本文是对近期有关大规模预训练语言模型方法的综述
对预训练语言模型(LM)进行微调已成为在自然语言处理中进行迁移学习的事实上的标准。在过去的三年中(Ruder,2018),微调(Howard&Ruder,2018)取代了预训练嵌入特征提取的使用(Peters et al., 2018),而预训练语言模型在翻译(McCann et al., 2018)、自然语言推理(Conneau et al., 2017)和其他任务中也更受青睐,因为预训练模型提高了样本效率和性能(Zhang and Bowman, 2018)。这些方法的成功经验导致了更大模型的发展 (Devlin et al., 2019; Raffel et al., 2020)。实际上,最近的模型是如此之大,以至于它们可以在不进行任何参数更新的情况下达到合理的性能 (Brown et al., 2020)。对zero-shot来说虽然有一定的局限性,但是,为了获得最佳性能或保持合理的效率,在实践中使用大型预训练的语言模型时,微调将继续成为最普遍的操作方式。
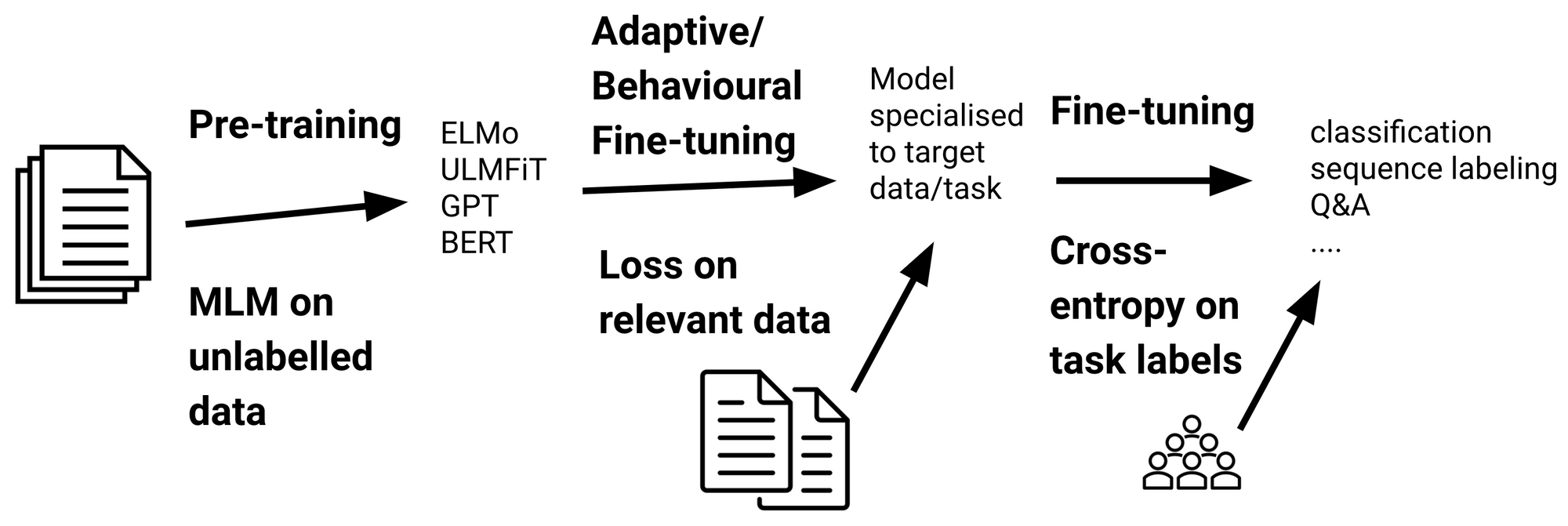
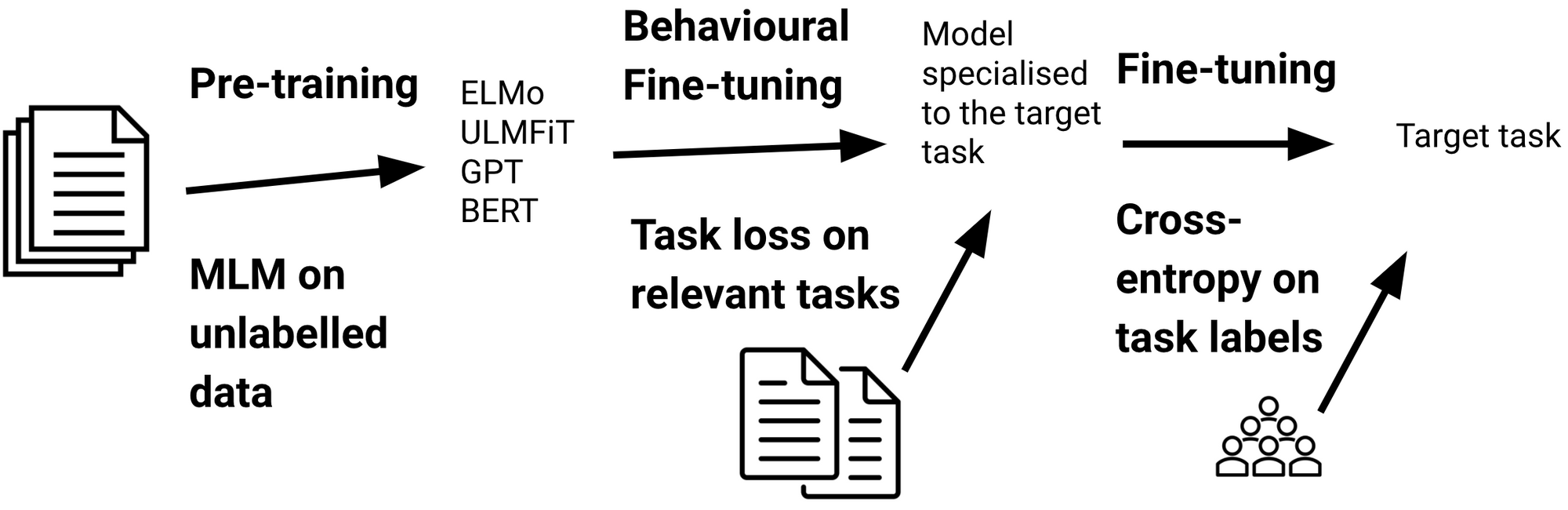
在标准的迁移学习过程中,模型首先使用诸如掩码语言建模之类的语言模型损失在大量未标记数据上对模型进行预训练,然后用下游任务的标记数据对预训练模型使用交叉熵损失进行微调。
标准的预训练—微调过程 (adapted from (Ruder et al., 2019))
