
前言
上一篇文章主要讲了如何解析网页,本篇文章主要来写一下如何发起请求。可能看过前两篇文章的人就开始疑惑了,请求?你不是说一行代码就可以搞定了么。的确,一行代码就能搞定。但是请求部分既然扮演着浏览器的角色,我们是不是应该尽量让它变得和浏览器一样。而我在第一篇文章中也讲到,爬虫是模拟人的行为去获取数据。那么我们就需要知道,一个人去访问网站有什么样的行为?爬虫怎么去模拟人的行为?
请求头
当一个人打开浏览器输入网址敲下回车,会发起一个HTTP请求,即Request,来访问网站服务端,服务端接收请求并返回响应内容,即Response。在发起请求时,Request会有一个请求头,即Headers,来描述请求信息,例如Content-type、User-Agent、cookie等。相对的也会有一个响应头,这里不多关注。
User-Agent
在爬虫程序的开发中,请求头中必须添加的就是User-Agent。UA记录了浏览器、操作系统、版本等信息,很多网站会通过检测UA来判断是否是爬虫程序发起的请求。
Chrome浏览器请求头信息:
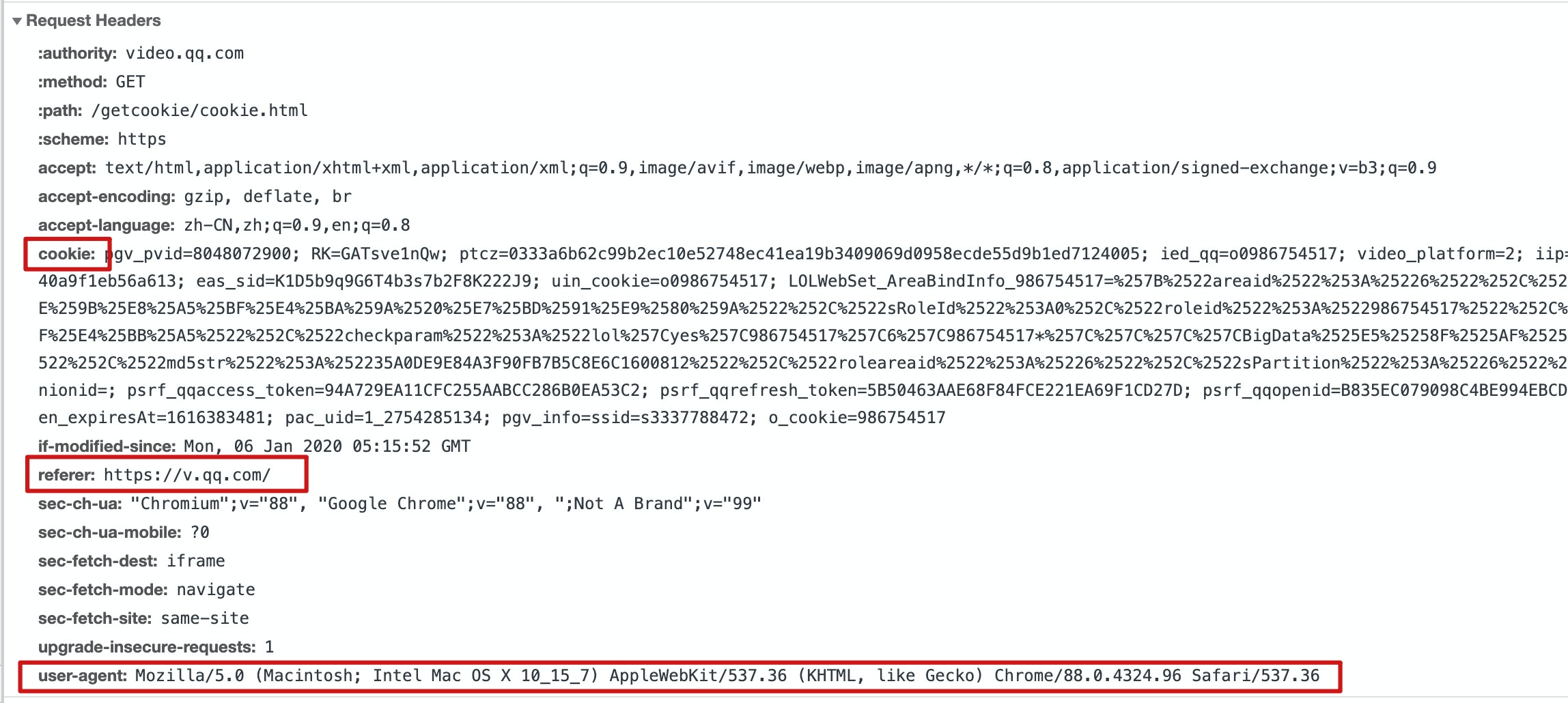
爬虫程序请求头信息:
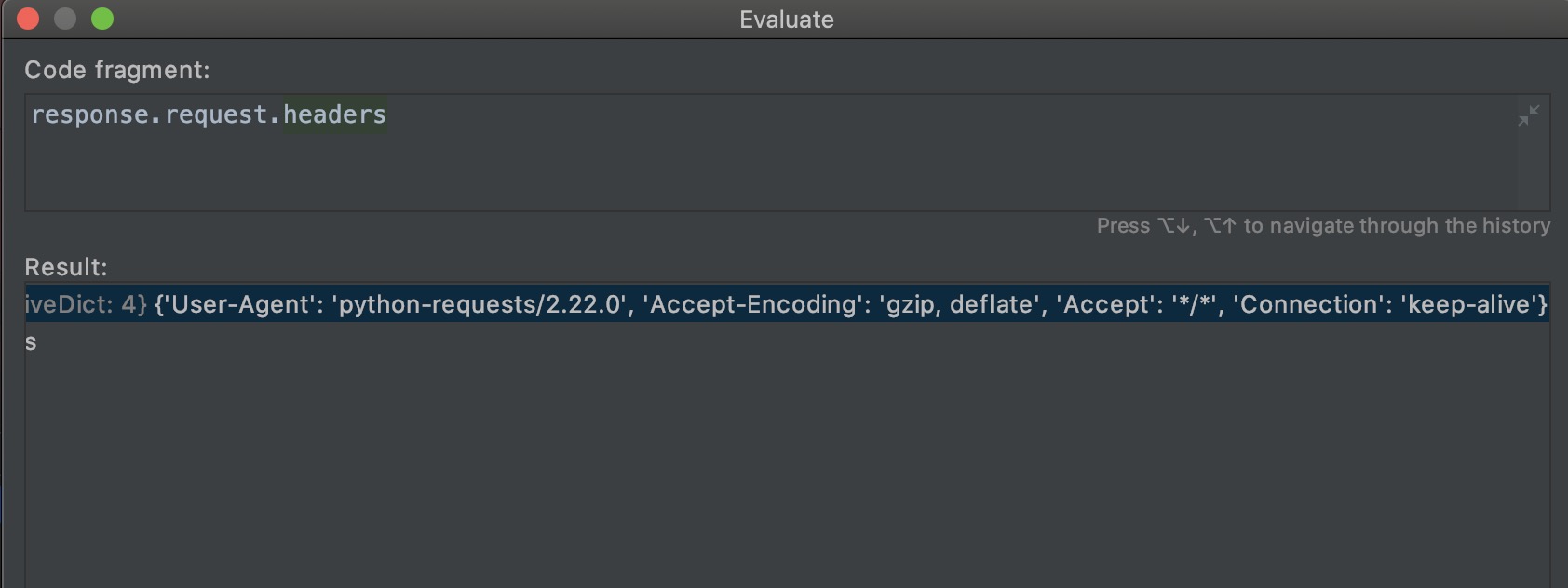
从上图可以看出,Python爬虫的UA默认的python-requests,所以我们要修改爬虫程序的UA。
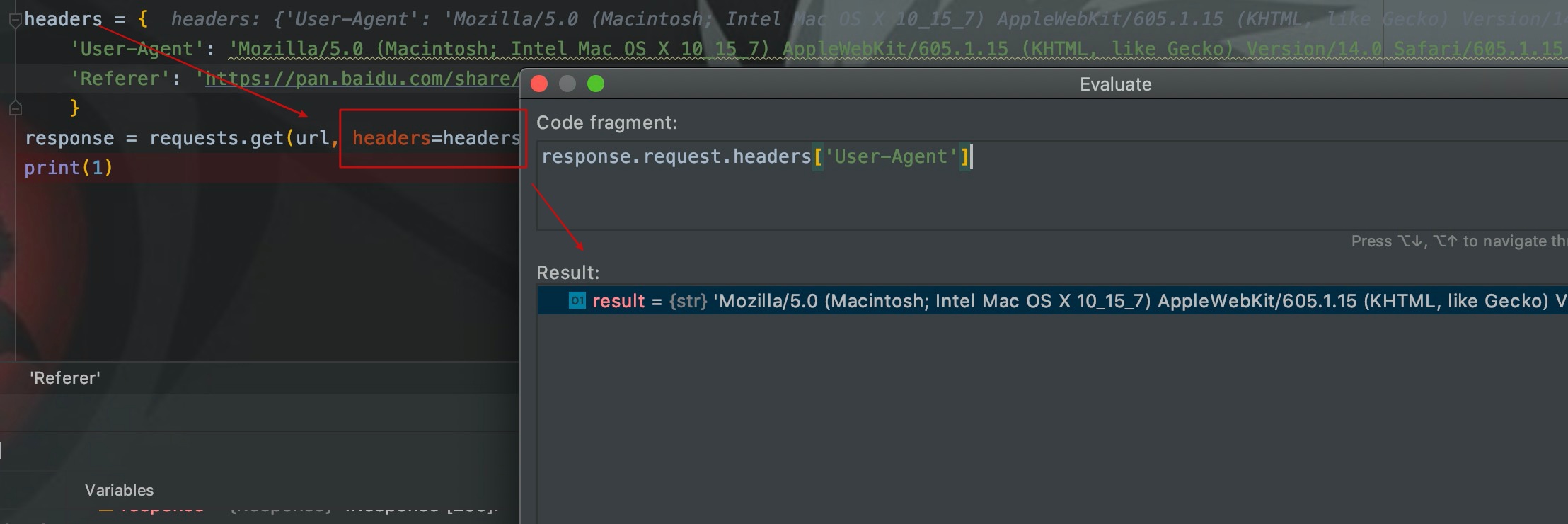
我们通过headers参数在请求头添加UA,这样默认的UA就会被修改。
cookie
至于其他属性,比较关注的就是cookie。在web开发中,服务端在用户第一次访问时生成cookie,并通过响应头中的Set-Cookie属性,返回浏览器并被持久化。在cookie的有效期内访问服务端,浏览器都会在请求头中带着cookie,以此来表明自己的身份。
这里以百度网盘为例来说明。
