版权声明:本文为博主原创文章,转载 请注明出处:https://blog.csdn.net/sc2079/article/details/82263391
9月2日更:中国大学MOOC课程信息之数据分析可视化二
-
写在前面
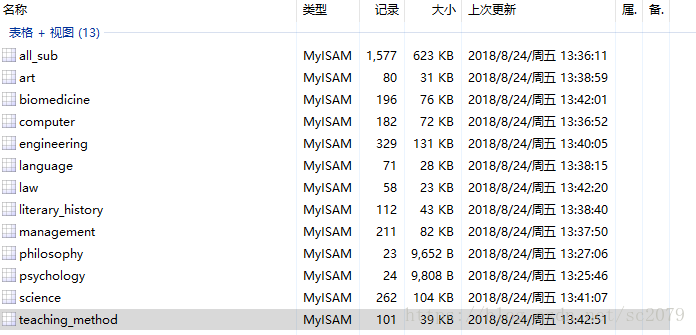
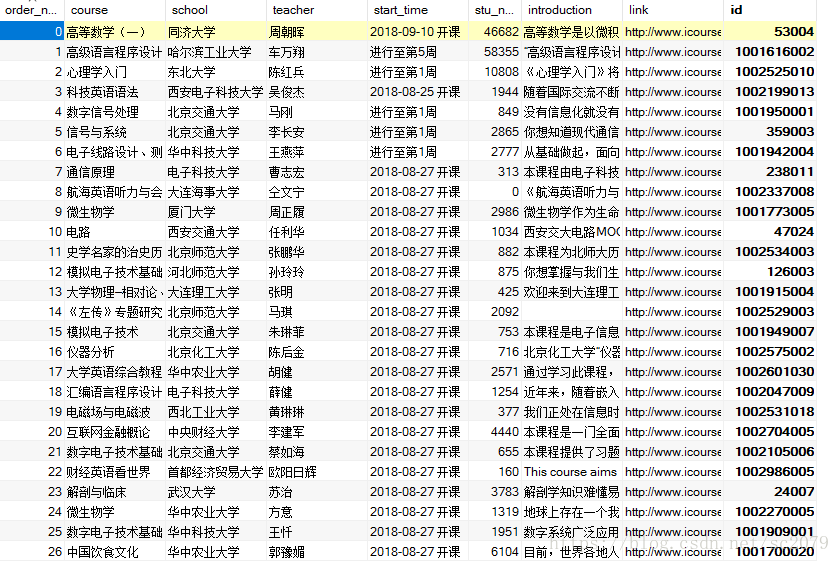
上一篇我的博客:中国大学MOOC课程信息爬取与数据存储于8月24日爬取并存储了中国大学MOOC的各个学科的课程信息。如下:
今天我就来简单做一哈MOOC课程信息的数据分析及可视化。
PS:初入茅庐,参考了网上很多大佬的文章,特别感谢!
-
环境配置与安装
运行环境:Python3.6 Spyder
依赖模块:scipy、matplotlib、pymysql、 jieba、re、collections、wordcloud 、pandas、seaborn、numpy、PIL、pyecharts等
注:部分模块的安装比较麻烦,可以网上查询相关方法。
-
开始工作
1、从Mysql 中获取数据
比较简单,我就直接贴代码了。
def get_mysql():
kc_info=[]
db = pymysql.connect(host='localhost',user='root',passwd='root',db='mooc_courses_info',charset='utf8')
cur = db.cursor()
sql = '''SHOW TABLES'''
cur.execute(sql)
tables= cur.fetchall()
for subject in tables:
cur.execute("select * from %s"% subject)
results=cur.fetchall()
kc_info.append(results)
return tables,kc_info
tables,kc_info=get_mysql()2、课程名做词云
我现将全部的课程名提取出来并连接在一起。
courses_text=''
for kc in kc_info[0]:
course_text=kc[1]
courses_text=courses_text+' '+course_text再用jieba分词,Counter计数,导出前100个高频词汇
courses_jieba = list(jieba.cut(courses_text))
# 使用 counter 做词频统计,选取出现频率前 100 的词汇
c = Counter(courses_jieba)
common_c = c.most_common(100)
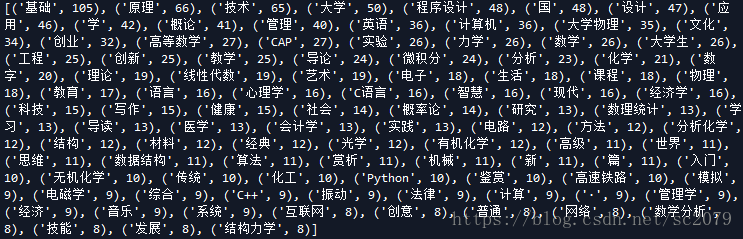
print(common_c)结果是这样的:

显然,“与”、“一”、“上”、标题符号等都不是我们所期待的,必须将其去掉。关于这一点,网上的方法是要利用停用词表去掉这些字词符号,参考这篇:python结巴分词、jieba加载停用词表。由于我所处理的精度以及量不算太多,我直接采用re去除。
courses_text= re.sub("[“”《》(),——:、-()一二三上下与的及之和中 ]", "",courses_text )处理后的结果是这样的:
看着还算可以吧。
接下来,就要做词云啦。参考我以前做过的词云,稍微修改一哈就可以啦。特别心酸的是:字体的正确选择,花了我好长时间。
def word_cloud(common_c):
# 读入词云模板
bg_pic = imread('D:\python_data\词云模板\29.jpg') #一张枫叶图片
# 配置词云参数
wc = WordCloud(
# 设置字体
font_path ='C:\windows\Fonts\STSONG.TTF',
# 设置背景色
background_color='white',
# 允许最大词汇
max_words=200,
