//-----------------------------------------------------------------------------------
Android内存机制分析1——了解Android堆和栈
昨天用Gallery做了一个图片浏览选择开机画面的功能,当我加载的图片多了就出现OOM问题。以前也出现过这个问题,那时候并没有深究。这次打算好好分析一下Android的内存机制。
因为我以前是做VC++开发,因此对C++在Window下的内存机制还是比较了解。不过转到Android后,一直都没有刻意去处理内存问题,因为脑子里一直想着Java的GC机制。不过现在想想,自己对Android的GC和内存管理并不了解,自己写的代码在内存哪里运行都不清楚,心里不淡定啊。。。。
毕竟我以前写C++的时候,什么时候在哪里申请内存,什么时候释放内存,会不会栈溢出或者堆内存泄露都了如指掌。言归正传,今天打算先了解一下Android的堆和栈跟C++有何区别。
1、dalvik的Heap和Stack
这里说的只是dalvik java部分的内存,实际上除了dalvik部分,还有native。这个以后再说。

下面针对上面列出的数据类型进行说明,只有了解了我们申请的数据在哪里,才能更好掌控我们自己的程序。
2、对象实例数据
实际上是保存对象实例的属性,属性的类型和对象本身的类型标记等,但是不保存实例的方法。实例的方法是属于数据指令,是保存在Stack里面,也就是上面表格里面的类方法。
对象实例在Heap中分配好以后,会在stack中保存一个4字节的Heap内存地址,用来查找对象的实例。因为在Stack里面会用到Heap的实例,特别是调用实例的时候需要传入一个this指针。
3、方法内部变量
类方法的内部变量分为两种情况:简单类型保存在Stack中;对象类型在Stack中保存地址,在Heap 中保存值。
4、非静态方法和静态方法
非静态方法有一个隐含的传入参数,这个参数是dalvik虚拟机传进去的,这个隐含参数就是对象实例在Stack中的地址指针。因此非静态方法(在Stack中的指令代码)总是可以找到自己的专用数据(在Heap 中的对象属性值)。当然非静态方法也必须获得该隐含参数,因此非静态方法在调用前,必须先new一个对象实例,获得Stack中的地址指针,否则dalvik虚拟机将无法将隐含参数传给非静态方法。
静态方法没有隐含参数,因此也不需要new对象,只要class文件被ClassLoader load进入JVM的Stack,该静态方法即可被调用。所以我们可以直接使用类名调用类的方法。当然此时静态方法是存取不到Heap 中的对象属性的。
5、静态属性和动态属性
静态属性是保存在Stack中的,而不同于动态属性保存在Heap 中。正因为都是在Stack中,而Stack中指令和数据都是定长的,因此很容易算出偏移量,所以类方法(静态和非静态)都可以访问到类的静态属性。也正因为静态属性被保存在Stack中,所以具有了全局属性。
6、总结
Android内存机制分析2——分析APP内存使用情况
1、APP默认分配内存大小
在Android里,程序内存被分为2部分:native和dalvik,dalvik就是我们普通的java使用内存,也就是我们上一篇文章分析堆栈的时候使用的内存。我们创建的对象是在这里面分配的,对于内存的限制是 native+dalvik 不能超过最大限制。android程序内存一般限制在16M,也有的是24M(早期的Android系统G1,就是只有16M)。具体看定制系统的设置,在Linux初始化代码里面Init.c,可以查到到默认的内存大小。有兴趣的朋友,可以分析一下虚拟机启动相关代码。这块比较深入,目前我也没时间去分析,后面有空会去钻研一下。

//Edited by mythou
//http://www.cnblogs.com/mythou/
gDvm.heapSizeStart = 2 * 1024 * 1024; // heap初始化大小为2M
gDvm.heapSizeMax = 16 * 1024 * 1024; // 最大的heap为16M
2、Android的GC如何回收内存
Android的一个应用程序的内存泄露对别的应用程序影响不大。为了能够使得Android应用程序安全且快速的运行,Android的每个应用程序都会使用一个专有的Dalvik虚拟机实例来运行,它是由Zygote服务进程孵化出来的,也就是说每个应用程序都是在属于自己的进程中运行的。Android为不同类型的进程分配了不同的内存使用上限,如果程序在运行过程中出现了内存泄漏的而造成应用进程使用的内存超过了这个上限,则会被系统视为内存泄漏,从而被kill掉,这使得仅仅自己的进程被kill掉,而不会影响其他进程(如果是system_process等系统进程出问题的话,则会引起系统重启)。
