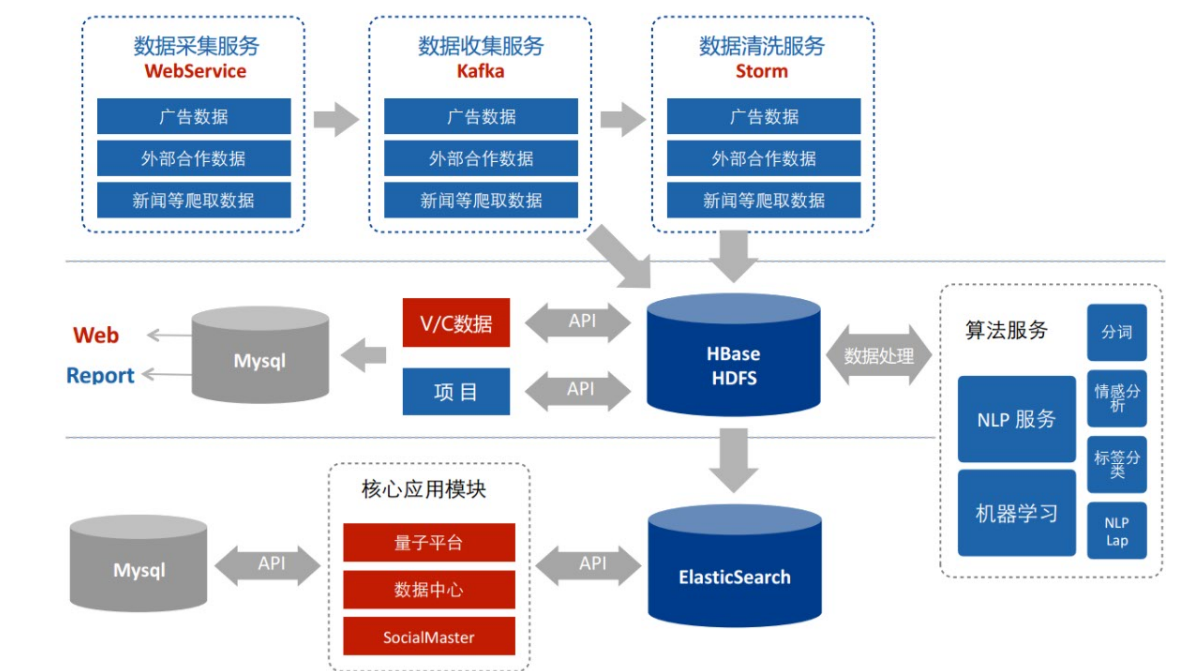
0 基础知识
- 允许你水平分割/扩展你的内容容量
- 允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量
- 至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
- 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
- 扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行
分片策略
选择合适的分片数和副本数。ES的分片分为两种,主分片(Primary Shard)和副本(Replicas)。默认情况下,ES会为每个索引创建5个分片,即使是在单机环境下,这种冗余被称作过度分配(Over Allocation),目前看来这么做完全没有必要,仅在散布文档到分片和处理查询的过程中就增加了更多的复杂性,好在ES的优秀性能掩盖了这一点。假设一个索引由一个分片构成,那么当索引的大小超过单个节点的容量的时候,ES不能将索引分割成多份,因此必须在创建索引的时候就指定好需要的分片数量。此时我们所能做的就是创建一个新的索引,并在初始设定之中指定这个索引拥有更多的分片。反之如果过度分配,就增大了Lucene在合并分片查询结果时的复杂度,从而增大了耗时,所以我们得到了以下结论:我们应该使用最少的分片!主分片,副本和节点最大数之间数量存在以下关系: 节点数<=主分片数(副本数+1)*
副本和分片的关系
- 副本是主分片的一个copy,同时具有分片和副本的索引建立文档时两者都得修改,默认是同步sync更新。es会将所有主分片的变动通知所有副本
- 更多副本意味着查询吞吐量将会增加,因为执行查询可以使用分片或分片的任一副本
- 更多副本会增强集群系统的容错性,因为当原始分片不可用时副本将替代原始分片发挥作用
- 更多分片使索引传送到更多服务器,意味着可以处理更多文件而不降低性能,同时意味着每个分片需要获取的数据量会减少,因为相对于较少分片时,单个分片的文件量更大
- 更多分片意味着搜索时会面临更多问题,因为必须从更多分片中合并结果,查询聚合时需要更多资源
es默认最大返回 10000条数据,修改此配置:
productindex/_settings put
{
"index": {
"max_result_window": 100000
}
}
索引和查询时的路由机制:
默认情况下es会在所有索引分片中均匀地分配文档,es通过计算文档标识符的散列值来决定将文档放置于哪一个主分片上。查询时,首先查询所有节点(整个索引的所有主分片)得到标识符和匹配文档的得分(查询发散阶段)接着在发送一个内部查询,但仅仅发送到相关的分片上,最后获取所需文档构建响应(查询收集阶段)当指定路由值得时候,相同的路由值会生成相同的散列值,这也就保证了相同的路由值文档被分配到相同的分片上。搜索的时候指定路由值(直接在指定分片上执行查询命令),只需要搜索单个分片,而不是整个索引的所有分片。
新建、索引和删除文档
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。 下面我们罗列在主分片和复制分片上成功新建、索引或删除一个文档必要的顺序步骤:
- 客户端给Node 1发送新建、索引或删除请求。
- 节点使用文档的_id确定文档属于分片0。它转发请求到Node 3,分片0位于这个节点上。
- Node 3在主分片上执行请求,如果成功,它转发请求到相应的位于Node 1和Node 2的复制节点上。当所有的复制节点报告成功,Node3报告成功到请求的节点,请求的节点再报告给客户端。
客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片。你的修改生效了。