虽然预训练是计算密集型的,但微调可以相对便宜地完成。对于下载和微调了数百万次预训练模型的实际使用而言微调是更为重要(see the Hugging Face models repository)。因此,微调是本文的重点。特别的,在下文,我将重点介绍影响或可能改变我们微调语言模型的方式的最新进展。
本文讨论的微调方法
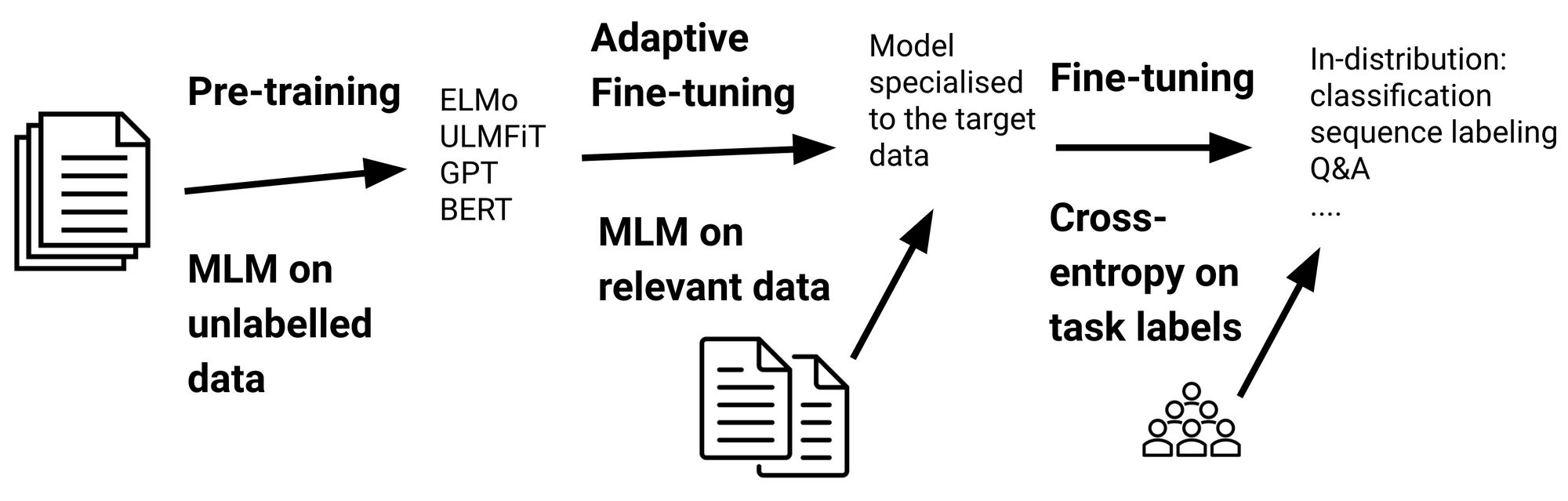
自适应微调
尽管就分布外的泛化而言,预训练的语言模型比以前的模型更健壮,但它们依然不能很好地处理与预训练数据大不相同的数据。自适应微调是一种通过数据对模型进行微调的方式使模型的数据分布更接近目标数据的分布。通过下图可知,具体而言,自适应微调在特定任务的微调之前,涉及对附加数据上的模型进行微调。重要的是,该模型已根据预训练目标进行了微调,因此自适应微调仅需要未标记的数据。
自适应微调是标准迁移学习的一部分。 在更接近目标分布的数据上使用预训练损失(通常是掩码语言建模)来训练预训练模型。
正式的,由给定的特征空间X 组成的目标域DT,其中边缘概率分布P(X),X={x1,…,xn}∈X(Pan and Yang, 2009; Ruder, 2019),自适应微调可以学习到特征空间X和目标数据P(X)的分布。
自适应微调的变体(域,任务和语言自适应微调)用于使模型各自适应目标域、目标任务和目标语言的数据。 Dai and Le (2015)第一个展示了领域自适应微调的优势。Howard and Ruder (2018)后来通过微调域内数据作为ULMFiT的一部分提高的采样效率。他们还提出了任务自适应的微调功能,该功能可以根据任务训练数据上的预训练目标对模型进行微调。