# 词云形状
mask=bg_pic,
# 最大号字体
max_font_size=50,
random_state=100,
)
# 生成词云
wc.generate_from_frequencies(dict(common_c))
# 生成图片并显示
plt.figure()
plt.imshow(wc)
plt.axis('off')
plt.show()
# 保存图片
wc.to_file('D:\python_data\词云图片\2.jpg')
3.大学开课数统计
创建一个数组,记录开课数前20个的大学,并用柱形图表示出来。
def bar_plot(datas):
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
datas=pd.DataFrame(datas[0:20],columns=['大学','开课数'])
sns.barplot(x=datas['大学'],y=datas['开课数'],palette="muted")
plt.xticks(rotation=90)
plt.show()
#大学开课数统计
uni_courses_num={}
for kc in kc_info[0]:
uni_courses_num[kc[2]] = uni_courses_num.get(kc[2],0) + 1
items = list(uni_courses_num.items())
items.sort(key=lambda x:x[1], reverse=True)
bar_plot(items)得到的结果如下:
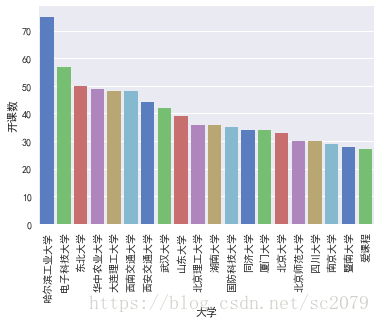
可以看出,哈工以巨大优势问鼎,电科、东北大学紧追其后。开心的是,母校也榜上有名!母校加油!
4.课程热度分析
这里我是在全部课程里统计课程热度的,如果有兴趣的话,你也可以选取你感兴趣的学科进行热度统计。
def bar_plot2(datas):
f, ax=plt.subplots(figsize=(8,12))
datas=pd.DataFrame(datas[0:20],columns=['课程名称','热度'])
#orient='h'表示是水平展示的,alpha表示颜色的深浅程度
sns.barplot(y=datas['课程名称'], x=datas['热度'],orient='h', alpha=0.8, color='red')
#sns.barplot(y=datas['课程名称'], x=datas['热度'],palette="muted")
#设置X轴的各列下标字体是水平的
plt.xticks(rotation='horizontal')
#设置Y轴下标的字体大小
plt.yticks(fontsize=10)
plt.show()
#课程热度统计
courses_hot=[]
for kc in kc_info[0]:
courses_hot.append((kc[1],kc[5]))
courses_hot.sort(key=lambda x:x[1], reverse=True)
bar_plot2(courses_hot)运行结果如下:
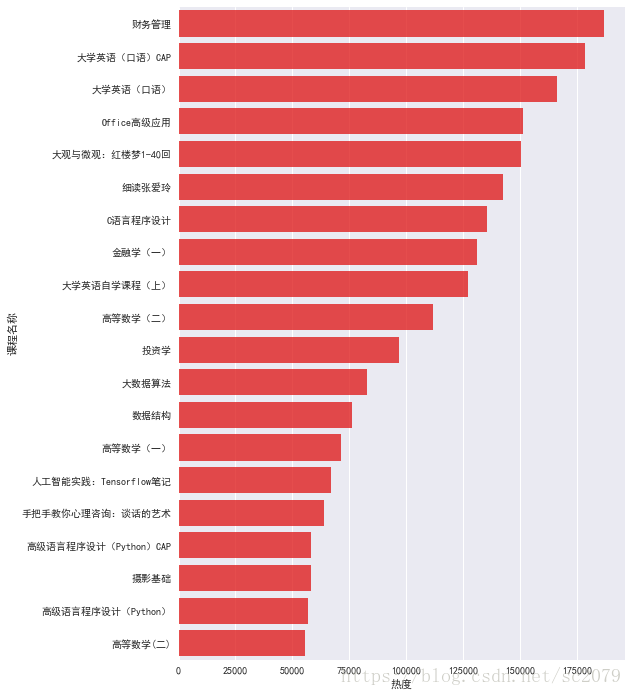
可以看出,财务管理最受欢迎,达到18万之多。另外,高数、编程类、英语口语类、财务类受欢迎度远超其他学科门类。
5、学科开课数统计
先统计各个学科的课程数量,为了绘图更简洁美观,有些课程少的我打包放进了“其它”。
num=5
subject_courses=[]
for i in range(1,len(tables)):
subject_courses.append((tables[i][0],len(kc_info[i])))
subject_courses.sort(key=lambda x:x[1], reverse=True)
