1.ndarray是一个通用的同构数据多维容器,也就是说,其中的所有元素必须是相同类型的。每个数组都有一个shape(一个表示各维度大小的元组),和一个dtype(用于说明数组数据类型的对象)
data.shape()
data.dtype()
精通面向数组的编程和思维方式是称为Python科学计算牛人的一大关键步骤。
2.数组创建函数
array :将输入数据(列表、元组、数组、或其他序列类型)转换为ndarray.要么推断出dtype,要么显示指定其dtype。默认直接复制输入数据
asarray :将输入转换为ndarray,如果输入本身就是一个ndarray就不进行复制
arange :类似于内置的range,但返回的是一个ndarray而不是列表
onesones_like:根据指定的形状和dtype创建一个全1数组.ones_like以另一个数组为参数,并根据其形状和dtype创建一个全1数组
zeroszeros_like:类似以上,只不过产生的全是0
emptyempty_like:创建新数组,只分配内存空间但不填充任何值
eyeidentity:创建一个正方的N*N单位矩阵(对角线为1,其余为0)
3.Numpy的数据类型
类型 类型代码 说明
int8uint8 i1u1 有符号和无符号的8位(1个字节)整型
int16uint16 i2u2 有符号和无符号的16位(2个字节)整型
int32uint32 i4u4 有符号和无符号的32位(4个字节)整型
int64uint64 i8u8 有符号和无符号的64位(8个字节)整型
float16 f2 半精度浮点数
float32 f4f 标准的单精度浮点数.与C的float兼容
float64 f8d 标准的双精度浮点数.与C的double或Python的float对象兼容
float128 f16g 扩展精度浮点数
complex64complex128 c8c16 分别用两个32位64位或128位浮点数表示
complex256 c32 复数
bool ? 存储True和False值得布尔类型
object O Python对象类型
string_ S 固定长度的字符串类型(每个字符1个字节).例如:要创建一个长度10的字符串,应使用s10
unicode_ U 固定长度的unicode类型(字节数由平台决定).跟字符串的定义方式一样(如U10)
import numpy as np #通过ndarray的astype方法显式的转换其dtype: arr=np.array([1,2,3,4,5]) arr.dtype float_arr=arr.astype(np.float64) float_arr.dtype #浮点数转换成整数,小数部分会被截断 arr=np.array([3.7,-1.2,-2.6,0.5,12.9,10.1]) arr arr.astype(np.int32) #字符串数组表示的全是数字,也可以用astype将其转换为数值形式 numeric_strings=np.array(['1.25','-9.6','42'],dtype=np.string) numeric_strings.astype(float) #数组的dtype还有另外一个用法 int_array=np.arange(10) calibers=np.array([.22,.270,.357,.380,.44,.50],dtype=np.float64) int_array.astype(calibers.dtype) #也可以用简洁的类型代码来表示dtype empty_uint32=np.empty(8,dtype='u4') empty_uint32 #astype无论如何会创建出一个新的数组(原始数据的一份拷贝),即使新的dtype跟老的dtype相同也是如此
#数组和标量之间的运算.不用编写循环就可以对数组执行循环,这通常就叫做矢量化
#不同大小的数组之间的运算叫做广播
In [12]: arr=np.array([[1.,2.,3.],[4.,5.,6.]]) In [13]: arr Out[13]: array([[ 1., 2., 3.], [ 4., 5., 6.]]) In [14]: arr*arr Out[14]: array([[ 1., 4., 9.], [ 16., 25., 36.]]) In [15]: 1/arr Out[15]: array([[ 1. , 0.5 , 0.33333333], [ 0.25 , 0.2 , 0.16666667]]) In [16]: arr**0.5 Out[16]: array([[ 1. , 1.41421356, 1.73205081], [ 2. , 2.23606798, 2.44948974]]) In [17]:
基本的索引和切片
In [17]: arr=np.arange(10) In [18]: arr Out[18]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) In [19]: arr[5] Out[19]: 5 In [20]: arr[5:8] Out[20]: array([5, 6, 7]) In [21]: arr[5:8]=12 In [22]: arr Out[22]: array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9]) In [23]: arr_slice=arr[5:8] In [24]: arr_slice[1]=12345 In [25]: arr Out[25]: array([ 0, 1, 2, 3, 4, 12, 12345, 12, 8, 9]) In [26]: arr_slice[:]=64 In [27]: arr Out[27]: array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
#数组跟列表最重要的区别在于.数组切片是原始数组的视图.这意味着数据不会被复制,视图上的任何修改都会直接反应到源数组上
#Numpy设计的目的是处理大数据,所以你可以想想一下,如果坚持将数据复制来复制去的话会产生何等的性能和内存问题
#如果你想要得到一份副本而非视图,arr[5:8].copy()
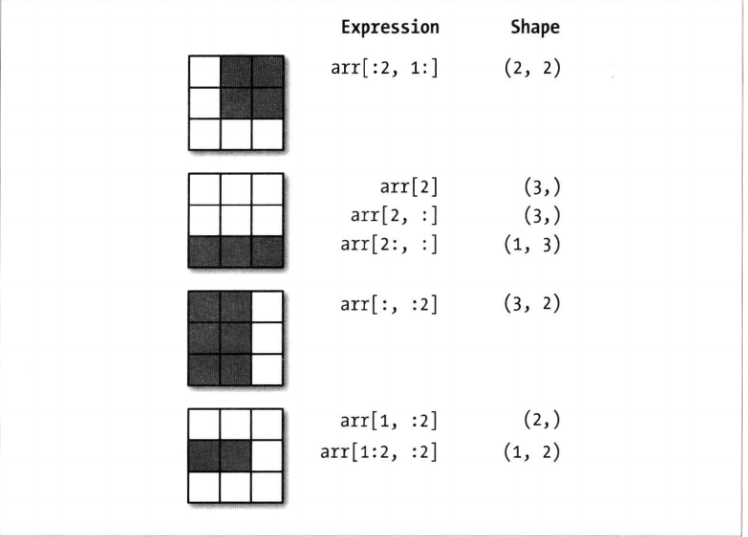
切片+切片:得到相同维度的数组视图
索引+切片:得到低纬度的切片



通过布尔型索引选取数组中数据,将总是创建数据的副本,即使返回一模一样的数组也是如此.
通过布尔型数组设置值是一种常用的手段:
data[data<0]=0
花式索引:指的是利用整数数组进行索引.





花式索引跟切片不一样,它总是将数据复制到新数组中.