复制默认的值是sync(同步)。这将导致主分片得到复制分片的成功响应后才返回。如果你设置replication为async,请求在主分片上被执行后就会返回给客户端。它依旧会转发请求给复制节点,但你将不知道复制节点成功与否。上面的这个选项不建议使用。默认的sync复制允许Elasticsearch强制反馈传输。async复制可能会因为在不等待其它分片就绪的情况下发送过多的请求而使Elasticsearch过载。
一 文档类型:
es可以有多个文档类型,每个文档类型中有field名字相同的字段,他们的field类型必须是一致的;因为多个类型在索引中的存储结构是扁平化的,
例如索引index有两个类型,类型1包含了A ,B 两个field, 类型2包含了 B ,C 两个field;他们在索引里的结构是:A,B,C 。相同的field名称共享他们的区域,所以B的类型在两个类型中必须是相同的
每条文档类型的数据里,对方类型的独有字段里都是空值,类似于下面 product和attribute两个类型

1)从技术上讲只要他们的field不是冲突的(无论field相互排斥(相互独立)还是共享field(field相同))都可以在同一个索引中
2)重要的一点是:当你需要区分单个集合的不同部分时使用多类型是很好的
3)类型不适合完全不同类型的数据。如果两个类型有互斥的字段集,这意味着你的索引的一半将包含“空”值(字段将是稀疏的),这将最终导致性能问题。
在这些情况下,我们需要根据下面两个指标来判别:
-
Good:
kitchenandlawn-caretypes inside theproductsindex, because the two types are essentially the same schema -
Bad:
productsandlogstypes inside thedataindex, because the two types are mutually exclusive. Separate these into their own indices
二 应该采用何种Mapping数据结构
es索引数据是类似于nosql数据库的存储方式,索引是独立文档文档的扁平的集合,一个文档应该包含所有用于搜索的信息;每个文档都是独立于其他节点的;
但是我们是无法避免索引之间存在关联关系的情况,我们需要一种方式来建立文档之间的关系而解决现实世界中的业务联系问题;一共有四种方式:
1)在一个类型的文档中加入另外一个文档的标识符(模拟关系型数据库)
PUT /my_index/user/1 { "name": "John Smith", "email": "john@smith.com", "dob": "1970/10/24" } PUT /my_index/blogpost/2 { "title": "Relationships", "body": "It's complicated...", "user": 1 }
在帖子对的文档类型里面加入用户的id,证明这个帖子是这个用户发的
这样的话在搜索的时候我们要运行两次查询,例如我要搜索第一个名字叫john的用户发的帖子:首先你要先查出第一个名字叫john的所有id,然后根据user的id再去博客类型索引里查博客信息
GET /my_index/user/_search { "query": { "match": { "name": "John" } } } GET /my_index/blogpost/_search { "query": { "filtered": { "filter": { "terms": { "user": [1,2] } } } } }
优点是:文档数据都是独立的,增删改查都是针对同一个文档类型
缺点是:我们要运行额外的查询,特别是当第一次查询返回数据多时,第二次将面临成千上万的查询;所以如果我们能保证第一次查询返回的数据极小时,且不经常发生改变(意味着可以缓存)的情况下使用这种方式是很好的