与独热(one-hot)标签任务上的交叉熵相比,使用预训练损失为目标数据建模提供了更丰富的信息,因此任务自适应的微调比常规的微调有用。此外,自适应微调和常规微调也可以通过多任务学习共同进行。(Chronopoulou et al., 2019)。
域和任务自适应的微调最近已应用于最新一代的预训练模型 (Logeswaran et al., 2019; Han and Eisenstein, 2019; Mehri et al., 2019)。 Gururangan et al. (2020)表明适应目标领域和目标任务的数据是互补的。最近,Pfeiffer et al. (2020)提出了语言自适应的微调,以使模型适应新的语言。
自适应微调模型专用于特定的数据分布,它将能够使模型性能更好。但是,这是以其成为通用语言模型的能力为代价的。因此,当对单个领域的(可能有多个)任务的性能要求很高时,自适应微调最有用;如果应将预训练模型应用于大量领域,则自适应微调的计算效率低下。
行为的微调
自适应微调使我们可以将模型专门化为DT,它并没有直接告诉我们有关目标任务的任何信息。 正式的, 由标签空间 Yy组成一个目标任务Tt , 先验分布为P(Y) Y={y1,…,yn}∈Y ,条件概率为 P(Y|X)。另外,如下午所示,我们可以通过在相关任务上进行微调来指导一个模型学到对完成目标任务有用的功能。我们把这种模式称为行为的微调,因为它着重于学习有用的行为并将其与自适应微调区分开来。
预训练模型的行为微调。对与目标任务相关的任务,使用特定于任务的监督目标或自我监督目标,对预训练模型进行了训练
 .
