://jalammar.github.io/illustrated-transformer/ (The Illustrated Transformer)
https://www.cnblogs.com/huangyc/p/10409626.html#_label3 (从Encoder-Decoder(Seq2Seq)理解Attention的本质)
https://zhuanlan.zhihu.com/p/53682800 (nlp中的Attention注意力机制+Transformer详解)
https://zhuanlan.zhihu.com/p/56501461 (计算机视觉中的注意力机制)