这时我还没有登录百度网盘,同时清理了浏览器中所有关于百度网盘的cookie。第一次访问分享链接时,服务端通过响应头会返回一个cookie给浏览器。
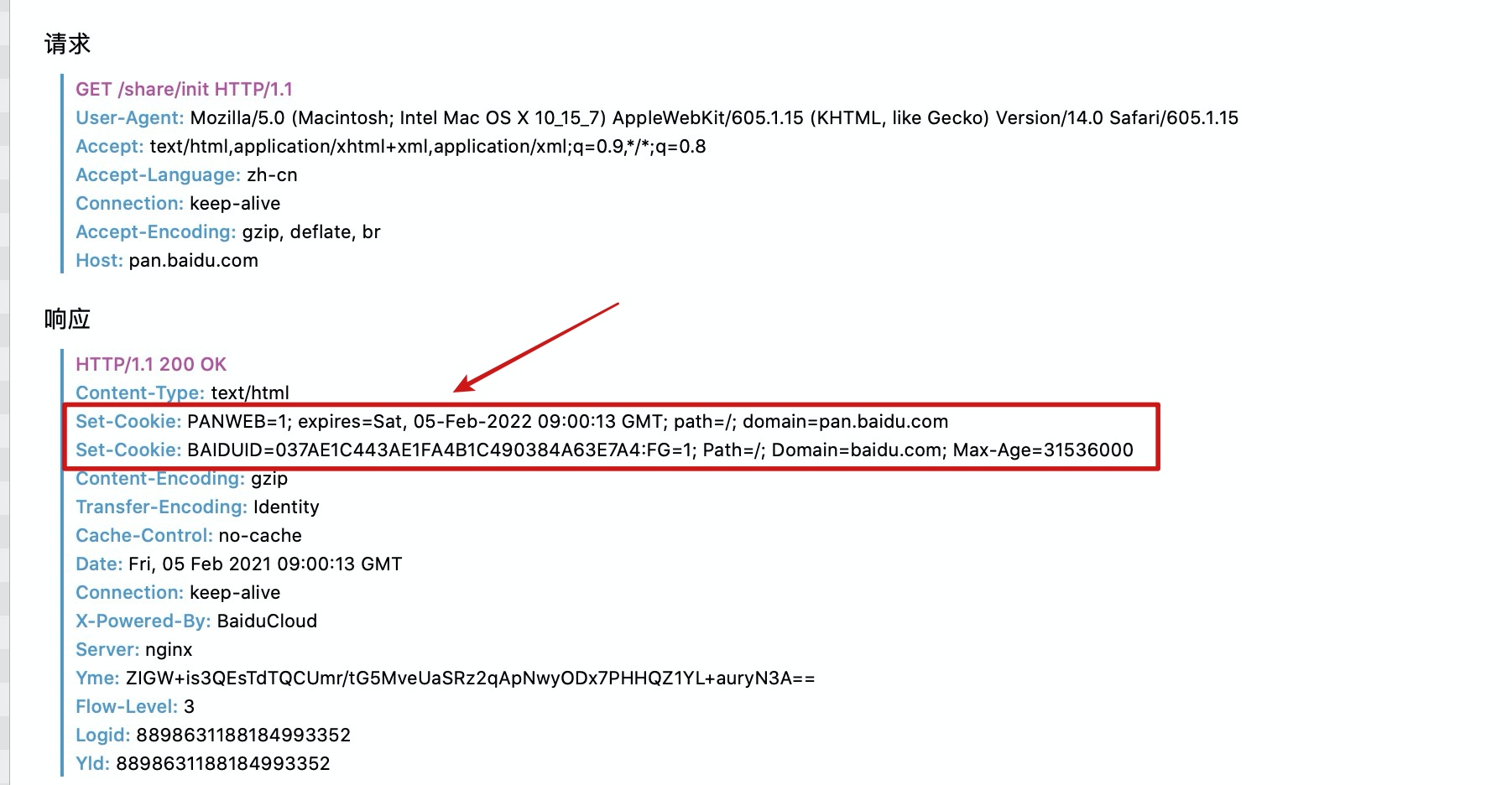
当我刷新页面再次请求时,请求头中就有了之前cookie属性。
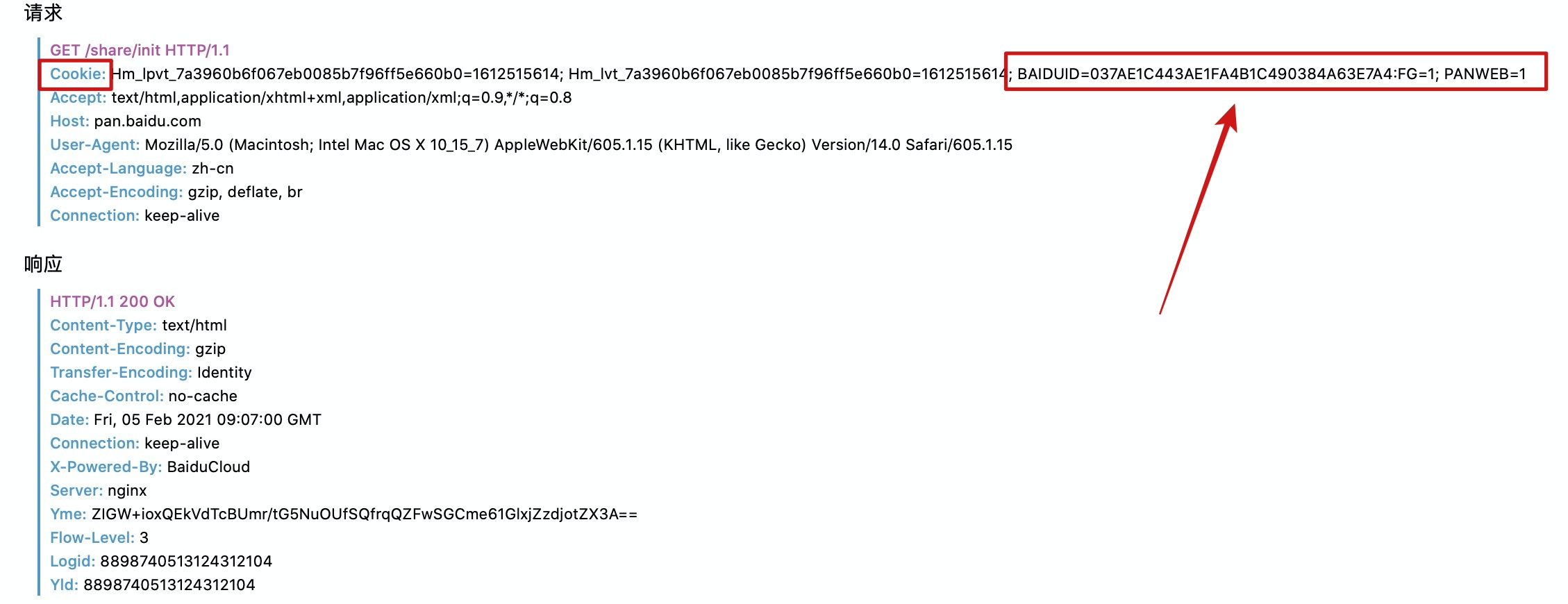
到这里,cookie的来源和基本用法其实就讲完了。为了更好的去让大家了解一下cookie,我又多写了一部分。
此时访问任何有提取码的分享链接,仍然都需要输入提取码,因为我们没有登陆百度网盘,目前的cookie不足以向百度网盘表明我的用户信息。但是,如果我们在登录了百度云盘账号的浏览器中,访问自己的分享链接则不需要输入提取码,就是下面这种情况。
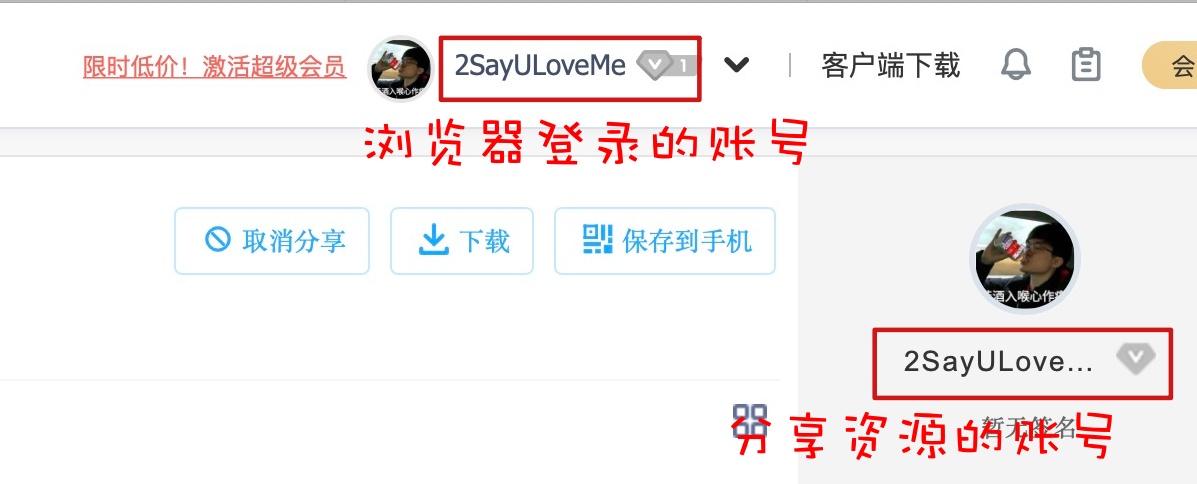
再次强调,是访问自己账号分享的资源链接不需要输入提取码。