.
教授模型相关功能的一种方法是在特定任务的微调之前,用相关任务的相关标记数据对其进行微调(Phang et al., 2018)。这种所谓的中间任务训练最适合需要高层次推断和推理能力的任务(Pruksachatkun et al., 2020; Phang et al., 2020)。用标签数据进行行为微调常常用于教授模型有关于命名实体(Broscheit, 2019)、语义 (Arase and Tsujii, 2019)、语法(Glavaš and Vulić, 2020)、结果句子的选择 (Garg et al., 2020)、问答(Khashabi et al., 2020)的信息。Aghajanyan et al. (2021)通过在大规模的多任务过程中微调约50个带标签的数据集观察到大量、多样性的数据集的任务对于提升迁移学习的性能是非常关键的。
由于通常很难获得此类高级推理任务的监督数据,因此我们可以在目标上进行训练,这些目标教授模型以自我监督的方式进行学习与下游任务相关的功能。例如, Dou and Neubig (2021)对一个单词对齐模型进行微调,其目标是教它识别平行句子,而不是其他。Sellam et al. (2020)通过一系列句子相似度信号对BERT进行微调以进行质量评估。在这两种情况下,学习信号的多样性都很重要。
另一种有效的方法是将目标任务构建为掩码语言建模的形式。为此,Ben-David et al. (2020) 提出了基于桥接目标的微调用于情感领域自适应模型。其他人提出了预训练目标,也可以在微调过程中类似地使用: Ram et al. (2021)使用跨度选择任务对QA模型进行预训练,而Bansal et al. (2020)通过自动生成完形填空的多分类任务对少样本学习模型进行预训练。
区分自适应微调和行为微调鼓励我们考虑旨在引入模型的归纳偏差,以及它们是否与领域D或任务T的性质有关。理清领域和任务的作用是重要的,因为有关域的信息往往能利用有限的未标记的数据,而目前的方法要获得高层次的自然语言理解能力通常需要数十亿的训练数据样本(Zhang et al., 2020)。然而,当我们根据预训练目标来构建任务时,任务和领域之间的区别变得更加模糊。诸如MLM之类的足够通用的预训练任务或许可以为学习P(X/Y)提供有用的信息,但是很大可能不能完全涵盖从任务中引入的所有信号。例如,经过MLM预训练的模型与模型负例,数字或命名实体发生冲突 (Rogers et al., 2020)。
类似的,使用数据增强模糊D和T的角色让它允许我们直接在数据中编码所需的功能。例如,通过对文本模型进行微调,其中把性别换成了相反性别的词,可以使该模型对性别偏见更加健壮 (Zhao et al., 2018; Zhao et al., 2019; Manela et al., 2021)。
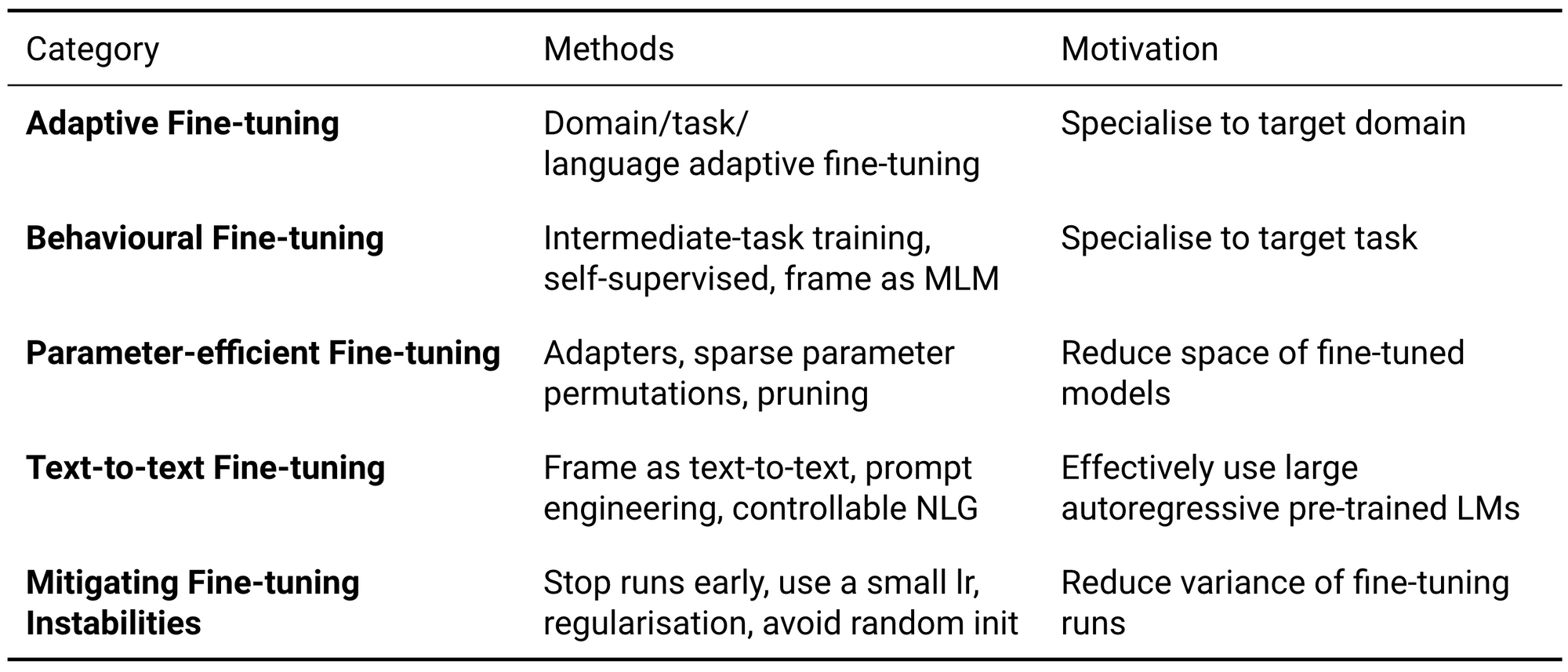
参数有效的微调
当需要在许多场景中对模型进行微调(例如针对大量用户)时,为每种情况存储微调模型的副本在计算上都非常昂贵的。因此,最近的工作集中在保持大多数模型参数固定,并对每个任务微调少量参数。实际上,这可以存储大型模型的单个副本和具有许多基于特定任务的修改的小文件。