2)通过非规范化数据(数据冗余)可以为搜索带来很好的性能
PUT /my_index/user/1 { "name": "John Smith", "email": "john@smith.com", "dob": "1970/10/24" } PUT /my_index/blogpost/2 { "title": "Relationships", "body": "It's complicated...", "user": { "id": 1, "name": "John Smith" } }
博客类型的索引里冗余了作者的信息,此时去搜索某个用户发的帖子只需要查询博客类型索引就可以了
GET /my_index/blogpost/_search { "query": { "bool": { "must": [ { "match": { "title": "relationships" }}, { "match": { "user.name": "John" }} ] } } }
这样子查询将会很快,因为文档中包含了额外的信息所以省略了链接的消耗
3)嵌套
文档对象嵌套,例如帖子和评论,一个帖子可以有很多评论;那么我们可以创建一个帖子文档,里面包含了评论的嵌套的模型;
一个主文档链接多个附属文档,主文档和附属文档一同被索引并被放置在同一个块上确保为该数据结果获取最佳性能;修改时你需要同时索引主文档和附属文档
由于嵌套文档的存储方式,我们的查询还是很快的,就像他们是同一个文档一样


{
"block": {
"properties": {
"name": {
"type": "string",
"index": "analyzed"
},
"comment": {
"type": "nested",
"properties": {
"content": {
"type": "string",
"index": "analyzed"
}
}
}
}
}
}
//在索引里的存储格式类似:
{ //附属文档
"comments.name": [ john, smith ],
"comments.comment": [ article, great ],
"comments.age": [ 28 ],
"comments.stars": [ 4 ],
"comments.date": [ 2014-09-01 ]
}
{ //附属文档
"comments.name": [ alice, white ],
"comments.comment": [ like, more, please, this ],
"comments.age": [ 31 ],
"comments.stars": [ 5 ],
"comments.date": [ 2014-10-22 ]
}
{ //主文档
"title": [ eggs, nest ],
"body": [ making, money, work, your ],
"tags": [ cash, shares ]
}
这些额外的嵌套附属文档是隐藏的,我们不能直接访问它们。更新,添加或删除一个嵌套的对象,我们必须重建整个文件;索请求返回的结果不是嵌套的对象,它是整个文档
4)父子
父子关系允许两个文档类型进行关联,亲子关系在性质上是相似的嵌套模型:都允许你将一个实体与另一个。不同的是,用嵌套的对象,所有的实体都在同一个文档内,而与父母和孩子是完全独立的文件。
相对嵌套的优点:
1 父和子的更新都可以在互不影响的情况下进行。
2 当更新频繁的时候比嵌套要好
3 可以独立返回父或子的搜索结果而不是整个文档
缺点:
1) 父和子要在同一个分片中,当插入文档指定了路由分片时,要注意这个问题
2) 比起查询单独的文档,父子关联查询相对会慢
3) 执行父子查询时,es会加载并缓存文档标识符到内存,必须确保es有足够的内存,不然会导致内存溢出
4)es会维护一个父子关系的map,所以查询速度非常快(可能3中加载文档标识符与此相关)