我登录了自己百度云盘后,开始访问自己的分享链接,没有输入提取码就直接访问到了资源,这是为啥?这就是cookie的力量!!。
登录百度网盘:

假设这是第一次登录百度云盘,百度云盘生成了cookie返回给浏览器,这里我们只关注PANPAS这个字段的变化。
我们看一下此刻浏览器存储的cookie值:
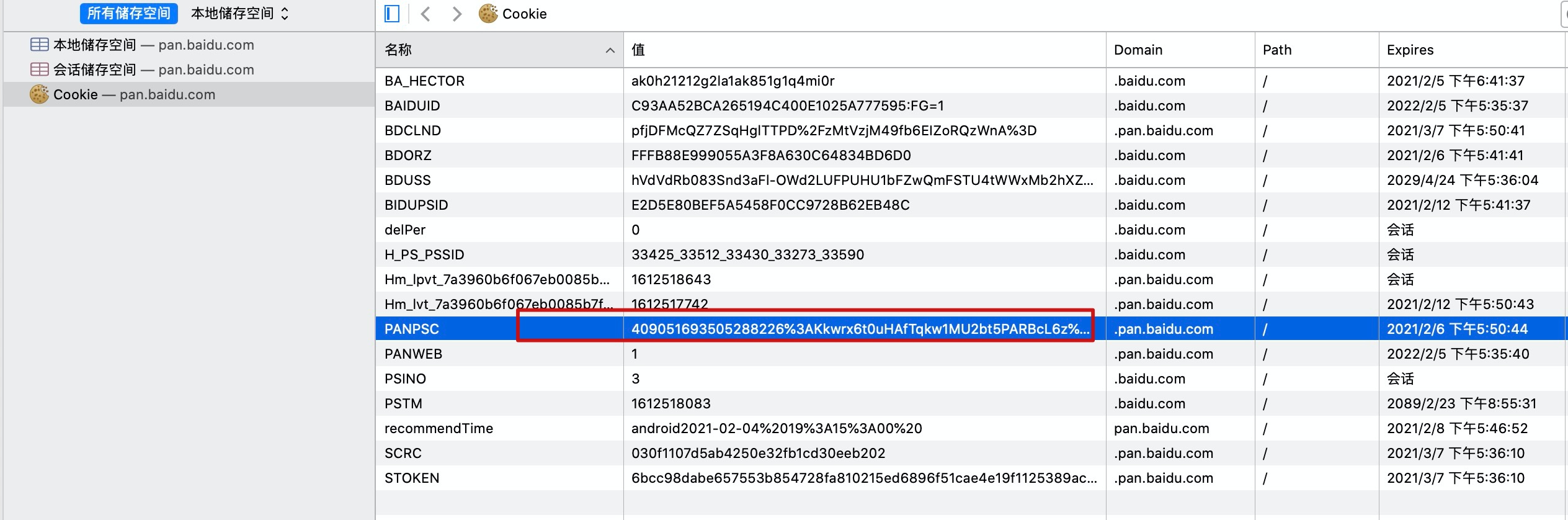
浏览器存储的cookie和第一次登录百度云盘返回的cookie是一样的。
这时我们刷新页面再次访问:
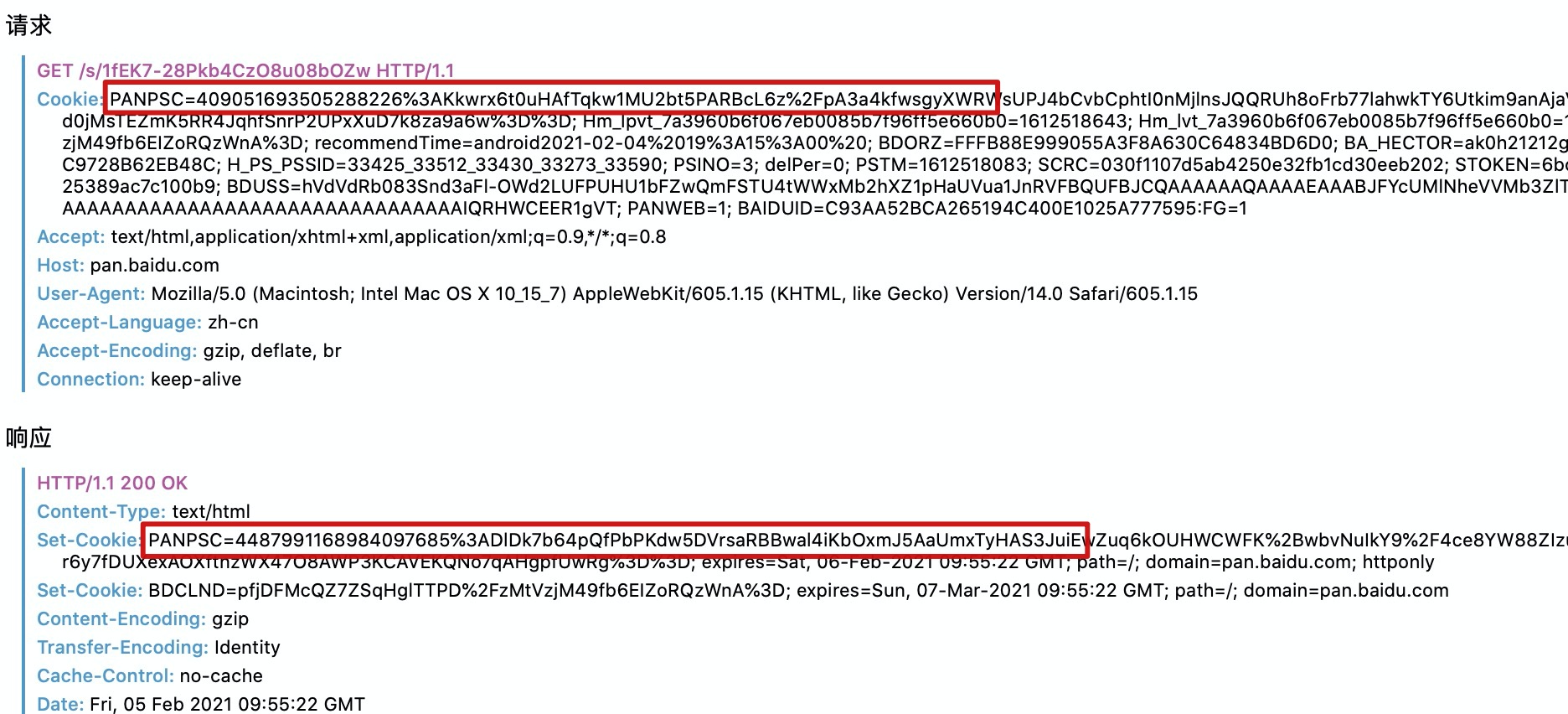
我们发现请求头中携带了刚刚浏览器存储的cookie,但是响应头中又返回了一个新的cookie,我们再看一下浏览器中此刻存储的cookie:
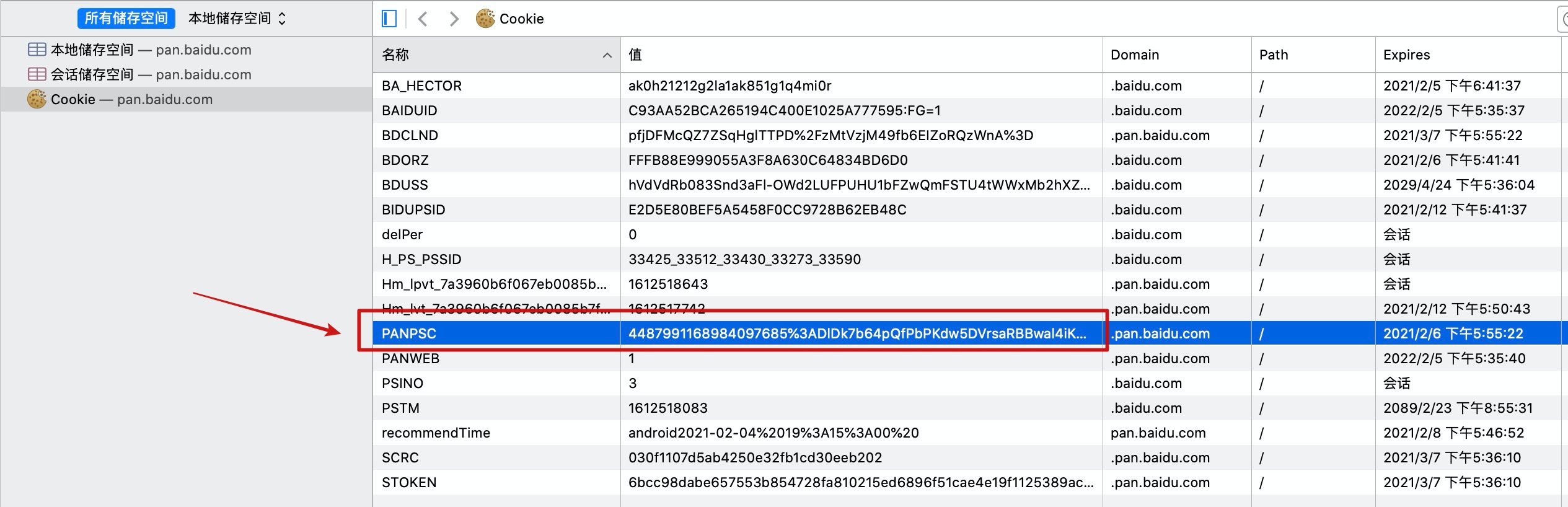
