哈希的概念:Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
哈希的用途:Hash主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做HASH值. 也可以说,Hash就是找到一种数据内容和数据存放地址之间的映射关系。
哈希表的概念:哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数(哈希函数),存放记录的数组叫做散列表。数组的各个栏叫做槽(buckets或者slots)。
哈希表的模型如下所示:
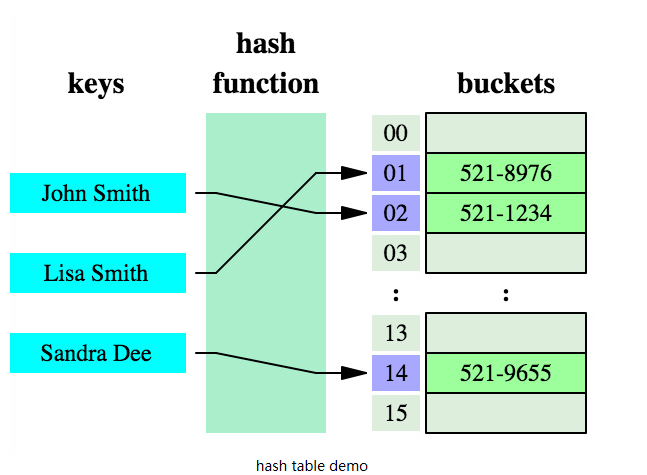
哈希表的过程:key经过hash函数作用后得到一个槽的索引(index),槽中保存着我们想要获取的值(value)。
因为哈希表是基于数组实现的,所以可以实现随机存取,访问速度极快。但是在有的时候可能会发生不同的key经过哈希函数计算后得到同一个槽的索引号的情况(概率很低)。这种情况称为冲突(碰撞)。如果碰撞发生了,采用单纯的数组实现哈希表显然不现实,必须加以解决。对于碰撞的解决方案是采用“拉链法”(open hashing)。
拉链法模型如下:
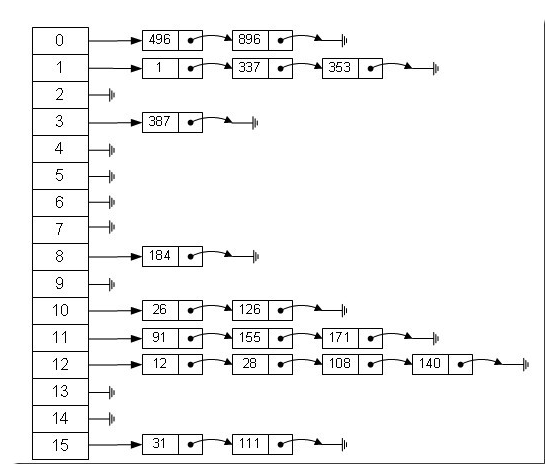
在拉链法模型中:槽,也就是数组的每一栏,存储的不再是value值,而是一个链表的头指针。发生冲突的元素都放在同一张链表中,默认按照插入顺序依次进行链表的头插入。在这种情况下,哈希表就像是一个“链表的数组”。它仍然可以实现快速的访问,同时也解决了冲突。
不过如果冲突发生的非常频繁,那么链表长度会很长。不妨考虑极端的情况,所有元素都集中在一个槽中,那么整个哈希表就变成了一个链表!这种情况下,插入和删除操作效率极低,显然不是我们想看到的,所以一个好的哈希函数必须要求尽量减少冲突发生的概率,也就是要求数据分布尽量均匀。
在哈希表长度一定的情况下,数据分布均匀的目标是通过哈希算法(散列方法)实现的。
散列方法主要有:
1、除法散列法 :公式: index =hashcode % length
但是由于位运算速度远快于求模运算,所以一般使用按位与运算进行求模,公式为:index = hashcode &(length-1)。不过这种方法要求length必须为2的整数次方时,两个公式才相等。因为当length为2的整数次方时,length-1的二进制表示全部为1,所以跟hashcode进行按位与运算可以得到槽索引,范围为[0,length)。
2、平方散列法
求index是非常频繁的操作,而乘法的运算要比除法来得省时,所以我们考虑把除法换成乘法和一个位移操作。公式:
index = (hashcode * hashcode) >> 28 (右移,除以2^28。记法:左移变大,是乘。右移变小,是除)
这种方法如果hashcode值不大的话,其平方值也不会很大,那么其二进制高位几乎全为0。最后经过位移运算的结果肯定为0。那么hashcode不大的情况下,全部得到索引号为0,这种冲突显然不想看到。所以要求hashcode必须足够大。
3、斐波那契(Fibonacci)散列法
平方散列法的缺点是显而易见的,所以我们能不能找出一个理想的乘数,而不是拿hashcode本身当作乘数呢?答案是肯定的。
对于16位整数而言,这个乘数是40503。
对于32位整数而言,这个乘数是2654435769。
对于64位整数而言,这个乘数是11400714819323198485。
这几个“理想乘数”是如何得出来的呢?这跟一个法则有关,叫黄金分割法则,而描述黄金分割法则的最经典表达式无疑就是著名的斐波那契数列,即如此形式的序列:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144,233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946,…。是不是觉得很神奇,可能这就是数学之美吧。
通过采用适当的散列方法,我们可以控制数据尽量均匀地分布在槽中。但是不妨再考虑一个问题:如果一个哈希表被创建了,刚开始所有的槽都是空的。这时候传入一部分数据,数据通过哈希函数应该是可以均匀分布在数组的各个槽中的。偶尔会有小概率的数据发生冲突,被存储在同一个链表中,问题不大。但是随着数据的增多,空槽的数量越来越少,发生冲突的概率越来越大。为了解决这个问题,我们引入了负载因子和再哈希的概念。
再哈希:指的是当槽的利用率(已使用槽与总槽数的比值)达到负载因子时,哈希表会就地扩容,具体过程为调用resize()方法,将哈希表的容量变为原来的两倍。之后对所有的数据重新进行散列过程,存储到相应的位置。
负载因子:再哈希发生的阈值。
要注意的是,再哈希的工作量是很大的,因为要对所有数据进行散列过程。所以,哈希表的长度和负载因子选取要合适。在负载因子一定的情况下,如果长度过小,再哈希就会频繁发生,这会严重影响性能;如果长度设置过大,虽然再哈希发生的频率很低,但是会浪费空间。同理,负载因子如果选取过大,那么在再哈希发生之前,就会产生大量的冲突(因为槽位基本已满);如果负载因子选取过小,那么再哈希就会频繁发生,也会影响性能。一般默认长度为16,负载因子为0.75。
哈希表的应用:java.util.HashMap类就是基于哈希表实现的。当通过HashMap对象查找某个key对应的value值过程为:先将传入的键key通过hashCode()方法得到哈希值hash,再通过哈希函数得到槽的索引号,该索引处存储的是指向某一个链表的引用。继续通过equals方法遍历比较链表上的每一个对象,即可定位到最终的键值对应的Entry对象(键值对)。
所以,HashMap类底层其实就是维护一张哈希表。