有关这条线上的工作的第一种方法是基于适配器(Rebuffi et al., 2017),在参数固定的预训练模型的各层之间插入的小瓶颈层 (Houlsby et al., 2019; Stickland and Murray, 2019)。适配器提供通用设置,例如在训练过程中存储多个检查点,以及更高级更节省空间的技术(例如,检查点平均 (Izmailov et al., 2018),快照集成(Huang et al., 2017)和时序集成(Laine and Aila, 2017))。用适配器,一个通用模型可以有效地适应许多场景,例如不同的语言(Bapna and Firat, 2019)。 Pfeiffer et al. (2020)近期研究表明,适配器是模块化的,可以通过堆叠进行组合,从而可以独立学习专门的表示形式。在使用前面讨论的方法时,这特别有用:无需进行任何特定于任务的微调,通过将经过训练的任务适配器堆叠在自适应微调或性能微调的适配器上,就可以对适配器进行评估。可以在下面看到这种场景,将经过命名实体识别(NER)训练的任务适配器堆叠在英语(左)或Quechua语言(右)适配器上。
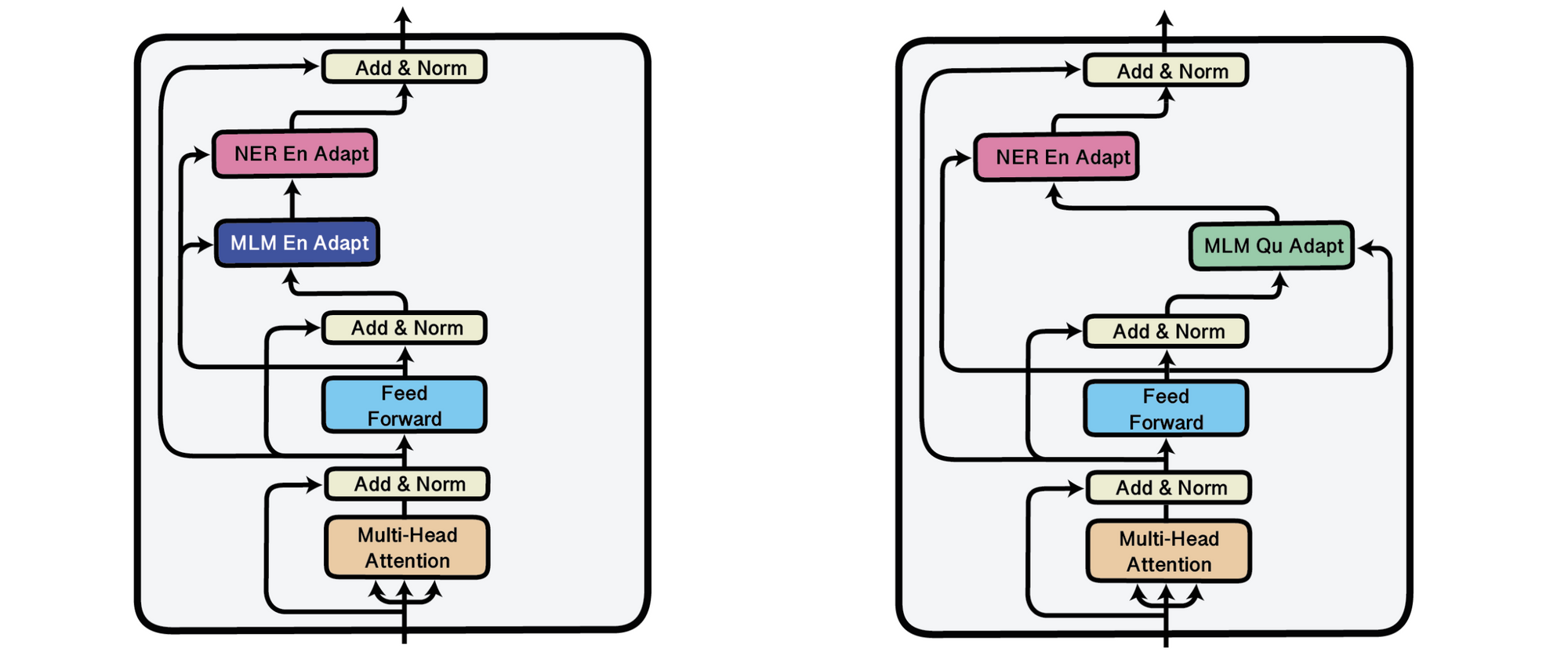
在MAD-X框架的Transformer块中插入的任务和语言适配器(Pfeiffer et al., 2020).
适配器学习封装的表示形式,并且可以彼此替换,适用零样本学习.