此刻,浏览器中存储的cookie已经变成了最新的。从这里就能看出每次访问百度网盘,服务端都会新建一个cookie返回给浏览器,覆盖之前的cookie。但是大部分网站都是在用户第一次请求或者cookie过期时才会新建cookie,这里就不需要过多纠结。我们只需要知道:cookie代表了用户信息即可。
上面主要就是一些cookie的简单理论,现在我们从代码中来看cookie如何应用。
首先我们不加cookie来访问我的百度云盘分享链接:

我们从网页内容可以看出,进入的是输入提取码的页面。
这时,我们将登录了百度网盘的浏览器中的cookie复制过来,放在请求头中再次执行。
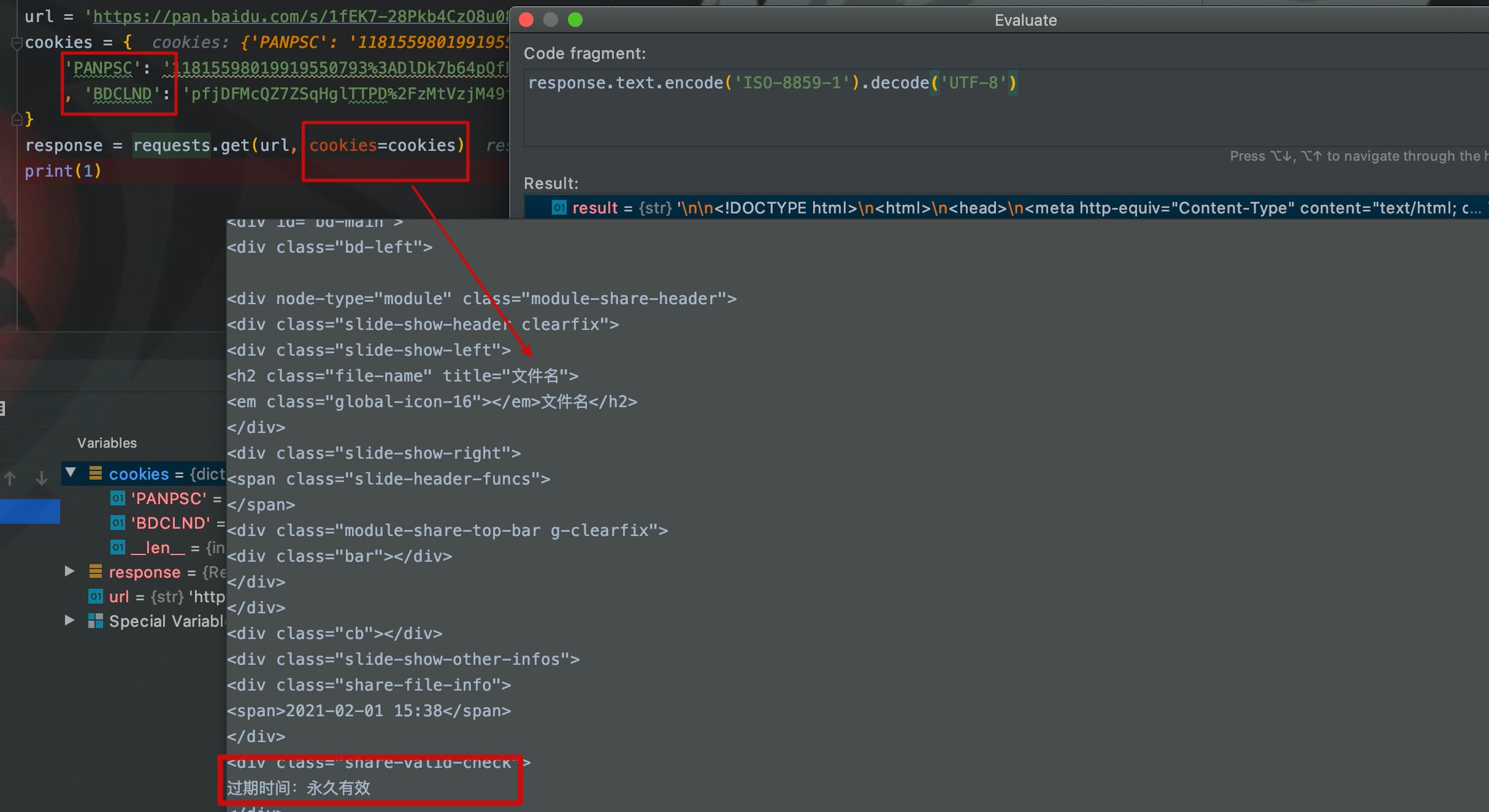
如图,请求头在携带了cookie之后访问我自己的分享链接,就直接访问到了资源页面,而不再是输入提取码页面。
大概流程再整一下:爬虫程序带着cookie去访问分享链接,百度云盘一看这个cookie代表的人和资源分享人居然是同一个人,那就不需要再重定向到输入提取码页面了,直接访问资源就可以了。
