//1 从内存中创建makeRdd,底层实现就是parallelize
val rdd=sc.makeRDD(Array(1,2,"df",55))
//2 从中创建parallelize
val paraRdd=sc.parallelize(Array(1,2,3,54,5))
//3 从外部存储中创建
// 默认情况下,可以读取项目路劲,也可以读取其他路劲如hdfs
// 默认从文件中读取数据都是字符串类型
// 读取文件时,传递的分区参数为最小分区数,但不一定是这个分区数,取决与hadoop读取文件时的分片规则
val fileRdd=sc.textFile("path",2)
mapParitions的优缺点:
mapParitions可以对一个RDD中所有的分区进行遍历
mappartitions.效率优于map算子,减少了发送到执行器执行交互次数
mappartitions内存溢出是当一个分区数据过大,发送时执行的exctuer可能放不下,出现OOM
mapPartitionsWithIndex:
val listRdd = sc.makeRDD(1 to 10,2)
val indexRdd = listRdd.mapPartitionsWithIndex({
case (num, datas) => {
datas.map((_, "分区号:" + num))
}
})
indexRdd.foreach(println(_))
/**
*
* (6,分区号:1)
(1,分区号:0)
(7,分区号:1)
(2,分区号:0)
(8,分区号:1)
(3,分区号:0)
(9,分区号:1)
(10,分区号:1)
(4,分区号:0)
(5,分区号:0)
*/
driver和excuter:
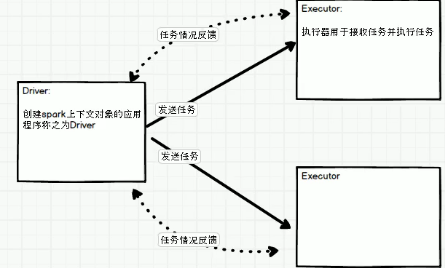
代码分布:
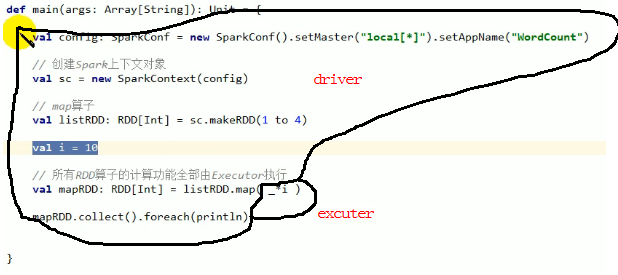
上述代码执行没有问题,i可序列化。执行时会将i传输到excuter上,传输就牵扯io,就需要序列化。所以需要传输的内容必须能够序列化,否则就会报错。
val rdd3 = sc.makeRDD(List(1, 32, 3, 4, 5))
rdd3.foreach({
case i => {
println(i * 2) //Executor
}
})
rdd3.collect().foreach({
case i => {
println(i * 2) //Driver,collect后是一个数组,相当与把数据拿到driver中进行计算
}
})
glom将同一个分区的数据放到一个数组中
val rdd1 = sc.makeRDD(1 to 10,3)
val glomRddArr:RDD[Array[Int]] = rdd1.glom()
glomRddArr.foreach(arr=>{
val str = arr.mkString(",")
println(str)
})
/**
* 4,5,6
1,2,3
7,8,9,10
*/
shuffle操作
//将rdd中一个分区的数据打乱重组到其他不同分区的操作称为shuffle,如distinct
//rdd的操作牵扯到shuffle的算子效率就会降低。
val rdd2 = sc.makeRDD(1 to 10, 5)
//可以设置是否shuffle,默认是不shuffle。
// repairtition实际上默认是shuffle,底层是coalesce coalesce(num,shuffle=ture)
val coaRdd = rdd2.coalesce(2)