left_courses=0
for i in range(num):
print(subject_courses[-i-1][1])
left_courses+=subject_courses[-i-1][1]
deal_subject_courses=subject_courses[0:len(subject_courses)-num]
deal_subject_courses.append(('others',left_courses))参考了网上一些代码,做了一些修改,如下:
def pie_plot(datas):
# # 饼状图
labels,sizes=[],[]
for i in range(len(datas)):
labels.append(datas[i][0])
sizes.append(datas[i][1])
# plot.figure(figsize=(8,8))
colors = ['red', 'yellow', 'blue', 'green','blueviolet','gold','pink','purple','tomato','white']
colors=colors[0:len(sizes)]
explode = (0.2, 0, 0, 0,0,0,0,0,0,0,0)
explode=explode[0:len(sizes)]
patches, l_text, p_text = plt.pie(sizes, explode=explode, labels=labels, colors=colors,
labeldistance=1.1, autopct='%2.1f%%', shadow=False,
startangle=-180, pctdistance=0.6)
# labeldistance,文本的位置离远点有多远,1.1指1.1倍半径的位置
# autopct,圆里面的文本格式,%3.1f%%表示小数有三位,整数有一位的浮点数
# shadow,饼是否有阴影
# startangle,起始角度,0,表示从0开始逆时针转,为第一块。一般选择从90度开始比较好看
# pctdistance,百分比的text离圆心的距离
# patches, l_texts, p_texts,为了得到饼图的返回值,p_texts饼图内部文本的,l_texts饼图外label的文本
# 改变文本的大小
# 方法是把每一个text遍历。调用set_size方法设置它的属性
for t in l_text:
t.set_size = 30
for t in p_text:
t.set_size = 20
# 设置x,y轴刻度一致,这样饼图才能是圆的
plt.axis('equal')
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
# loc: 表示legend的位置,包括'upper right','upper left','lower right','lower left'等
# bbox_to_anchor: 表示legend距离图形之间的距离,当出现图形与legend重叠时,可使用bbox_to_anchor进行调整legend的位置
# 由两个参数决定,第一个参数为legend距离左边的距离,第二个参数为距离下面的距离
plt.grid()
plt.show()运行结果如下:
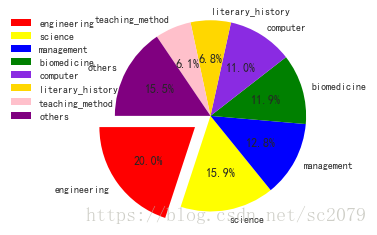
可以看出,理工类课程开课最多,管理类、生命科学类其次,文学历史、教育教学等相对较少。
另外,我还用了pyecharts生成动态图表
如:
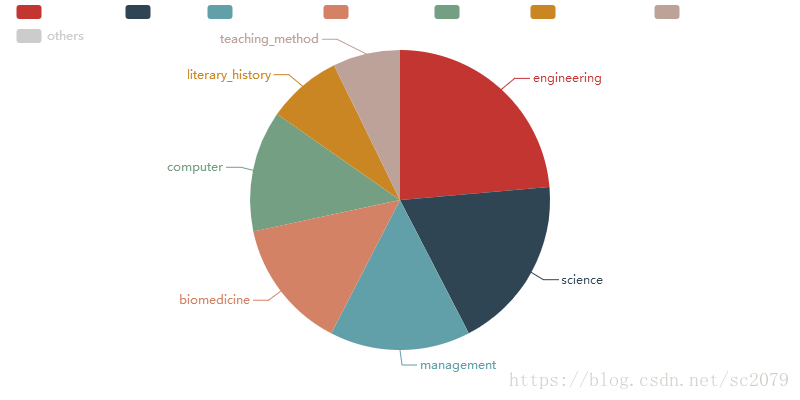
比较疑惑的是,最上边图例为什么没有注释(去掉这个学科便出现了)。如果有知道原因或解决方法的,欢迎留言或私戳,不甚感谢!
-
结语
其实还有很多可以做的,比如统计每个省份开课数(通过大学定位)、统计每月开课数等。有空再补吧!