referer
referer代表的是从哪个url跳转到此页面的,通常用来判断此次请求是否是从网站内点击触发的。例如我从腾讯视频的动漫频道点进去斗罗大陆播放页,则跳转到斗罗大陆页面请求的referer就是动漫频道的url。
如图,/channle/cartoon代表的就是动漫频道。

这个属性平时不怎么用。到目前为止,我就只在一次爬虫程序开发中,遇到过这个问题,网站通过检测referer来判定你是否是直接访问的这个url,后来我就将网站首页的url填到了每个请求头referer中。
用法可以看UA那个程序截图。
请求频率
众所周知,程序的运行速度是非常快的。假如我们爬取一个网站,这个网站有1w个页面,我们在代码中循环请求1w次,启动程序,或许几秒钟就搞定了,但是你认为一个人会有这么快的请求频率么。所以我们需要限制请求间隔,方法很简单。
Java
Thread.sleep(millis)
Python
time.sleep(secs)
Scrapy爬虫框架
# settings中,0.3代表0.3s
DOWNLOAD_DELAY = 0.3
代理IP
很多网站识别爬虫程序的基本手段就是通过请求频率来判断,即记录一个IP在一段时间内请求了多少次。所以如果我们有足够的代理IP,就可以提高请求频率。
通常获取代理IP的方法有付费购买和从免费代理IP网站获取,之前的西刺代理就是专门提供免费代理IP的网站,但免费代理IP的存活率通常不高。很多人就开始专门设计程序来构建代理IP池,获取了免费代理IP之后,通过程序反复验证代理IP的存活性。这里主要先说明爬虫程序中入门如何添加代理IP。
这里我找了一个代理IP,添加在了代码中。
import requests
url = 'https://ipinfo.io'
proxies = {
'https': 'https://183.220.xxx.xx:80'
}
response = requests.get(url, proxies=proxies)