适配器在不更改基础参数的情况下修改模型的激活,而另一项工作是直接修改预先训练的参数。为了说明这套方法,我们可以将微调视为学习如何扰动预训练模型的参数。形式上,为了获得微调模型的参数,其中模型表示为![]() ,D是模型的维度,我们学习了基于特定任务的参数向量
,D是模型的维度,我们学习了基于特定任务的参数向量![]() ,该向量捕获了如何更改预训练的模型参数
,该向量捕获了如何更改预训练的模型参数![]() 。微调的参数是将基于特定任务的排列应用于预训练参数的结果:
。微调的参数是将基于特定任务的排列应用于预训练参数的结果:
 我们可以存储一个单一的
我们可以存储一个单一的 模型参数和对每一项任务对应的一个
模型参数和对每一项任务对应的一个 模型参数,而不是每一项任务的
模型参数,而不是每一项任务的![]() 模型参数。如果我们可以更有效地参数化,则此设置更便宜。为此,Guo et al. (2020)把当作稀疏向量来学习。Aghajanyan et al. (2020)设定
模型参数。如果我们可以更有效地参数化,则此设置更便宜。为此,Guo et al. (2020)把当作稀疏向量来学习。Aghajanyan et al. (2020)设定![]() ,其中
,其中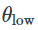 是一个低维向量,M是一个随机的线性映射(在这个案例中,可以快速迁移(Li et al., 2018))。或者,我们可以仅对预训练参数的子集进行修改。在计算机视觉领域一个典型方法是只微调模型的最后一层。假设是模型所有层L上的预训练参数的集合,
是一个低维向量,M是一个随机的线性映射(在这个案例中,可以快速迁移(Li et al., 2018))。或者,我们可以仅对预训练参数的子集进行修改。在计算机视觉领域一个典型方法是只微调模型的最后一层。假设是模型所有层L上的预训练参数的集合,![]() ,其中
,其中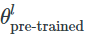 是L-th层的参数向量,
是L-th层的参数向量,![]() 和具有类似的表示法。只对最后一层进行微调等价于:
和具有类似的表示法。只对最后一层进行微调等价于:
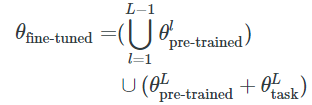
虽然这个工作在NLP中效果不佳(Howard & Ruder, 2018),还有其他一些参数子集可以更有效地进行微调。例如, Ben-Zaken et al. (2020) 仅通过微调模型的偏差参数即可获得有竞争力的性能结果。
另一个工作是在微调期间修剪预训练模型的参数。这类方法用不同的准则对权重进行剪枝,如基于有关权重重要性的零阶或一阶信息(Sanh et al., 2020)。由于当前硬件对稀疏架构的支持有限,方法是结构稀疏的,目前比较好的方法是把更新集中在一组有限的层,矩阵或向量中。例如,已经表明预训练模型的最后几层在微调过程中的用途是有限的,可以随机初始化(Tamkin et al., 2020; Zhang et al., 2021)甚至完全删除(Chung et al., 2021).
