版权声明:本文为博主原创文章,转载 请注明出处:https://blog.csdn.net/sc2079/article/details/90480140
- 写在前面
本科毕业设计终于告一段落了。特写博客记录做毕业设计(路面裂纹识别)期间的踩过的坑和收获。希望对你有用。
目前有:
1.Tensorflow&CNN:裂纹分类
2.Tensorflow&CNN:验证集预测与模型评价
3.PyQt5多个GUI界面设计
本篇博客主要是评估所训练出来的CNN分类模型的性能。主要有几点:验证集预测、多分类混淆矩阵、多分类评价指标、预测结果堆叠图。
- 环境配置安装
运行环境:Python3.6、Spyder
依赖模块:Skimage、Tensorflow(CPU)、Numpy 、Matlpotlib等
- 开始工作
1.读取验证集图片
在验证集数据目录下有五个文件夹,分别以数字0-4命名,代表裂纹类型。其中,每个文件夹下各有100张图片。
def read_img(path):
cate=[path+x for x in os.listdir(path)]
imgs=[]
labels=[]
for idx,folder in enumerate(cate):
for im in glob.glob(folder+'/*.jpg'):
#print('reading the images:%s'%(im))
img=io.imread(im)
img=transform.resize(img,(100,100))
#img=normlization(img)
imgs.append(img)
labels.append(idx)
return np.asarray(imgs,np.float32),np.asarray(labels,np.int32)
path='d://test//img2//'
data,label=read_img(path)
#打乱顺序
num_example=data.shape[0]
arr=np.arange(num_example)
np.random.shuffle(arr)
data=data[arr]
label=label[arr]
x_val=data
y_val=list(label)
y_val即为每张图片的实际裂纹类型所对应的数字标签。
2.裂纹类型预测
def prediction(data):
with tf.Session() as sess:
model_path='d://test//model2'
saver = tf.train.import_meta_graph(model_path+'//model-13-2019_05_01.meta')
saver.restore(sess,tf.train.latest_checkpoint(model_path+'./')) # 加载最新模型到当前环境中
graph = tf.get_default_graph()
x = graph.get_tensor_by_name("x:0")
feed_dict = {x:data}
logits = graph.get_tensor_by_name("logits_eval:0")
classification_result = sess.run(logits,feed_dict)
#根据索引通过字典对应裂纹的分类
output = tf.argmax(classification_result,1).eval()
return output
tf.reset_default_graph() #清除过往tensorflow数据记录
sess=tf.Session()
sess.run(tf.global_variables_initializer())
y_predict=prediction(x_val)
输出为0-4的数字,分别代表预测结果为纵向裂纹、横向裂纹、块状裂纹、龟裂裂纹、无裂纹。
3.混淆矩阵绘制
一般二分类问题的混淆矩阵如下所示:
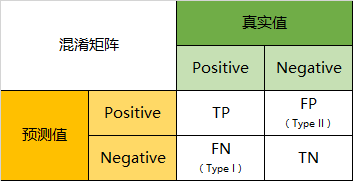
现绘制多分类的混淆矩阵,方法如下:
def plot_confusion_matrix(confusion_mat):
plt.imshow(confusion_mat,interpolation='nearest',cmap=plt.cm.Paired)
plt.title('Confusion Matrix')
plt.colorbar()
tick_marks=np.arange(5)
plt.xticks(tick_marks,tick_marks)
plt.yticks(tick_marks,tick_marks)
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.show()
confusion_matrix = tf.contrib.metrics.confusion_matrix(y_val,y_predict, num_classes=None, dtype=tf.int32, name=None, weights=None)
confusion_matrix = sess.run(confusion_matrix)
plot_confusion_matrix(confusion_matrix)
结果如下:

一般来说,混淆矩阵对角线颜色越深,说明预测结果越准确,所训练的模型的泛化性能越强。由结果可以看到,其对角线颜色较深,模型较好。
4.评价指标
二分类问题主要有以下指标:

而对于多分类问题,通常有”宏“和”微“之分。这里我使用的是宏指标,如下:
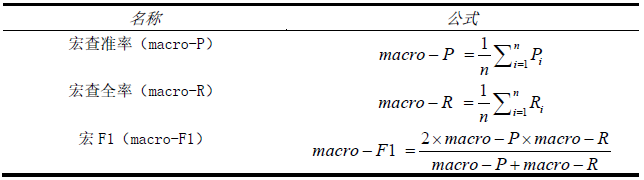
实现方法如下:
accu = [0,0,0,0,0]
column = [0,0,0,0,0]
line = [0,0,0,0,0]
recall =[0,0,0,0,0] #召回率
precision = [0,0,0,0,0] #精准率
accuracy = 0 #准确率
Macro_P = 0 #宏查准率(宏精准率)
Macro_R=0 #宏查全率(宏召回率)
#准确率
for i in range(0,5):
accu[i] = confusion_matrix[i][i]
accuracy+= float(accu[i])/len(y_val)
#宏召回率
for i in range(0,5):
for j in range(0,5):
column[i]+=confusion_matrix[j][i]
if column[i] != 0:
recall[i]=float(accu[i])/column[i]
Macro_R=np.array(recall).mean()
#宏精准率
for i in range(0,5):
for j in range(0,5):
line[i]+=confusion_matrix[i][j]
if line[i] != 0:
precision[i]=float(accu[i])/line[i]
Macro_P = np.array(precision).mean()
#宏F1
Macro_F1 = (2 * (Macro_P * Macro_R)) / (Macro_P+Macro_R)
结果如下:
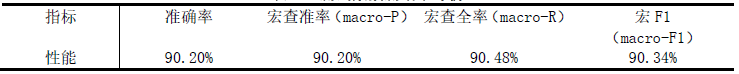
可以看出,各指标都在90%以上,模型较好。
5.绘制堆叠条形图
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
label_list = ['纵向裂纹', '横向裂纹', '块状裂纹', '龟裂裂纹','无裂纹']
num_list1 = accu
num_list2 = [100-i for i in accu]
x = range(len(num_list1))
rects1 = plt.bar(left=x, height=num_list1, width=0.45, alpha=0.8, color='green', label="预测正确")
rects2 = plt.bar(left=x, height=num_list2, width=0.45, color='red', label="预测错误", bottom=num_list1)
plt.ylim(0, 120)
#for a,b in enumerate(num_list1):
# plt.text(b+1, a - 13, '%s' % b)
plt.ylabel("数量")
plt.xticks(x, label_list)
plt.xlabel("裂纹类型")
plt.title("测试集预测结果堆叠条形图")
plt.legend()
plt.show()
结果如下:

-总结
基本能对分类模型性能做简单评价,还未绘制其ROC曲线。
-鸣谢
1.模型评估与选择