print(response.text)
对IP识别网站发起请求并输出结果。
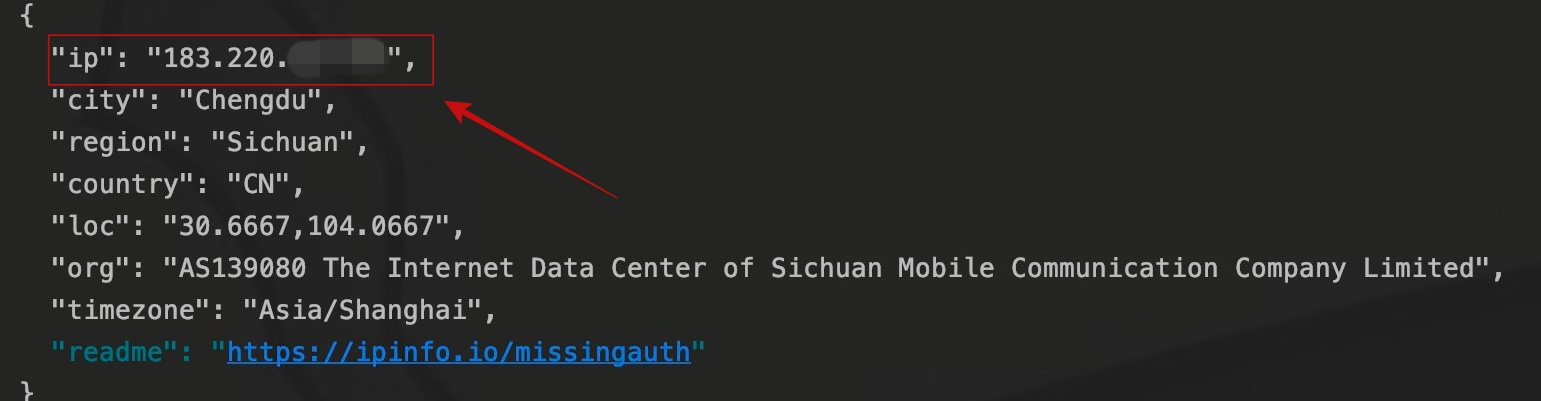
爬虫程序的IP已经不再是爬虫运行主机IP,而变成了代理IP。至于代理池的构建,可能以后我会写一下。
结语
本篇文章从请求头、请求频率、代理IP三个方面,讲述了爬虫如何去模拟人的行为,这是爬虫程序开发最基本的常识,也是最常见的应对反爬虫的方法。有时候,一个爬虫程序的好坏,并不是取决爬虫程序的性能,而是取决于网站是否能识别出这是个爬虫程序。
知道了这些,是否就可以肆无忌惮的去爬取数据了呢?其实是不可以的,我们爬取数据一定要在合理合法的范围内,亦不可逾越法律底线。所以下篇文章主要讲一下自己对数据爬取规范的一些理解。期待下一次相遇。
写的都是日常工作中的亲身实践,处于自己的角度从0写到1,保证能够真正让大家看懂。
文章会在公众号 [入门到放弃之路] 首发,期待你的关注。