剪枝方法着重于减少任务特定模型的参数总数,而其他大多数方法着重于减少可训练参数的数量,同时保持的副本。最近最新的方法普遍与完全微调的性能相当,同时每个任务训练大约0.5%的模型参数 (Pfeiffer et al., 2020; Guo et al., 2020; Ben-Zaken et al., 2020)。越来越多的证据表明,大型的预训练语言模型可以学习很好地压缩NLP任务的表示形式 (Li et al., 2018; Gordon et al., 2020; Aghajanyan et al., 2020)。这些实践证据加上其便利性、可用性(Pfeiffer et al., 2020)以及最近的成功经验,使这些方法在进行实验以及在实际环境中都很有希望。
文本到文本的微调
迁移学习的另一个发展是从掩码语言模型(如BERT (Devlin et al., 2019) 和 RoBERTa (Liu et al., 2019))到自回归语言模型(如T5 (Raffel et al., 2019) 和 GPT-3 (Brown et al., 2020))的转变。虽然这两种方法都可用于为文本分配似然得分 (Salazar et al., 2020),但自回归LM更易于从中进行采样。相反,掩码LMs仅限于完型填空场景(Petroni et al., 2019)。掩码语言模型微调的标准方法是用随机初始化从目标任务学到的基于特定任务header的MLMs替换输出层 (Devlin et al., 2019)。另外,可以通过cloze-style格式将任务重铸为MLM来重用预训练模型的输出层(Talmor et al., 2020; Schick and Schütze, 2021)。类似地,自回归LMs通常以文本到文本格式转换目标任务(McCann et al., 2018; Raffel et al., 2020; Paolini et al., 2021)。在这两种场景下,模型都可以从其所有预先训练的知识中受益,并且无需从头开始学习任何新参数,从而提高了样本效率。
在极端情况下,如果不对参数进行微调,则根据预训练目标来构架目标任务可以用基于特定任务的提示和与任务有关少量任务样本来来进行零样本学习或少样本学习 (Brown et al., 2020)。然而,虽然这种少样本学习是可能的,却并不是使用这类模型的最有效方式(Schick and Schütze, 2020; 看这里做简单了解)。没有更新的学习需要一个巨大的模型,而且该模型需要完全依靠其现有知识。模型可用的信息量也受其上下文窗口的限制,并且模型上显示的提示也需要精心设计。检索增强可用于减轻外部知识的存储量,类似的,符号方法常用于教会模型基于特定任务的规则。预训练模型将变得更大更强,并且在行为上进行微调使其在零样本学习场景下表现出色。但是,如果模型不进行微调,其最终适应新任务的能力将受到限制。
因此,对于大多数实际设置而言,最佳的前进路径无疑是使用前面各节中描述的方法对模型参数的全部或子集进行微调。此外,我们将越来越看到预训练模型的生成能力。虽然当前的方法通常集中于修改模型的自然语言输入(例如通过自动提示设计(Schick and Schütze, 2020; Gao et al., 2020; Shin et al., 2020)),但调节此类模型输出的最有效方法很可能是直接操作其隐层表示(Dathathri et al., 2020; 这篇Lillian Weng's post 概述了可控的生成方法)。
减轻微调的不稳定性
对预训练模型进行微调的一个现实的问题不同的运行之间其性能可能会发生巨大变化,尤其是在小型数据集上(Phang et al., 2018)。Dodge et al., 2020 发现输出层的权重初始化和训练数据的顺序都会导致性能变化。由于不稳定通常出现在早期,大家建议在20-30%的训练后尽早停止最没有希望的训练步。Mosbach et al. (2021) 另外推荐在训练BERT模型时使用较小的学习率与逐渐增加的epochs。许多最新方法试图依靠对抗学习或基于信任区域的方法来减轻微调过程中的不稳定性。这类方法通常用限制更新步之间的差异的正则项来增加微调的损失。
根据上一节的内容,我们可以提出另一个建议,最小化微调过程中的不稳定性:通过将目标任务定为语言模型(LM)形式,避免在目标任务上为小数据集随机初始化输出层或在基于特定任务微调之前,用行为微调方法微调输出层。因此,虽然文本到文本模型对于在小型数据集上进行微调更为健壮,但它们在零样本学习中会不稳定,并对提示和少样本案例非常敏感(Zhao et al., 2021)。
总而言之,随着模型越来越多的用于少训练样本的有挑战性任务,开发对可能的变化具有鲁棒性并且可以可靠地进行微调的方法至关重要。
Citation
For attribution in academic contexts, please cite this work as:
@misc{ruder2021lmfine-tuning,
author = {Ruder, Sebastian},
title = {{Recent Advances in Language Model Fine-tuning}},
year = {2021},
howpublished = {url{http://ruder.io/recent-advances-lm-fine-tuning}},
}