做应用开发的时候,你需要了解系统的GC(垃圾回收)机制是如何运行的,Android里面使用有向图作为遍历回收内存的机制。Java将引用关系考虑为图的有向边,有向边从引用者指向引用对象。线程对象可以作为有向图的起始顶点,该图就是从起始顶点开始的一棵树,根顶点可以到达的对象都是有效对象,GC不会回收这些对象。如果某个对象 (连通子图)与这个根顶点不可达(注意,该图为有向图),那么我们认为这个(这些)对象不再被引用,可以被GC回收。
因此对于我们已经不需要使用的对象,我们可以把它设置为null,这样当GC运行的时候,就好遍历到你这个对象已经没有引用,会自动把该对象占用的内存回收。我们没法像C++那样马上释放不需要的内存,但是我们可以主动告诉系统,哪些内存可以回收了。
3、查看应用内存使用情况
下面我们看看如何在开发过程中查看我们程序运行时内存使用情况。我们可以通过ADB的一个命令查看:
//Edited by mythou
//http://www.cnblogs.com/mythou/
//$package_name:应用包名
//$pid:应用进程ID,可以用PS命令查看
adb shell dumpsys meminfo $package_name or $pid
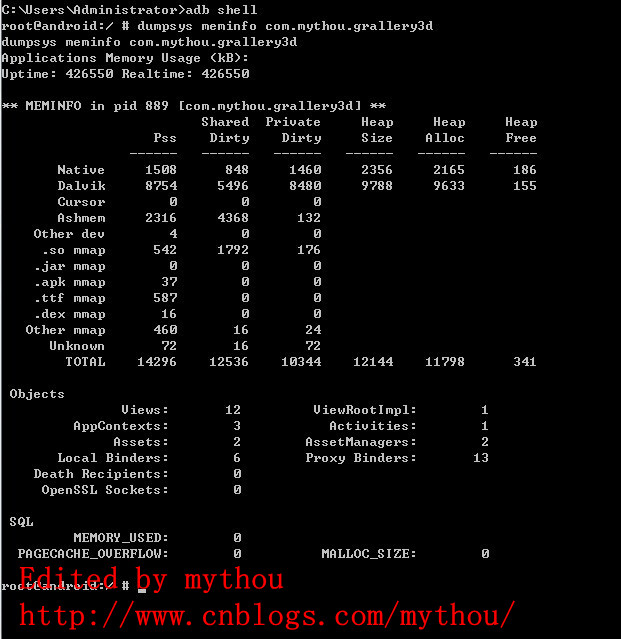
上面是我使用包名查看Gallery例子的内存使用情况图,里面信息很多,不过我们主要关注的是native和Davilk的使用情况。(Android2.X和Android4.X查看的信息排序是不一样的,内容差不多,不过排布有差异,我上面是4.0的截图)
Android底层内核是基于Linux的,而Linux里面相对Window来说,有一点很特别的是,会尽量使用系统内存加载一些缓存数据或者进程间共享数据。Linux本着不用白不用的原则,会尽量使用系统内存,加快我们应用的运行速度。当然,如果我们期待某个需要大内存的应用,系统也能马上释放出一定的内存使用,这是系统内部调度实现。因此严格来说,我们要准备计算Linux下某个进程内存大小比较困难。 因为有paging out to disk(换页),所以如果你把所有映射到进程的内存相加,它可能大于你的内存的实际物理大小。
- dalvik:是指dalvik所使用的内存。
- native:是被native堆使用的内存。应该指使用CC++在堆上分配的内存。
- other:是指除dalvik和native使用的内存。但是具体是指什么呢?至少包括在CC++分配的非堆内存,比如分配在栈上的内存。puzlle!
- Pss:它是把共享内存根据一定比例分摊到共享它的各个进程来计算所得到进程使用内存。网上又说是比例分配共享库占用的内存,也就是上面所说的进程共享问题。
- PrivateDirty:它是指非共享的,又不能换页出去(can not be paged to disk )的内存的大小。比如Linux为了提高分配内存速度而缓冲的小对象,即使你的进程结束,该内存也不会释放掉,它只是又重新回到缓冲中而已。
- SharedDirty:参照PrivateDirty我认为它应该是指共享的,又不能换页出去(can not be paged to disk )的内存的大小。比如Linux为了提高分配内存速度而缓冲的小对象,即使所有共享它的进程结束,该内存也不会释放掉,它只是又重新回到缓冲中而已。
上面针对meminfo里面的信息给出解析,这些很多我是参考了网上一些文章,所以如果有理解不到位的,欢迎各位指出。
4、程序中获取内存信息
通过ActivityManager获取相关信息,下面是一个例子代码:
//Edited by mythou
//http://www.cnblogs.com/mythou/
private void displayBriefMemory()
{ final ActivityManager activityManager = (ActivityManager) getSystemService(ACTIVITY_SERVICE); ActivityManager.MemoryInfo info = new ActivityManager.MemoryInfo(); activityManager.getMemoryInfo(info); Log.i(tag,"系统剩余内存:"+(info.availMem >> 10)+"k"); Log.i(tag,"系统是否处于低内存运行:"+info.lowMemory); Log.i(tag,"当系统剩余内存低于"+info.threshold+"时就看成低内存运行"); }
另外通过Debug的getMemoryInfo(Debug.MemoryInfo memoryInfo)可以得到更加详细的信息。跟我们在ADB Shell看到的信息一样比较详细。